




本文来源公众号“arXiv每日学术速递”,仅用于学术分享,侵权删,干货满满。
原文链接:https://mp.weixin.qq.com/s/CQluUL9LikckSmVeiazsCw
导读
视觉生成模型正经历一场革命。港大&字节跳动联合推出DanceGRPO:为视觉生成领域带来创新突破。通过强化学习优化视觉生成任务,解决了现有方法在多样化Prompt集上的不稳定性问题。它不仅在多任务上展现了卓越的性能,还为RL与视觉生成的结合提供了新的洞见。
本文目录
1 DanceGRPO:视觉生成 GRPO 的绝佳基线
(来自 ByteDance,港大 MMLab 罗平老师团队)
1.1 DanceGRPO 研究背景
1.2 Diffusion Model 和 Rectified Flow:一枚硬币的两面
1.3 把采样视为马尔科夫决策过程
1.4 采样 SDE 的形式
1.5 DanceGRPO 算法
1.6 验证
1.7 实验设置
1.8 实验结果
1.8.1 文生图实验
1.8.2 文生视频实验
1.8.3 图生视频实验
太长不看版
视觉生成 GRPO 的绝佳基线。
Reinforcement Learning (RL) 今天已经成为了微调生成式模型的一个重要的方法,现有的方法比如 DDPO 和 DPOK 存在一些固有的限制:当缩放到更大,更加多样化的 Prompt 集时,较难稳定优化,会限制其实用性。
本文提出的 Dance-GRPO 把 Group Relative Policy Optimization (GRPO) 用到了视觉生成任务上。本文的 insight 是 GRPO 固有的稳定性使其能够克服掉基于 RL-based 的视觉生成方法的优化挑战。
DanceGRPO 的几个重要提升:
-
对多种生成范式,包括 Diffusion Model 和 Rectified Flow,展示出一致且稳定的 Policy 优化。
-
当缩放到复杂的现实世界场景 (包含 3 个任务,4 个模型) 时,表现出了鲁棒的性能。
-
在优化各种人类偏好方面,表现出非凡的多用性。由五个不同的奖励模型捕获,这些模型评估图像/视频美学、文本图像对齐、视频运动质量和二进制反馈。
综合实验表明,DanceGRPO 在多个已建立的基准测试中优于 Baseline 方法高达 181%,包括 HPS-v2.1、CLIP Score、VideoAlign 和 GenEval。DanceGRPO 为视觉生成中 Scaling RLHF 提供了一个稳健且通用的解决方案,为协调 RL 和视觉生成提供了新的 insight。
01 DanceGRPO:视觉生成 GRPO 的绝佳基线
论文名称: DanceGRPO: Unleashing GRPO on Visual Generation
论文地址: https://arxiv.org/pdf/2505.07818
代码链接: https://github.com/XueZeyue/DanceGRPO
02 DanceGRPO 论文解读
1.1 DanceGRPO 研究背景
对于生成模型而言,在训练期间整合人类反馈,对于将模型的输出与人类偏好以及审美标准相对齐至关重要。现在的方法有下面这么几种。ReFL依赖于可微的 Reward Model,在视频生成中引入了 VRAM,效率低下,需要大量的工程。DPO 变体 (Diffusion-DPO),Flow-DPO) 实现了微小的视觉质量改进。基于 RL 的方法把 Reward 视作黑盒目标来优化,提供了潜在的解决方案,但引入了 3 个未解决的挑战:
-
Rectified Flow里面 ODE-based 的采样与马尔科夫决策过程 (Markov Decision Process) 冲突。
-
Policy Gradient 方法 (DDPO, DPOK) 在 scaling 到小数据集时表现出不稳定性。
-
现有方法对于视频生成任务仍未验证。
本文通过 Stochastic Differential Equations (SDEs) 重新把 Diffusion Model 和 Rectified Flow 的公式表述了一遍,并使用 GRPO 稳定训练。DanceGRPO 框架将 GRPO 适配到了视觉生成任务。
DanceGRPO 的关键 insight 是:GRPO 的架构稳定性质,为 "RL 方法+视觉生成任务" 所带来的不稳定性提供了解决方案。
DanceGRPO 的评测不仅涵盖不同的生成模型范式 (Diffusion Model, Rectified Flow),还涵盖不同任务 (text-to-image, text-to-video, image-to-video)。本文的分析采用了不同的基础模型和奖励指标来评估美学质量、对齐和运动动力学。此外,基于 DanceGRPO 框架,本文还提供了很多方面的 insights,包括:Rollout 初始化噪声、奖励模型兼容性、Best-of-N 推理缩放、时间步选择和二进制反馈学习。
1.2 Diffusion Model 和 Rectified Flow:一枚硬币的两面
Diffusion Model
Diffusion Model将噪声与数据混合,随着 timestep t 的进行逐渐破坏数据 x,其前向过程可以被定义为:

分析
虽然 Diffusion Model 和 Rectified Flow 具有不同的理论基础,但在实践中,它们是硬币的两面,如下式所示:

1.3 把采样视为马尔科夫决策过程
根据 DDPO 的做法,作者将 Diffusion Model 和 Rectified Flow 的去噪过程表述为马尔可夫决策过程 (Markov Decision Process, MDP):

1.4 采样 SDE 的形式
因为 GRPO 需要通过多个轨迹采样进行随机 Exploration,其中 Policy 的更新依赖于轨迹概率分布及其相关奖励信号,作者将 Diffusion Model 和 Rectified Flow 的采样过程统一为 SDE 的形式。
1) Diffusion Model
正向 SDE:

1.5 DanceGRPO 算法

虽然传统的 GRPO 采用 KL 正则化来防止 Reward 过度优化,但作者观察到不用它,性能差异很小。因此默认省略了 KL 正则化。
DanceGRPO 将 Diffusion Model 和 Rectified Flow 的采样过程表示为 MDP,使用 SDE 采样方程,采用 GRPO 风格的目标函数,并推广到文生图、文生视频以及图生视频任务。
初始化噪声
DanceGRPO 框架中,初始化噪声构成了一个关键组件。以前的基于 RL 的方法,如 DDPO,使用不同的噪声向量来初始化训练样本。然而,如图 1 所示,将不同的噪声向量分配给具有相同 Prompt 的样本,在视频生成中总是会导致 Reward Hacking 的现象,导致训练不稳定。因此将共享初始化噪声分配给来自同一文本 Prompt 的样本。

图1:HunyuanVideo 上 Reward Hacking (初始化噪声不同) 和无 Reward Hacking (初始化噪声相同) 的结果的可视化。Prompt: A splash of water in a clear glass, with sparkling, clear radiant reflections, sunlight, sparkle
时间步长选择
实证性观察表明,在不影响性能的情况下,可以省略去噪轨迹内的 timestep 子集。这种计算步骤的减少,在保持输出质量的同时提高了效率。
结合多个奖励模型
在实践中,作者使用多个奖励模型来确保更稳定的训练和更高质量的视觉结果。如图 2 所示,仅使用 HPS-v2.1 Reward 训练的模型往往会产生不自然的 ("oily") 输出,而合并 CLIP score 有助于保留更真实的图像特征。作者没有直接组合奖励,而是聚合 Advantage Function,因为不同的奖励模型通常在不同的尺度上运行。这种方法稳定优化并导致更平衡的生成。

图2:该图展示了 CLIP score 的影响。提示是 "A photo of cup"。作者发现仅使用 HPS-v2.1 奖励训练的模型往往会产生不自然的 ("oily") 输出,而结合 CLIP score 有助于保持更自然的图像特征
Best-of-N Inference Scaling
本文方法优先考虑使用高效的样本,尤其是与 Best-of-N 采样选择的前 k 和后 k 个候选者相关的样本。这种选择性采样策略通过关注解空间的高回报和关键的低回报区域来优化训练效率。作者使用蛮力搜索来生成这些样本。
1.6 验证
作者在 2 个生成范式 (Diffusion Model 和 Rectified Flow) 和 3 个任务 (文生图,文生视频,图生视频) 中验证了本文算法的有效性。
作者选择了四个基本模型 (Stable Diffusion, HunyuanVideo, FLUX, SkyReels-I2V) 进行实验。所有这些方法在采样过程中,可以通过 MDP 框架来构建。这使我们能够统一这些任务的理论基础,并通过 DanceGRPO 改进它们。
作者使用五个奖励模型来优化视觉生成质量:
-
图像美学使用在人工评价数据上微调的预训练模型来量化视觉吸引力。
-
图文对齐采用 CLIP 来最大化提示和输出之间的跨模态一致性。
-
视频美学质量使用 VLM 将图像评估扩展到时间域,评估帧质量和连贯性。
-
视频运动质量通过物理感知的 VLM 来评估运动真实感。
-
Thresholding Binary Reward 的 Reward 通过固定的阈值离散化 (超过阈值的接收 1,其他就是 0)。
1.7 实验设置
文生图
-
模型:Stable Diffusion v1.4, FLUX, 和 HunyuanVideo-T2I。
-
Reward Model:HPS-v2.1 和 CLIP score。
一个精心策划的,平衡多样性和复杂性的 Prompt 集来指导优化过程。为了评估,作者选择了 1,000 个测试 Prompt 来评估 CLIP score 和 Pick-a-Pic。对 GenEval 和 HPS-v2.1 Benchmark 使用官方 Prompt。
文生视频
-
模型:HunyuanVideo
-
Reward Model:VideoAlign
使用 VidProM 数据集策划 Prompt,并过滤另外 1000 个测试 Prompt,来评估 VideoAlign 分数。
图生视频
-
模型:SkyReels-I2V
-
Reward Model:VideoAlign 作为主要奖励指标。由 ConsisID 构建的 Prompt 数据集与 FLUX 合成的参考图像配对,以确保保真度。
过滤另外 1000 个测试 Prompt,来评估 VideoAlign 分数。
DanceGRPO 基于 FastVideo 开发。总是使用超过 10,000 个 Prompt 来优化模型。本文提出的所有 Reward 曲线都是使用移动平均绘制的,以获得更平滑的可视化。使用基于 ODE 的采样器进行评估和可视化。
1.8 实验结果
1.8.1 文生图实验
Stable Diffusion 实验
Stable Diffusion v1.4 是一个基于扩散的文生图模型,包括 3 个核心组件:用于去噪的 UNet 架构、用于语义调节的基于 CLIP 的 text encoder 和用于 latent space 建模的 VAE。
如图 3 和图 4-(a) 所示,DanceGRPO 在奖励指标方面取得了显着改进,将 HPS score 从 0.239 提高到 0.365,将 CLIP score 从 0.363 提高到 0.395。作者也采用了 Pick-a-Pic 和 GenEval 等指标来评估本文方法。结果证实了本文方法的有效性。

图3:Stable Diffusion v1.4 实验结果
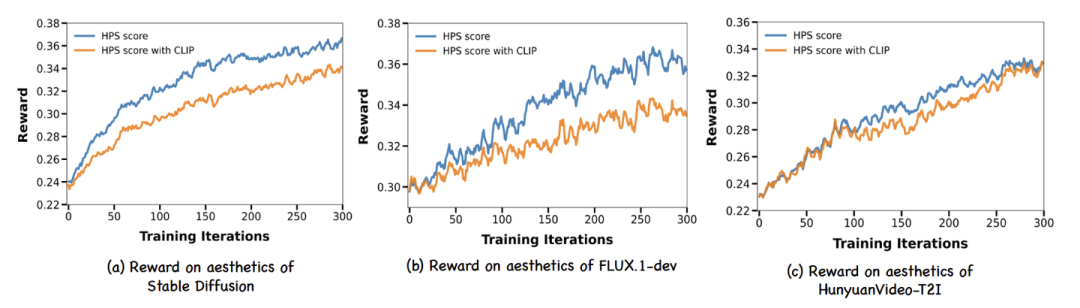
图4:Stable Diffusion, FLUX.1-dev, 和 HunyuanVideo-T2I 的 HPS Reward 曲线。用上 CLIP score 后,HPS score 降低,但生成的图像变得更加自然
FLUX 实验
FLUX.1-dev 是一种 Flow-based 的文生图模型,在多个基准测试中推进最先进的技术,架构比 Stable Diffusion 更复杂。为了优化性能,作者集成了两个奖励模型:HPS score 和 CLIP score。如图 4-(b) 和表 3 所示,所提出的训练范式在所有奖励指标上都取得了显着的改进。

图5:FLUX 结果。这个图展示了 FLUX,使用 HPS score 训练的 FLUX、以及使用 HPS score 和 CLIP score 训练的 FLUX 的结果
HunyuanVideo-T2I 实验
HunyuanVideo-T2I 是 HunyuanVideo 框架的文生图版本,通过将 latent frame 的数量减少到 1 来重新配置。这种修改将原始视频生成模型转换为 Flow-based 的图像生成模型。作者使用公开可用的 HPS-v2.1 模型 (一种人类偏好驱动的视觉质量指标) 进一步优化。如图 4-(c) 所示,这种方法将平均奖励分数从大约 0.23 提高到 0.33,反映了与人类审美偏好更好的对齐。
1.8.2 文生视频实验
HunyuanVideo 实验
与文生图模型相比,优化文生视频模型会带来更大的挑战,主要是由于训练和推理过程中的计算成本提高,收敛速度较慢。
在预训练中,作者采用渐进式策略:初始训练侧重于文生图,然后是低分辨率视频生成,最后是高分辨率视频细化。然而观察表明,仅依靠以图像为中心的优化会导致视频生成得到次优的结果。为了解决这个问题,作者使用的训练视频样本都是 480×480 分辨率合成的,但是可视化时候可以使用更大的分辨率。
此外,构建一个有效的 Video Reward Model 来训练对齐模型也有很大的困难。本文实验评估了几个模型:Videoscore 模型表现出不稳定的奖励分布,使得优化不切实际,而 Visionreward-Video 是一个 29-dimensional metric,产生了语义连贯的奖励,但在各个维度上都存在不准确。
因此,作者采用了 VideoAlign,这是一个多维框架,用于评估视觉美学质量、运动质量和文本-视频对齐 3 个关键方面。值得注意的是,文本-视频对齐维度表现出显著的不稳定性,因此排除在最终分析之外。如图 6-(a) 和图 6-(b) 所示,本文方法在视觉和运动质量指标方面分别获得了 56% 和 181% 的相对改进。
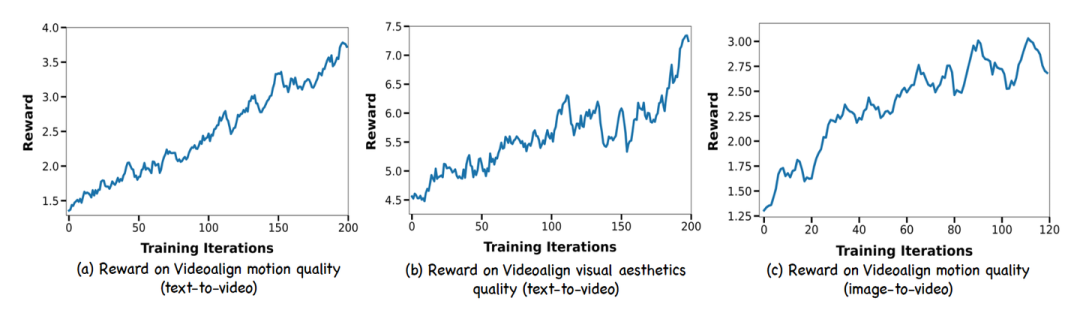
图6:将 HunyuanVideo 上运动质量和视觉美学质量,SkyReels-I2V 上的运动质量的训练曲线可视化
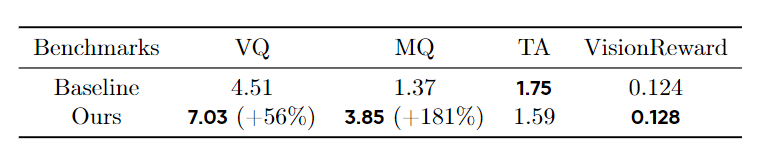
图7:使用 VideoAlign VQ&MQ 训练的 HunyuanVideo 在 VideoAlign 和 VisionReward 的结果
1.8.3 图生视频实验
SkyReels-I2V 实验
SkyReels-I2V 代表了本研究开始时 (截至 2025 年 2 月) 的最先进的开源图生视频模型。SkyReels-I2V 源自 HunyuanVideo 模型,通过将图像 condition 集成到 input 来微调模型。本文的一个核心发现是 I2V 模型只允许优化运动质量,包括运动连贯性和审美动态,这是因为视觉保真度和文本-视频对齐本质上受到输入图像的属性的限制,而不是模型的参数空间。因此,本文的优化方案利用了 VideoAlign Reward Model 中的运动质量 metric,在这个维度上实现了 118% 的相对改进,如图 6-(c) 所示。
人工评估
使用内部 Prompt 和参考图像进行评估。对于文生图,在 240 个 Prompt 上评估 FLUX。对于文生视频,在 200 个 Prompt 上评估 HunyuanVideo,对于图生视频,在 200 个 Prompt 上测试 SkyReels-I2V 及其相应的参考图像。结果如图所示,人类始终更喜欢用 RLHF 细化的输出。
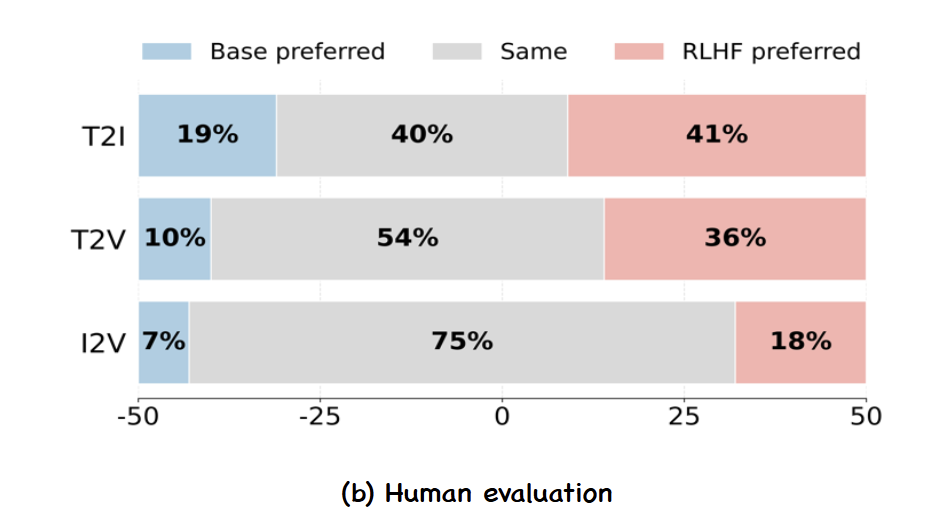
图8:使用 FLUX (T2I)、HunyuanVideo (T2V) 和 SkyReel (I2V) 展示人工评估结果
03 参考
-
ImageReward: Learning and Evaluating Human Preferences for Text-to-Image Generation
-
Diffusion Model Alignment Using Direct Preference Optimization
-
Improving Video Generation with Human Feedback
-
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
-
Training diffusion models with reinforcement learning
-
Dpok: Reinforcement learning for fine-tuning text-to-image diffusion models
-
Denoising Diffusion Probabilistic Models
-
Score-based generative modeling through stochastic differential equations
-
Building normalizing flows with stochastic interpolants
-
Stochastic interpolants: A unifying framework for flows and diffusions
-
Diffusion meets flow matching: Two sides of the same coin
-
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









