 STiL:首个图像-表格半监督框架
STiL:首个图像-表格半监督框架





本文来源公众号“数据派THU”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/J5nqqWEUdkVYhXDuk7UGBg
本文提出了一个新颖的半监督图像-表格框架 STiL,旨在全面挖掘任务相关信息,弥合这一缺口。
STiL: Semi-supervised Tabular-Image Learning for Comprehensive Task-Relevant Information Exploration in Multimodal Classification
作者
Siyi Du, Xinzhe Luo, Declan P. O'Regan, Chen Qin
作者单位
帝国理工大学 (Imperial College London)
论文链接
http://arxiv.org/abs/2503.06277
代码链接
https://github.com/siyi-wind/STiL
简介
多模态图像-表格学习正迅速吸引学术界的关注,尤其是在数据标注稀缺的情况下。然而,尽管已有研究通过自监督学习(SSL)尝试利用未标注数据,因其任务无关的特性,往往学到的特征并不适合特定任务。半监督学习(SemiSL)通过结合有标注和无标注数据提供了一个解决方案,但目前的多模态半监督学习方法多集中在单模态或模态共享特征的建模,忽视了模态特有的任务相关信息,从而导致“模态信息缺口”(Modality Information Gap)问题。
本文提出了一个新颖的半监督图像-表格框架 STiL,旨在全面挖掘任务相关信息,弥合这一缺口。STiL 引入了创新的“解耦对比一致性模块”(DCC),通过解耦机制学习跨模态共享信息的不变表示,同时保留模态特有信息。此外,STiL 提出了“共识引导伪标签策略”(CGPL)和“原型引导标签平滑技术”(PGLS),有效提升了伪标签的质量,从而在未标注数据中更好地学习与任务相关的信息。
在自然图像和医学图像等多个数据集上的实验表明,STiL 相较于现有的多模态方法,显著提高了任务的性能。
背景介绍
近年来,多模态深度学习通过整合来自不同模态的信息,取得了显著进展,尤其是在图像-表格联合学习方向。此类方法将图像和结构化表格数据相结合,已经在医学影像、市场营销等领域展现出巨大的潜力。例如,医学影像与表格数据(如化验结果、病史信息)结合使用,能够提高诊断的准确性,模拟临床医生在实际就诊中对患者的综合评估过程。
然而,这些方法通常依赖大量高质量的标注数据,而现实中标注数据的缺乏,尤其是在罕见疾病分类等任务中,成为了推广和应用的瓶颈。
当前,在图像-表格任务中,有些研究尝试引入自监督学习(SSL)来利用未标注数据,通过预训练提高特征表示能力 (图1 (a))。然而,SSL 依然存在两个核心问题:
-
任务无关性:SSL本质上是任务不可知(task-agnostic)的,仅捕捉通用表示,未必适应具体任务;
-
微调阶段过拟合:在标注数据极少时,模型易在微调阶段过拟合,影响泛化能力。
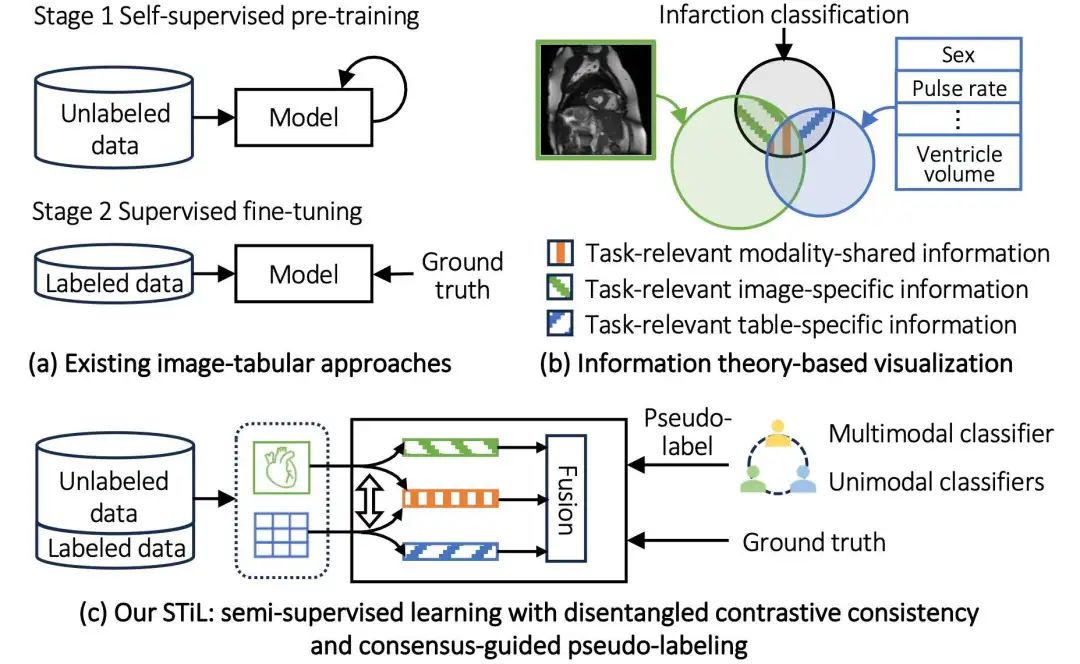
图1: (a)现有图像-表格模型中对未标注数据的典型使用方式;(b)“模态信息缺口”示意图:任务相关信息同时存在于模态共享特征与模态特有特征中;(c)STiL 框架:针对该缺口设计,能从有标注与无标注数据中有效提取任务相关信息。
相比之下,半监督学习(SemiSL)结合有标注与无标注数据进行任务建模,能更好地提升泛化能力。尽管如此,图像-表格任务中的多模态半监督学习尚未得到系统性研究。
现有多模态/多视角的半监督研究主要集中在两个策略:
-
跨模态一致性约束(Cross-Modal Consistency):假设任务相关信息主要存在于多个模态的交集中,通过引入对比学习等手段,学习模态共享的表示。
-
协同伪标签(Co-Pseudo-Labeling):假设单一模态即可提供足够信息,使用一个模态的预测结果来为其他模态生成伪标签,实现信息交叉传播
这些方法面临一个重要的瓶颈:模态信息缺口。如图1所示,任务相关信息不仅存在于模态共享特征中,还大量存在于模态特有的特征中。仅建模单模态或模态共享信息的策略,无法充分利用所有模态中有价值的信息,甚至可能引入伪标签偏差,从而影响模型性能。
论文贡献
-
提出了首个针对图像-表格任务的半监督学习框架,系统性解决了标注数据稀缺的问题。
-
识别并定义了多模态任务中的“模态信息缺口”问题,并提出 STiL 框架,全面挖掘任务相关信息来弥合这一缺口。
-
提出了三个关键创新:(1)解耦对比一致性模块(DCC),同时学习模态共享和模态特有信息;(2)共识引导伪标签生成策略(CGPL),通过分类器共识生成高质量的伪标签;(3)原型引导标签平滑技术(PGLS),利用原型嵌入优化伪标签质量。
-
在自然图像与医学图像等多个数据集上的实验验证表明,STiL 在标注数据稀缺的条件下,依然显著优于现有单模态/多模态,的监督/自监督/半监督先进方法。
方法
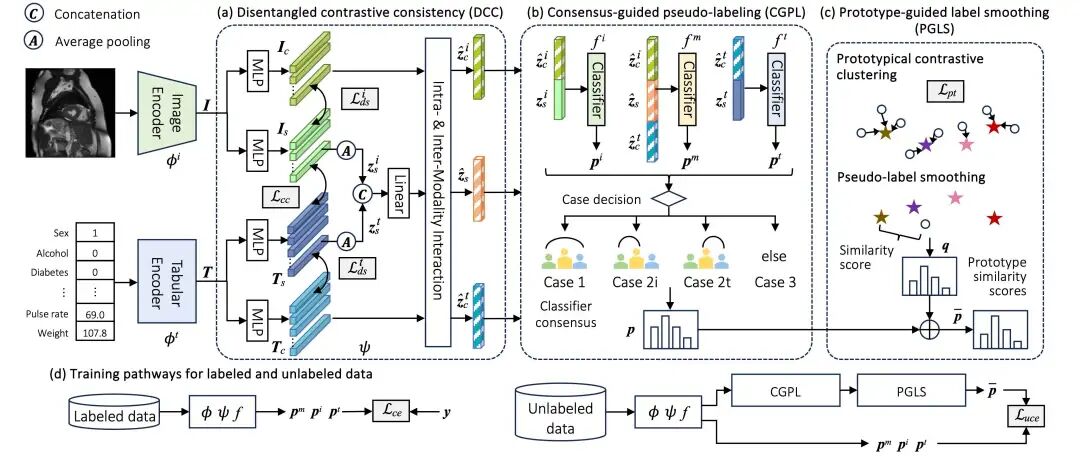
图2: STiL 的整体框架如下:模型使用编码器对图像与表格数据进行编码,通过解耦对比一致性模块(DCC)(a) 提取模态共享与模态特有信息,并通过多模态与单模态分类器进行预测。对于未标注数据,STiL 首先通过基于共识引导的伪标签策略(CGPL,(b))生成伪标签,随后结合原型相似度进行标签优化(PGLS,(c))。(d) 模型在有标注与无标注数据上的训练路径。
STiL 框架的整体结构如图2所示,主要包含三个关键组件:
-
解耦对比一致性模块(DCC)(图2 (a)),学习完整的模态共享与模态特有表示;
-
共识引导的伪标签生成策略(CGPL)(图2 (b)),从无标注数据中挖掘任务相关信息;
-
原型引导的标签平滑策略(PGLS)(图 2 (c),进一步优化伪标签的质量。
解耦对比一致性模块(DCC)
DCC旨在在无真实标签监督的前提下,学习全面的多模态表示。为此,我们设计了两项关键机制:一是通过跨模态一致性约束,学习模态共享信息的不变表示;二是通过解耦约束,分离出每种模态的特有信息。
这一设计有助于模型更全面地理解多模态数据,有效缓解模态信息缺口的问题。此外,我们还引入了一个模态内与模态间交互模块,以进一步增强单模态和多模态表示的学习效果。
表示的解耦和一致性约束: 为实现跨模态一致性并保留模态特有信息,我们提出了两个互补的损失约束:

共识引导的伪标签生成策略
DCC 模块在特征层面利用无标签数据进行无监督表示学习。为了进一步从未标注数据中提取与任务相关的信息,我们在半监督学习流程中引入伪标签机制。受多智能体协作成功应用的启发——即多个模型联合决策通常比单一模型更稳健——我们提出了 CGPL 方法,该方法通过引入共识分类器协作机制来生成更可靠的伪标签,并减缓确认偏差问题。CGPL 包括两个步骤:共识协作与伪标签生成和选择性分类器更新。


原型引导的标签平滑(PGLS)
为了进一步提升伪标签的可靠性,我们提出了 PGLS,通过引入特征层级的标签信息来优化伪标签。与以往依赖实例级嵌入的平滑方法不同,PGLS 仅需存储类别原型即可,既更高效,又实现了更优的性能。PGLS 包含三个核心模块:类别原型提取、原型对比聚类和伪标签平滑。


实验结果
我们使用一个医疗图像数据集 UK Biobank 和一个自然图像数据集 DVM。在 UK Biobank 上,我们进行两个心脏疾病分类任务:冠状动脉疾病(CAD)和心肌梗死(Infarction),使用 2D 短轴心脏磁共振图像和75个与疾病相关的表格特征。DVM 是一个公开可用的汽车应用数据集,包括 2D 汽车图像和与汽车相关的表格数据,在其上我们进行了一个包含 283 类的汽车模型分类任务。
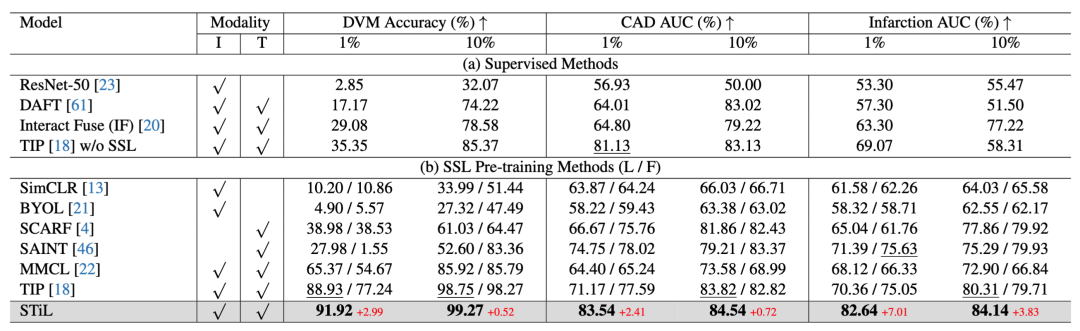
表2: 与监督和自监督方法比较。
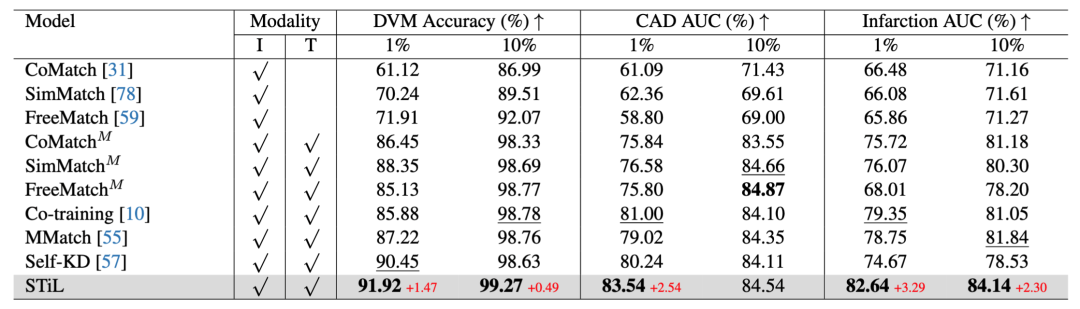
表3: 与半监督方法比较。

表4: 消融实验。

图3: 不同方法在 1% 标注的 DVM 上的绘图结果: (a)置信伪标签的准确率;(b)具有置信伪标签的未标注样本比例;(c)平滑项 q 在置信伪标签样本上的准确率;(d)平滑项 q 在全部未标注样本上的准确率。
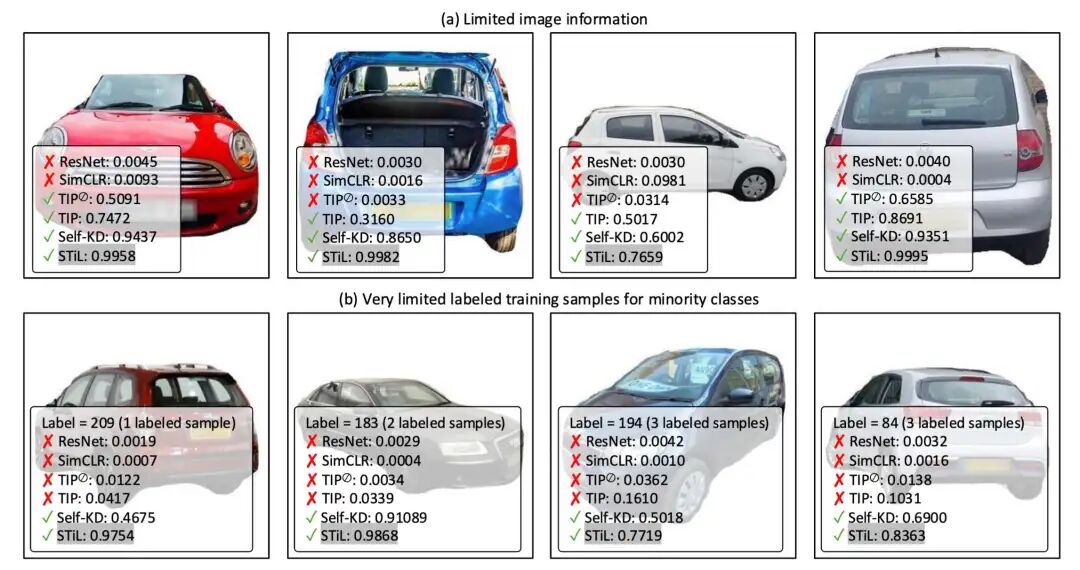
图4: 样例分析。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









