






本文来源公众号“AI新智力”,仅用于学术分享,侵权删,干货满满。
原文链接:大模型入门20:从Function Calling到MCP

“为了让大模型输出超出其范围的或者特定的知识,人们发明了多种方法。从提示工程到RAG,从Function Calling到MCP,莫不如是。”
生常谈的两个问题
应读者要求谈一下Function Calling。为了理解Function Calling,理顺知识脉络,向前不得不提到提示工程,向后不得不提到MCP。技术演进的推动力是应用需求,对大模型而言,不能满足人们需求关键问题有二:
一是大模型的知识更新问题。前文9提到:大模型存在知识更新问题,大模型在训练完成后,其知识也已固化无法更新。因此通过提示工程及RAG技术(本质上也是提示工程的一种)把新知识输入到大模型中。
但这还远远不够,比如获取实时信息(例如天气、数据检索等)、执行相关任务(例如发送邮件、自动化任务等),因此又提出了Function Calling技术,通过程序调用的方式让大模型自动获取外部的知识,并关联进一步的动作,在此过程中又遇到了第二个问题:
二是大模型与外部交互(或者说任务执行)问题。这个问题是构建智能体(Agent)的关键问题,因为只有能作用于外部环境的实体才可称之为智能体,才能让大模型从一个只会聊天工具进化成为一个提高生产力的工具。
注:根据《人工智能:现代方法(第4版)》的定义:任何通过传感器(sensor)感知环境(environment)并通过执行器(actuator)作用于该环境的事物都可以被视为智能体(agent)。
大模型想要有更强的能力,就需要有效、安全地与外界进行互动,解决上述两个关键问题。
我们知道,工具可以分为三个层级:信息工具、辅助工具、生产工具。解决上述两个问题,是大模型从信息工具到辅助工具再到生产工具转变的关键所在。

这个过程中就又引出了N×M 问题:
前文12提到:大模型对外交互存在N×M 问题,其中N代表大型语言模型,M代表工具。在N方面,有许多大模型,在M方面,有无数的外部对接工具。每个大型模型提供商都有自己的协议来连接外部工具,使得潜在的集成点无穷无尽。
综上,我们可以看到,从提示工程到RAG、从Function Calling到MCP,在大模型应用落地的道路上,人们一直通过创新技术应用,修补大模型的先天缺陷,发挥大模型的功能优势,赋能产业和应用。
为方便讨论Function Calling和MCP的功能,这里有必要对大模型应用的架构进行清晰描述。我们所说的大模型应用,一般可以分为三层:基础设施层、模型层和应用层。应用层和模型层之间的信息交互方式只有一种,那就是Prompt。我们所说的RAG技术、Function Calling技术、MCP协议等都指的是应用层与外部数据库或工具之间的信息交互。
注:对于Function Calling技术而言,为了让大模型支持函数识别功能,因此对大模型参数进行了微调。

Function Calling(函数调用)
1. 含义
函数调用(Function Calling)也称为工具使用或API调用,是一种特定大模型提供的一种机制,使模型能够主动生成结构化输出,以调用外部系统中预定义的函数或 API。通过函数调用技术与外部系统、API和工具进行交互,可靠地实现大模型连接和使用外部工具的能力。通过向大模型提供一组函数或工具,以及它们的描述和使用说明,模型可以智能地(通过训练阶段的微调实现)选择和调用适当的函数来完成给定的任务。
注:这里所说的“模型可以智能地选择和调用适当的函数”,“智能”的能力来自于基础大模型训练过程中的“微调”。也就是说,只有专门针对“Function Calling”微调过的大模型才会有此功能,而且每家大模型厂商都有不同的微调技术方式。例如,像GPT、DeepSeek这样的大模型已经过微调,可以检测何时需要调用函数,然后输出包含参数的JSON来调用该函数。
2. 工作原理和流程
为了更加直观地展示Function Calling的工作过程,简要绘制了一个流程框图如下。
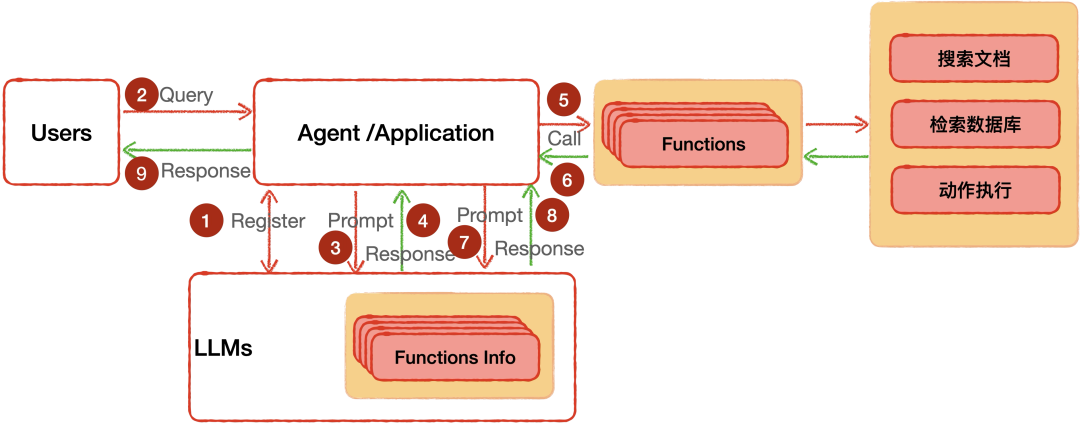
其主要工作步骤:
第①步:Agent 程序是我们开发的 AI 程序,在程序中会预先向大模型注册外部函数接口(一般不超过 20 个)。
当然,不同的大模型实现方式有所区别,例如DeepSeek是在发起请求(第②步)时直接将可能用到的函数列表直接发送给大模型。
第②步:用户使用自然语言(Prompt)发起请求,Agent 接收到请求。
第③步:Agent 程序将用户请求(Prompt)提交给大模型,大模型解析语义并根据第①步注册的函数信息,评估是否需要调用外部函数(Functions)。
第④步:模型如果判断需要调用函数,则生成包含函数 ID 和输入参数的调用指令,并返回给 Agent 程序。
第⑤步:Agent 程序接收到模型返回的调用指令后,执行对工具函数的调用。
第⑥步:工具函数执行后将结果返回给 Agent 程序。
第⑦步:Agent 程序将函数返回的结果和自定义提示词一起作为Prompt发送给大模型。
第⑧步:大模型结合函数返回的数据与上一轮上下文,生成最终结果,并返回给 Agent 。
第⑨步:Agent 程序将结果输出呈现给终端用户。
通过其工作过程可知,虽然Function Calling功能是大模型支持的功能,但是函数功能实现需由Agent提供,大模型本身不执行具体函数。也就是说外部与大模型的交互接口依然是提示词(Prompt)。
函数调用的代码实现很简单,可以参考支持Function Calling功能的大模型官方文档,例如Deepseek的官方文档地址如下:
# https://api-docs.deepseek.com/zh-cn/guides/function_calling3. 功能特点
实时反馈:模型生成的函数调用指令,由 Agent 程序执行后,再次反馈给模型,使模型生成实时和精准的回应。
实现灵活:没有严格的标准通信协议要求,通信格式取决于具体模型厂商。但是对于不同的厂商的大模型,Agent需要逐个适配。
4.常用场景
函数调用能够使大模型与外部工具和API进行交互,将其功能扩展到基于文本的响应之外,以下是一些需要在LLM中调用函数的任务示例:
1. 聊天机器人:函数调用可用于创建复杂的会话代理或聊天机器人,通过调用外部API或外部知识库并提供更相关和更有用的响应来回答复杂的问题。
2.自然语言理解:它可以将自然语言转换为结构化JSON数据,从文本中提取结构化数据,并执行命名实体识别、情感分析和关键字提取等任务。
3.数学问题解决:函数调用可用于定义自定义函数,以解决需要多个步骤和不同类型的高级计算的复杂数学问题。
4. API集成:它可用于将LLM与外部API有效集成,以获取数据或根据输入执行操作。这可能有助于构建QA系统或创意助手。
5.信息提取:函数调用可有效地用于从给定输入中提取特定信息,例如从文章中检索相关新闻故事或参考文献。
6.电子邮件发送:LLM可以使用函数调用来生成用于执行电子邮件发送任务的结构化响应(例如JSON对象),而不是生成基于文本的响应。
7.数据检索:函数调用可用于检索实时数据或当前事件、个人信息(如日历约会、电子邮件或待办事项列表项)或业务信息(如销售数据、客户信息或支持查询)。
8.任务自动化:函数调用可用于通过定义模型可用于扩展其功能和知识的自定义函数来自动化任务,例如对数据进行操作以及对存储在其他地方的信息进行更改或更新。
从Function Calling到MCP
1. 工作原理和工作流程
前文12已经叙述了大模型的基本原理和工作流程,本文不再赘述。
2. Function Calling和MCP的区别与联系
Function Calling依赖大模型的是否具备函数调用功能,而MCP是一种标准通用协议,可以说是Function Calling功能的升级版。但是无论大模型是否支持Function Calling功能,MCP协议均能使用。具体而言:Function Calling和MCP之间的区别主要有:
(1)交互模式不同
MCP:支持交互式、持续性的上下文管理,AI 可以与外部资源多轮互动。
Function Calling:简单的请求-响应模式,单次调用执行特定任务,无交互延续性。
(2)功能定位不同
MCP:开放的标准协议,定义通用通信架构和数据格式(类似于 USB 标准)。
Function Calling:特定模型厂商提供的扩展能力。
(3)通信协议标准化要求不同
MCP:严格遵守 JSON-RPC 2.0,具备高度标准化和互操作性。
Function Calling:无统一标准,协议依赖具体模型厂商实现。
(4)生态开放程度不同
MCP:生态开放,社区共建为主,任意开发者或服务商可自由接入。
Function Calling:生态相对封闭,依赖特定模型厂商支持。
大模型技术演进
1.关于现状
自从ChatGPT诞生以来,大模型技术迭代非常迅速,从提示词工程(Prompt Engineering)、思维链(CoT)到检索增强生成技术(RAG),从Function Calling到MCP协议,再到A2A协议,各种技术层出不穷,应用场景越来越广,作为使用者,无论大模型外围技术如何变换多端,要紧紧抓住的是技术背后的实质。这些技术的共同点有:
-
均在应用层(Application/Agent)实现,并未改变大模型本身的功能(除Function Calling有微调外)。
-
这些技术出现,主要源于大模型的原生功能不足,例如知识更新问题。
-
当一项技术被证明确实有用,就会快速的被大模型集成到自身内部,变成为大模型原生能力,不再需要外围程序的支撑。例如,从思维链到推理模型,从MCP协议到大模型原生支持工程。
因此,我们对于这些技术无需过多焦虑(新技术出现后广大自媒体往往会贩卖焦虑),新技术必须要经过市场的检验才能投入生产环境使用。
2.关于新技术新方向
到目前为止,这些技术还都是大模型本身之外的外围技术,应用程序与大模型交互的方式(Prompt)仍没有改变,这是由Transformer架构决定的。大模型的知识的训练后固化问题仍没有得到彻底解决。
那么,有没有其他扩展大模型能力的技术,不是通过应用程序补丁的方式进行实现,而是可以直接修改大模型的参数,简洁高效的实现大模型能力扩展呢?我想会有的,而且这样的技术会在不久的将来就会发展起来。
比如,大模型编辑技术。

相信在不久的将来,大模型会原生集成支持更多的功能接口,让应用层开发人员更加方便高效地开发智能体应用。
3.关于大模型学习与实践
人工智能大模型不是万能的,还有很多不能。当然,在人工智能广泛渗透,智能时代扑面而来的今天,你不去学习、不去了解、不去拥抱、不去应用人工智能,这是万万不能的。
注:以上表述出自南京大学党委书记谭铁牛。
在别人钓的鱼中再去钓鱼,可能是站在别人的肩膀上,但也缺少了跳跃下来自己行走的勇气。不管大模型的技术是否真的好用,应用是否能真的带来价值,如果没有做到真正弄通搞懂,也会是雾里看花,人云亦云。
因此,我们需要真正认识大模型,更加深入的掌握大模型。知其然,然后知其所以然,才可在应用实践中创新赋能。
参考文献:
1.https://medium.com/@danushidk507/function-calling-in-llm-e537b286a4fd
2.https://www.promptingguide.ai/applications/function_calling
3.https://vectorize.io/how-i-finally-got-agentic-rag-to-work-right/
4.https://arxiv.org/abs/2305.13172
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









