 ADPretrain:工业异常检测预训练新范式
ADPretrain:工业异常检测预训练新范式





本文来源公众号“极市平台”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/81jO44N9eHAbfA91oYEYLw
极市导读
ADPretrain 首次为工业异常检测定制预训练:用残差特征剥离类别信息,再以角度-范数双对比损失把正常/异常彻底拉开,无需改动网络即可让 PatchCore、UniAD 等 AUROC 平均暴涨 20+ 个百分点。
大家好,今天想和大家聊一篇非常有趣的新工作,来自上海交通大学和南京农业大学的研究者们,他们提出了一个名为 ADPretrain 的新框架。简单来说,这是一个专门为工业异常检测(Industrial Anomaly Detection)任务设计的“预训练”方法,旨在解决现有方法过度依赖ImageNet预训练特征而导致的“水土不服”问题。

-
论文标题: ADPretrain: Advancing Industrial Anomaly Detection via Anomaly Representation Pretraining
-
作者: Xincheng Yao, Yan Luo, Zefeng Qian, Chongyang Zhang
-
机构: 上海交通大学,南京农业大学
-
论文地址: https://arxiv.org/abs/2511.05245
-
项目地址: https://github.com/xcyao00/ADPretrain
-
会议: Accepted by NeurIPS 2025
01 现有方法的“窘境”
在工业生产线上,利用机器视觉来检测产品瑕疵(即“异常”)是一项关键技术。目前,主流的异常检测(AD)方法大多依赖于在ImageNet上预训练好的深度学习模型来提取特征。但这里存在两个核心问题:
-
目标不匹配:ImageNet预训练的目标是“分类”,让模型学会识别猫、狗、汽车等自然物体,而不是区分“正常”与“异常”的工业品。
-
数据分布差异:工业图像(比如电路板、药瓶、金属螺丝)和ImageNet中的自然图像在纹理、光照、背景等方面差异巨大。
这两个问题导致ImageNet预训练出的特征对于工业异常检测任务来说,并非最优解,甚至可能限制了模型的性能上限。
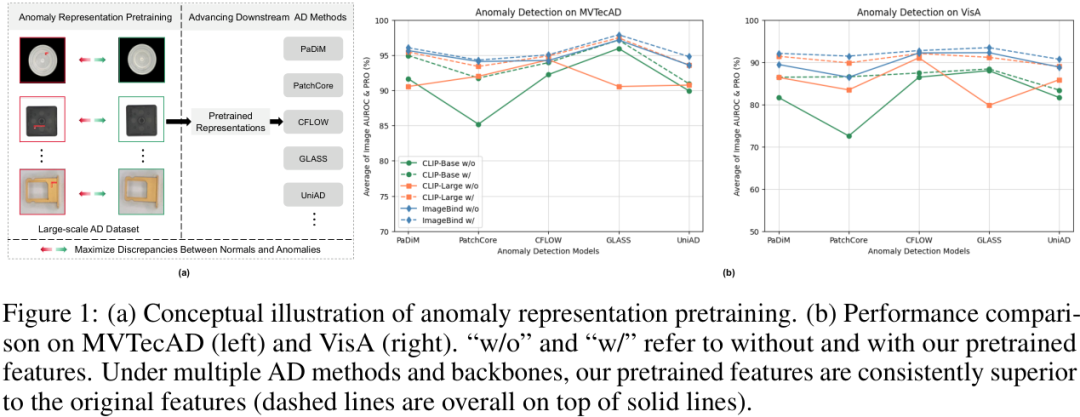
从上图可以直观地看到,无论是在MVTecAD还是VisA数据集上,使用了ADPretrain的预训练特征后(虚线),多种异常检测方法的性能都普遍优于使用原始特征(实线),证明了其普适性和有效性。
02 ADPretrain:为异常检测而生的预训练框架
为了解决上述痛点,作者们提出了一个全新的异常表示预训练框架——ADPretrain。其核心思想是:在一个大规模的工业异常检测数据集(RealIAD)上,专门学习一种能够更好地区分正常与异常样本的特征表示。
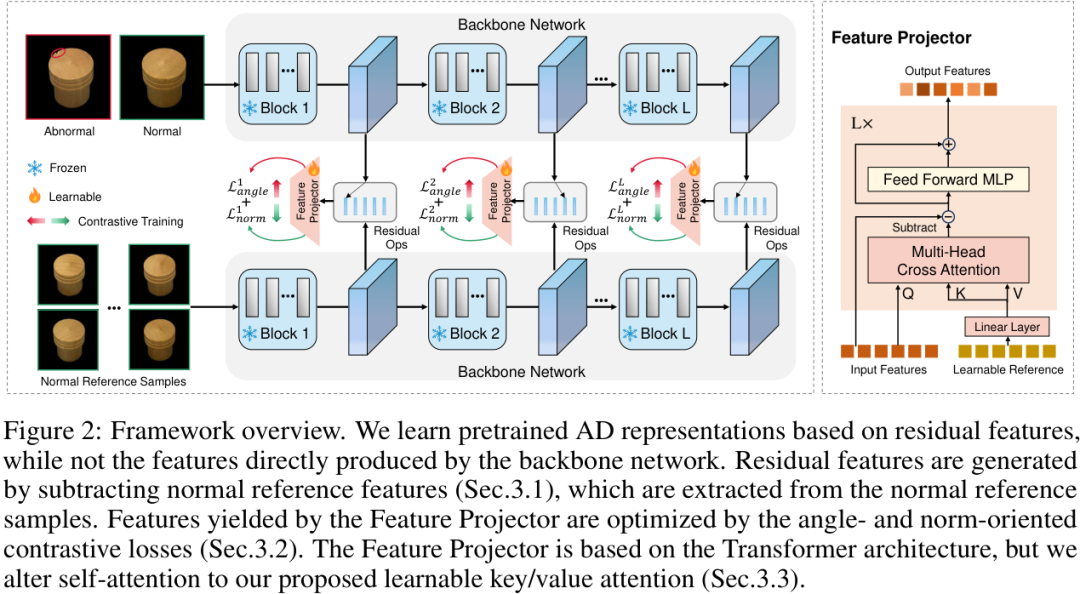
整个框架如上图所示,它主要包含几个关键设计:
03 基于残差特征的表示学习
为了让预训练的特征具有更好的泛化能力,能够适应不同的下游数据集,ADPretrain没有直接使用骨干网络输出的特征。而是借鉴了ResAD的思想,采用了一种名为“残差特征”(Residual Features)的表示。
具体来说,对于一个输入特征,模型会从一个“正常样本特征库”中找到与之最相似的正常特征,然后将两者相减,得到残差特征。这种操作可以有效地剥离掉与类别相关的通用模式,让模型更专注于那些“不正常”的微小差异,从而获得更好的跨类别泛化能力。
04 创新的对比损失函数
为了让模型学到的特征更具判别力,作者设计了两种互补的对比损失函数(Contrastive Losses),分别从“角度”和“范数(模长)”两个维度来拉大正常特征与异常特征之间的距离。
角度导向对比损失 (Angle-Oriented Contrastive Loss)

4.1 可学习键/值注意力的特征投影器
在获得残差特征后,作者设计了一个基于Transformer的特征投影器(Feature Projector)来进一步优化和提炼特征。有趣的是,他们没有使用标准的自注意力机制,而是提出了一种名为“可学习键/值注意力”(Learnable Key/Value Attention)的模块。
该模块引入了一组可学习的“参考表示”作为Key和Value,而输入特征作为Query。通过Query与这些可学习的正常模式参考进行交叉注意力计算,再从输入中减去注意力输出,可以自适应地消除特征中可能残留的正常模式,从而进一步凸显异常。
05 实验效果:显著且普适的性能提升
为了验证ADPretrain的威力,作者进行了一系列详尽的实验。他们将ADPretrain学到的特征直接替换掉五种主流的基于嵌入的异常检测方法(如PaDiM、PatchCore等)中的原始特征,并在五个公开数据集(MVTecAD, VisA, BTAD等)和五种不同的骨干网络(如DINOv2, CLIP等)上进行了测试。
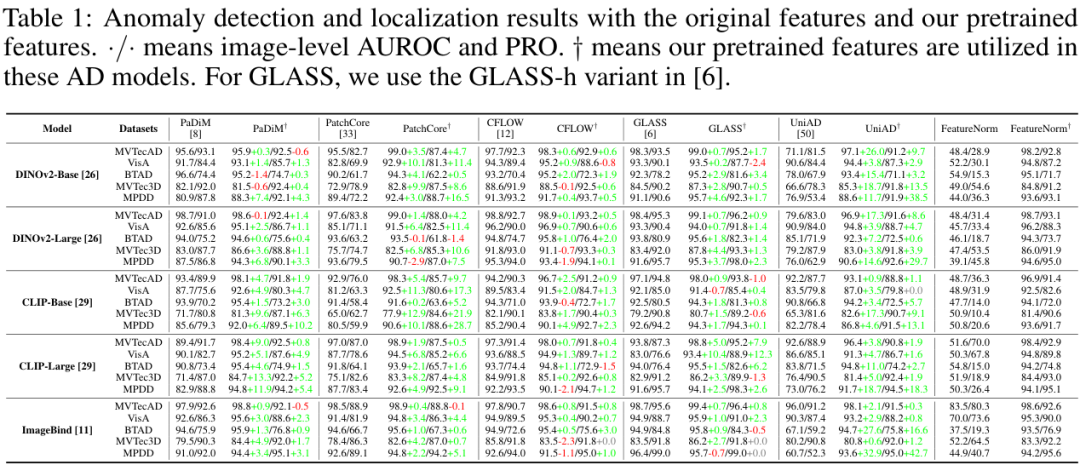
实验结果非常亮眼。如上表所示,几乎在所有组合下,使用ADPretrain的特征(标记为†)都带来了显著的性能提升。例如,在DINOv2-Base骨干网络和MVTecAD数据集上,PatchCore的图像级AUROC从95.5%**提升到了99.0%**;UniAD更是从71.1%**飙升至97.1%**,提升了惊人的26个百分点。这充分证明了ADPretrain学习到的特征表示具有极强的泛化性和优越性。
5.1 直观的可视化对比
通过t-SNE对特征进行降维可视化,我们可以更直观地感受到ADPretrain带来的改变。

上图展示了VisA数据集中“capsules”类别的特征分布。左边是原始特征,正常(绿色)和异常(红色)样本混杂在一起,难以区分。而右边使用了ADPretrain的特征后,绿色点簇变得异常紧凑,红色点则被清晰地分离出来,界限分明。
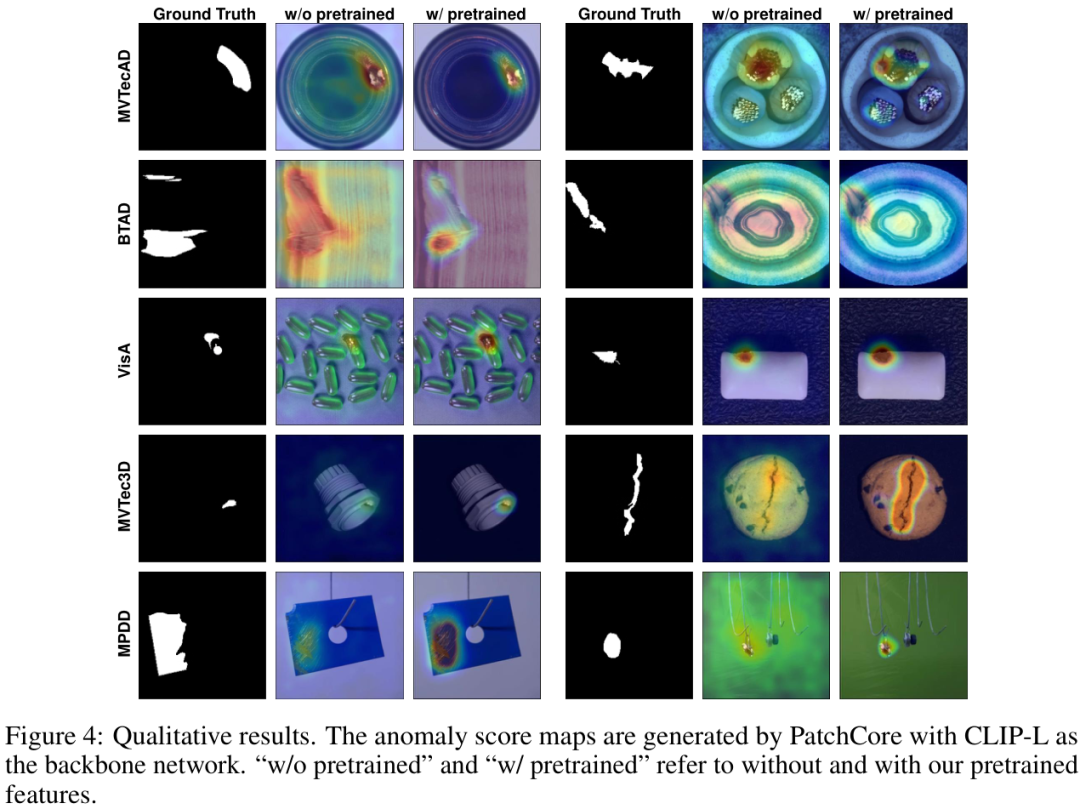
同样,在定性结果上,使用ADPretrain特征的模型能够更准确地定位异常区域,同时有效抑制在正常区域的误报。
06 总结
总的来说,这篇论文点出了当前工业异常检测领域一个长期被忽视但至关重要的问题:预训练任务与下游应用之间的鸿沟。作者提出的ADPretrain框架,通过在大规模行业数据集上进行专门的表示学习,并设计了巧妙的对比损失来强化正常与异常的区分,为该领域提供了一种即插即用、效果显著的“能力升级”方案。这项工作不仅为工业异常检测带来了新的SOTA性能,也为未来研究指明了一个有价值的方向——为特定任务定制预训练。
大家对这个方法怎么看?你觉得为特定领域定制预训练会成为未来的大趋势吗?欢迎在评论区留下你的看法!
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









