




本文来源公众号“码科智能”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/0-aJNZPFuPh66I_ZY1a1dg
让大模型学会用图像块说话
大多数 MLLMs 在做目标检测、指代分割这类任务时,采用的还是老办法,把边界框坐标 [x1,y1,x2,y2] 当作文本序列输出。
这种方式看似直观,实则问题重重(如下图),基于回归坐标出现问题的本质,是文本模态与视觉模态之间的深层未对齐。
-
格式混乱:即使在相同的提示下,不同样本的输出格式也常常不一致,从而增加了解析和结构化输出的难度;
-
语义断裂:坐标是数值,与图像块之间缺乏直接语义关联,模态错位;
-
幻觉频发:模型容易生成“图中没有的框”或重复预测同一物体。

边界框坐标表示的三大痛点
尽管像上篇文章介绍到的 Rex-Omni 这样的工作尝试通过自回归地生成一系列坐标点预测来提升定位精度,但其本质仍是用文字描述像素,难以从根本上解决语义割裂问题。
今天要介绍的这项来自华南理工大学、腾讯微信视觉、南洋理工大学等机构的联合研究——PaDT(Patch-as-Decodable Token),抛弃了目标检测坐标的表达形式,采用图像块即 Token 的新范式。
一、基于 MLLM 的检测方案
当前主流的 MLLM 视觉感知模型,视觉编码器对固定块网格的依赖会模糊局部细节,并损害诸如目标定位、计数或 OCR 等任务。
文本化坐标输出:如Qwen-VL、Rex-Omni等模型,将边界框编码为文本序列,由 LLM 自回归生成。但它们的致命弱点是回归数值被拆分成多个离散 token,破坏连续性,且缺乏与图像局部区域的显式绑定,易产生幻觉。
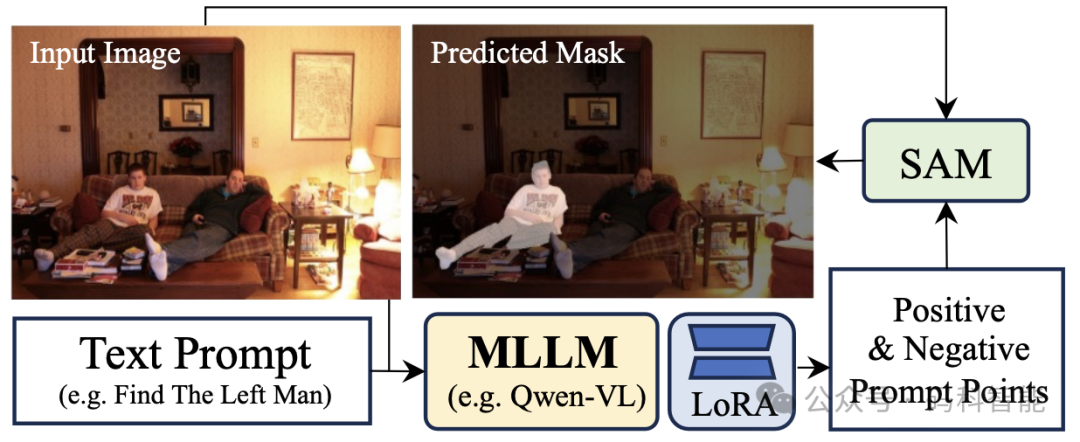
拼接式架构:如 LISA、Seg-R1 等模型,先用 SAM 分割出候选区域,再交给 MLLM 匹配语义。这种两段式设计虽能提升分割质量,但严重依赖外部模型部署复杂,且无法实现真正的端到端训练。
# 项目
Patch-as-Decodable-Token: Towards Unified Multi-Modal Vision Tasks in MLLMs
# 论文
https://arxiv.org/pdf/2510.01954
# 代码
https://github.com/Gorilla-Lab-SCUT/PaDT
# 项目
https://https://huggingface.co/collections/PaDT-MLLM/padt-dataset-68e400440ffb8c8f95e5ee20
二、PaDT 核心技术革新
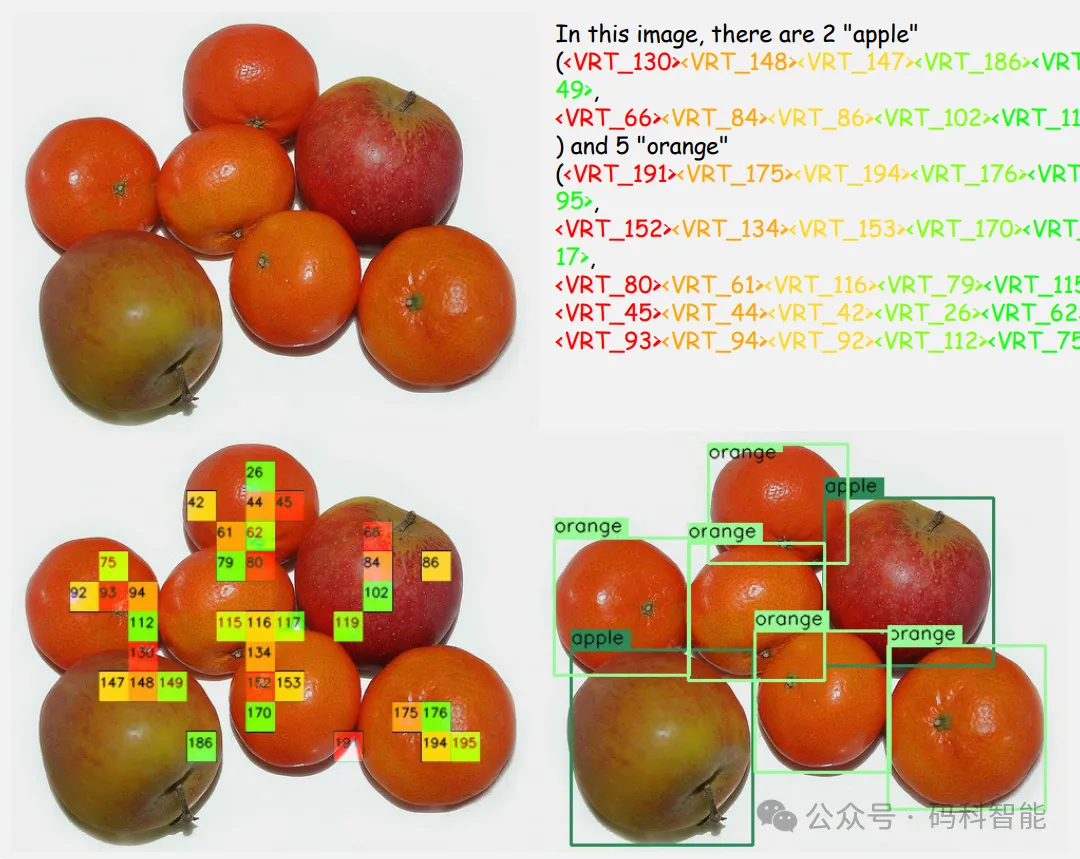
PaDT 的核心思想是:让大模型学会“用图像块说话”,它引入了一种新型令牌:视觉参考令牌(VRT),彻底打通文本与视觉的语义鸿沟,从而避免了“幻觉框”和错位问题。
视觉参考令牌的生成过程如下:
-
图像被切分为 N 个 patch,每个 patch 经过视觉编码器得到嵌入向量;
-
这些嵌入向量作为“候选视觉词”,构成一个动态嵌入表;
-
在推理时,LLM 不再输出坐标,而是输出一组 VRT,如
<VRT_130>、<VRT_148>,这些 VRT 明确指向图像中的特定区域,天然具备空间语义。

与以往使用全局码本的方法不同,PaDT 的 VRT 是动态生成、随图像变化的,每次前向传播独立构建 VRT 空间。也就是每张图都有自己专属的视觉词汇表,不同图像间的 VRT 互不干扰,泛化能力强。
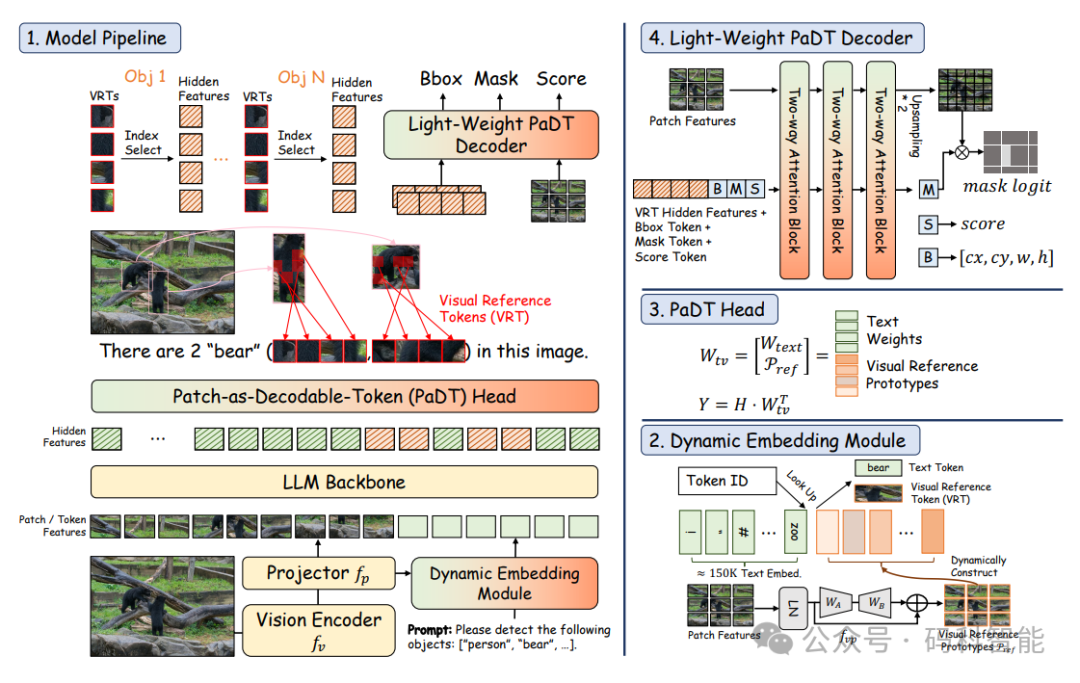
PaDT 设计了一个极简的轻量级解码器,能够将 VRT 集合转换为边界框(通过最小外接矩形聚合多个 VRT)、分割掩码(对选中的 patch 进行上采样填充)、关键点/布局(直接输出高响应区域),从而实现解码统一并支持多种视觉输出。
PaDT 在广泛的视觉感知与理解任务上实现了最先进的性能,即使与规模大得多的 MLLM 模型相比也是如此,在指代表达理解任务上,平均准确率高达 93.6%。其有效性不仅在感知任务上得到验证,也在定制的图像描述任务上得到验证。

PaDT 重新定义了 MLLM 与视觉世界的交互方式,模型只需“说”出哪些块属于目标,解码器就能精准还原掩码或边界框。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 17万+
17万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









