






 ResNet通过引入残差学习框架,解决了深层神经网络的退化问题,实现了网络深度与性能的正相关。文章详细介绍了ResNet的设计动机、核心贡献、具体实现方法及在不同数据集上的实验验证。
ResNet通过引入残差学习框架,解决了深层神经网络的退化问题,实现了网络深度与性能的正相关。文章详细介绍了ResNet的设计动机、核心贡献、具体实现方法及在不同数据集上的实验验证。
论文名称:Deep Residual Learning for Image Recognition
作者:Kaiming He \ Xiangyu Zhang\ Shaoqing Ren\ Jian Sun
论文地址:http://openaccess.thecvf.com/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf
发表年份:CVPR 2016
Deep Residual Learning for Image Recognition发表在CVPR2016,当年的best paper,其残差思想一度统治视觉识别领域,把神经网络的有效深度扩展了一个数量级,基于Resnet的视觉模型一举拿下当年几乎所有的视觉识别类冠军!
1 动机
对于传统深度神经网络来说,随着网络的加深,训练难度会越来越大,性能也不会持续上升,而是呈现饱和状态,并且再加深会出现性能下降的情况,也就是所谓的模型退化问题(degradation problem)。如下图所示,在经历同样的训练过程后,20层明显优于56层的网络性能。

2 贡献
- 本文作者提出一种新的学习框架,这种框架中,网络每一个Block(可以包含多个层)学习的实际上是本层输入与输出的差值,所以称为残差学习(Residual learning)。
- 提出“瓶颈”块(“bottleneck” )
- 由Residual learning和“bottleneck”构建出__Resnet__
- Resnet 能简单有效的解决退化问题(degradation problem),实现 网络性能与其深度满足正相关关系 的目的。
- Resnet 易于收敛,且推广性极强,甚至可直接用于传统深度神经网络(如Inception等)
3 方法
3.1 Residual learning

通过在一个浅层网络的基础上叠加y=x (称作identity mapping,恒等映射)的层,可以让网络随深度增加而不退化,却也永远无法超越一开始的浅层网络,这说明多层非线性网络无法逼近恒等映射网络或者说现有的训练手段直接用在多层恒等映射上是有问题的。
然而我们增加了计算量,想要的是更好的性能。相比于原来的简单堆叠网络层以及刚才的恒等映射,我们需要的是更好的映射,不仅可以保证模型不退化,而且可以提升性能。

作者提出了自己的见解,假设,我们期望的映射是H(x),但是网络层能完成的映射是F(x),那么就通过恒等映射y=x给网络层加把劲,即H(x)=F(x)+x。作者把F(x)=H(x)-x称为残差映射,认为相比于直接让网络完成H(x),残差映射F(x)更容易学习。比如,在一个极端情况下,H(x)趋近于x,那么让F(x)=0比让传统的F(x)=x要简单的多,后者要做更精细的权重调节。
作者通过添加一个shortcut connection实现上述残差映射,公式如下:

公式(1)的+是对应元素的相加,这就要求F和x的维度是完全相同的,然而在某些情况下,F和x的维度可能会有偏差,针对这种情况,作者又提出了公式(2),取名projection shortcuts。

3.2 网络架构
针对ImageNet


这里注意,Fig3&Fig4中每一个conv都代表着conv+bn+relu
Bottleneck building block

作者巧妙地利用conv1x1随意更改通道数的特点提出了`bottleneck building block`,替代原来的 `residual learning building block`。在提升速度的情况下,提升了网络性能!!! 在“bottleneck”中先用conv1x1降低通道数,然后conv3x3正常卷积,然后利用conv1x1提升通道数。图5中所示的左右结构的时间复杂度是接近的,并且右边略小于左边! 另外,如果使用“bottleneck”结构,那么“shortcut”应该使用公式(1)实现,因为公式(2)会导致模型体积翻倍。 Fig4中的Resnet50就是通过“bottleneck”替换的方式从Resnet34演变而来的。
3.3 实现细节
本文针对ImageNet的实现同AlexNet和VGG使用采取同样的措施。
数据增强
- 在保持图片宽高比的前提下把图片短的一个边缩放到[256,480] ,称为尺度增强;
- 在上一步基础上水平翻转图像;
- 在上一步生成的图像上随机裁剪出224x224的图像块;
- 每个图像减掉ImageNet中图像的平均值,以减少训练时的计算量,同时还有助于提升模型性能;
- 使用标准颜色增强
- 在整个ImageNet上做图像RGB通道上的PCA
- 对训练集的每张RGB图片都加上下面的一个值,其中
p和λ是PCA中3x3的协方差矩阵的特征向量和特征值,α是从一个均值为0标准差为0.1的高斯分布中提取出的随机向量。 - Alexnet中提到,使用这种颜色增强后是最终分类误差降低1%

训练参数
- 权重初始化使用Delving Deep into Rectifiers中提出的初始化方法(其中的n代表输入的数量,比如y=w’x,其中x是h-w-c那么n=h*w*c),从0开始训练
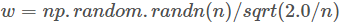
- 优化器:SGD(Stochastic Gradient Descent,随机梯度下降)
- 学习率 初始0.1,当train loss恒定时减小到原来的1/10
- 权重衰减因子1e-4
- 动量 0.9
- 迭代次数60w次
- 使用BN,不使用Dropout
测试方法
- 标准
10-crop testing- 截取原图四个角和中心的224x224的图像,得到5张子图
- 把原图水平翻转之后,做同样的操作,又得到5张子图
- 一共裁剪得到5+5=10张子图,这就是
10-crop - 分别对10张子图做预测,最终结果取平均值
4 实验
4.1 验证residual learning
使用同样的训练方法,分别对plain-18,plain-34,resnet-18,resnet34进行训练。

Fig4的结果表明,在传统网络上引入残差块可以实现 网络深度与性能正相关 的目的,在18和34层的这个数量级上解决了模型退化问题(degradation problem)。
Table2中,纵向看是直接证明了Fig4中的现象,横向看,同样深度情况下,Resnet的性能更优,并且层数越深,Resnet的优势越明显。
4.2 验证projection shortcuts
在整个网络上,对于residual mapping的实现有以下三种配置:
- A:统统使用公式(1),F(x)与x维度有偏差的地方直接补0
- B:维度相同情况下使用公式(1),有偏差的地方使用公式(2) projection shortcuts
- C:统统使用公式(2)

结果表明,B配置要明显优于A配置,C配置稍微优于B配置,但是B相对于A仅仅增加了极少量的参数和计算量,但是C相对B模型参数和计算量会增加太多,所以权衡性能与计算量,B是最佳实现方式!
4.3 验证 Bottleneck

注:Resnet50使用配置B
结果证明,Bottleneck对网络性能提升较大!而且前提是Bottleneck已经提升了网络的计算速度!
4.4 resnet VS other-net



其中Table5是ImageNet官方公布的测试效果,说服力更强。
上述网络结构和实验都是针对ImageNet数据集的!
4.5 针对CIFAR-10数据集的实验细节
网络结构

实现细节
- 训练参数
-batch size 128
-学习率初始0.1,迭代32k(epoch≈10)和48k(epoch≈15)后各自缩减10倍,64k(epoch≈20)后结束训练。
-其余参数与ImageNet相同 - 数据增强
- 对32x32的原图的每个边补上4个像素,然后再裁剪出来32x32的子图
结果

Fig6的左图和中图与Fig4所示现象相同。右图里的Resnet-1202的训练方式与Resnet-101等一致,也很容易收敛,最终也达到了比较好的测试效果,更进一步说明了残差块可以有效解决模型退化问题(degradation problem)。
但是同时可以发现,Resnet-1202的测试效果并不如Resnet-101,作者猜是因为过拟合(overfitting),可以使用Dropout/Maxout解决,先搁置,以后再研究(we will study in the future)。


4.6 Resnet用于目标检测
使用Resnet-101替换掉Faster RCNN里的VGG-16,网络结构示意图如下:

细节
- Resnet是在ImageNet上预训练过的
- 使用conv5_x代替原来Faster中的fc层,它的结果直接输入到“cls”/“bbox regression”分支。
- 训练检测器时,Resnet中的BN层不再参与学习,使用预训练时得到的平均值和方差。
- 其他超参数的设置与原Faster中一致。

5 思考
1.残差块推导时,我们想要的映射是H(x),而作者给出的一种实现方式是通过F(x)+x实现,并且推导时假定这样是有效的,然后通过实验验证,这样确实有效。既然可以通过F(x)+x逼近H(x),那么是否存在其他方式更好的逼近H(x)呢?
2.文中Fig7从上图到下图是如何产生的,Fig7中这种比对意义是什么?
3.文中Fig3中的FLOPs是如何计算的?

















 1754
1754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









