






本文来源公众号“AI生成未来”,仅用于学术分享,侵权删,干货满满。
原文链接:告别人工标注!首个MLLM数据流水线!中国团队重构AIGC生态:2D→3D→4D全自动生成

文章链接:https://arxiv.org/pdf/2508.05580
亮点直击
提出基于MLLM的高效数据合成智能体框架Follow-Your-Instruction,可为多样AIGC任务合成真实世界数据;
为实现高质量高效数据生成,引入综合基准以评估MLLM驱动智能体在2D、3D与4D层级的表现,并开发多种MLLM辅助数据生成形式(包括上下文引导与长期指导);
通过微调3种最新基线模型在典型2D、3D与4D任务上的实验证明,采用我们的数据能显著提升模型在下游应用的性能。
随着AI生成内容(AIGC)需求的增长,对高质量、多样化且可扩展数据的需求变得日益关键。然而,收集大规模真实世界数据仍然成本高昂且耗时,阻碍了下游应用的发展。尽管部分工作尝试通过渲染过程收集任务特定数据,但大多数方法仍依赖手动场景构建,限制了其可扩展性和准确性。为应对这些挑战,提出Follow-Your-Instruction,一个由多模态大语言模型(MLLM)驱动的框架,用于自动合成高质量的2D、3D和4D数据。
Follow-Your-Instruction首先通过多模态输入使用MLLM-Collector收集资产及其关联描述,随后构建3D布局,并分别通过MLLM-Generator和MLLM-Optimizer利用视觉语言模型(VLMs)对多视角场景进行语义优化。最后,使用MLLM-Planner生成时间连贯的未来帧。通过在2D、3D和4D生成任务上的全面实验评估生成数据的质量。结果表明,本文的合成数据显著提升了现有基线模型的性能,证明了Follow-Your-Instruction作为生成智能的可扩展高效数据引擎的潜力。
引言
AI生成内容(AIGC)旨在利用生成模型创造具有创意且逼真的内容,目前已广泛应用于电影工业、增强现实、自动化广告以及社交媒体内容创作。基础模型的最新进展,例如扩散模型和多模态大语言模型(MLLMs),显著提升了生成内容的质量与灵活性。作为数据驱动模型,这些模型通过大规模训练数据集学习强大的先验知识,使其能够轻松应对多模态理解、生成、视觉编辑、动画以及具身机器人等复杂任务。
然而,随着AIGC应用向更复杂和细粒度场景发展,对高质量、任务特定数据的需求大幅增加。尽管大多数开源基础模型训练于LAION-400M和WebVid-10M等大规模通用数据集,但这些数据集通常缺乏细粒度应用所需的特定任务标注。例如,物体移除任务需要精确的背景掩码,而4D生成则依赖准确的相机轨迹。此类精确监督信号的缺失,往往限制了这些数据集在专用生成任务中的直接适用性。
目前已有部分早期工作[23, 46]尝试通过渲染管线构建任务特定数据集。Blender等渲染引擎能够精细控制物体布局、光照条件和物理交互,适合为特定AIGC任务定制数据集。此类合成数据集常被用于微调强大的基础模型,以提升下游应用性能。然而,手动设计与构建此类数据集仍是主要瓶颈,因其需要大量人力、领域专业知识,且难以平衡真实性、准确性与可扩展性。
为应对这些局限性,本文提出Follow-Your-Instruction——一种基于MLLM的高效数据合成智能体框架,旨在为广泛AIGC任务生成逼真且多样化的世界数据。更重要的是,据我们所知,这是首个同时支持2D、3D与4D生成任务的数据生成系统。如下图1所示,该框架涵盖七种代表性应用,包括2D物体移除、3D修复、补全以及4D多视角生成。具体而言,通过利用MLLM对真实世界的广泛理解与交互能力,我们将强大MLLM集成至智能体中,并引入四个核心组件(MLLM-Collector、MLLM-Generator、MLLM-Optimizer和MLLM-Planner)以协助基准的设计与验证。

主要从两个维度评估Follow-Your-Instruction的性能:
-
MLLM驱动合成数据质量评估:为衡量MLLM驱动合成的能力,我们在8种MLLM(含商业工具与研究方法)上针对4项指标进行实验;
-
下游应用效果验证:进一步检验合成数据的有效性,我们使用合成数据微调3类下游任务(如2D物体移除、3D重建和4D视频生成)。结果表明任务特定性能显著提升,凸显了框架的实用价值。
相关工作
多模态大语言模型
多模态大语言模型(MLLMs)通过整合文本、视觉与3D模态持续演进。在内容修复领域,RestoreAgent展现2D任务的强劲性能,RL-Restore专注于模糊与噪声的渐进恢复,Clarity ChatGPT虽结合对话但适用范围有限。空间建模方面,Text2World与Spatial-MLLM分别聚焦符号化结构生成与双编码器推理,VSI-Bench则评估计数、导航等空间推理任务。具身交互中,GEA等模型在VisualAgentBench表现优异,而Embodied-Bench揭示GPT-4V等模型在长期规划中的局限。尽管进展显著,统一多模态评估与训练数据的缺失仍是挑战。
基于扩散模型的生成应用
扩散模型广泛应用于2D、3D与4D领域的生成任务。2D任务(如物体移除与重光照)依赖人工标注数据集与分割流程;3D领域,LiDAR Diffusion Models利用专用数据集重建深度/点云,MV-Adapter通过即插即用模块确保多视角一致性;4D方法如ReCamMaster与TrajectoryCrafter借助3D结构保证跨相机视频生成的连贯性,Follow-Your-Creation则探索4D视频编辑框架。然而这些方法需依赖成本高昂的大规模数据集。Follow-Your-Instruction利用MLLM生成高质量合成数据,降低真实数据依赖并增强适应性。
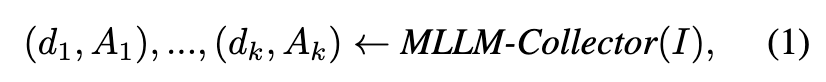
方法
本文提出的智能体框架——一个基于MLLM、覆盖2D/3D/4D层级的综合基准。如下图2所示,该框架基于先进多模态大语言模型(如GPT-4o、QWEN3)构建。
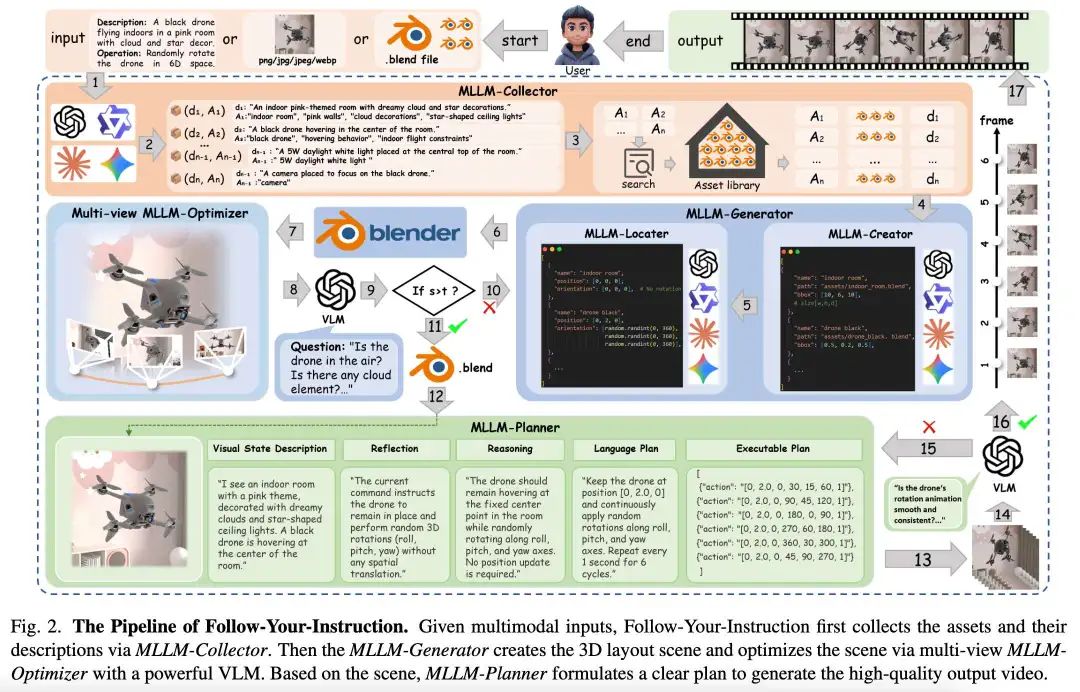
基于多模态输入的资产收集

全局场景构建与优化
3D布局生成


多视角优化
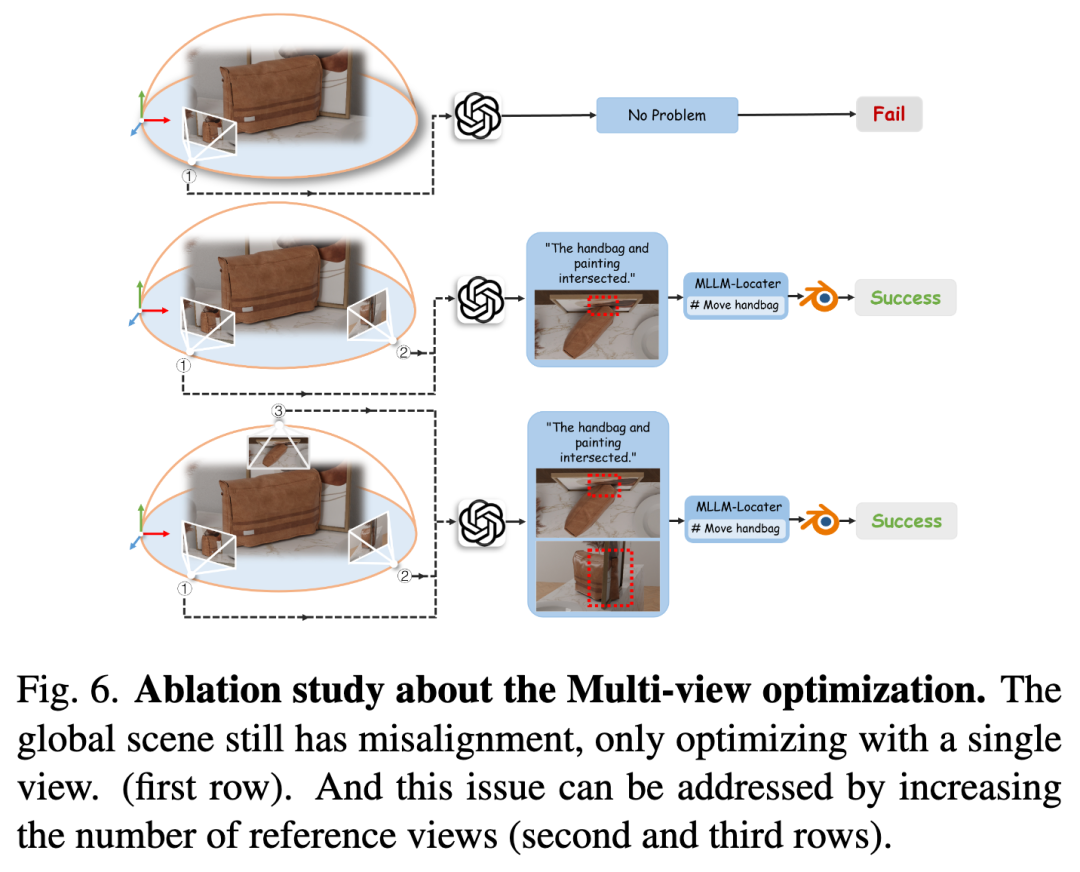
尽管通过多模态输入构建了完整场景,全局布局仍可能存在不匹配问题。现有工作[15]采用基于MLLM的迭代视觉反馈循环优化场景布局,但仅依赖单视角渲染往往不足,尤其在处理物体间物理交互时。例如下图3所示,当输入文本条件为"将两个杯子放在桌上"时,若仅从单一视角优化,可能仅调整粉色杯子在当前视图中的位置,而其他角度下该杯子仍悬浮于桌面(如图3(a))。这种差异源于MLLM无法感知当前视角隐藏的深度不一致性。
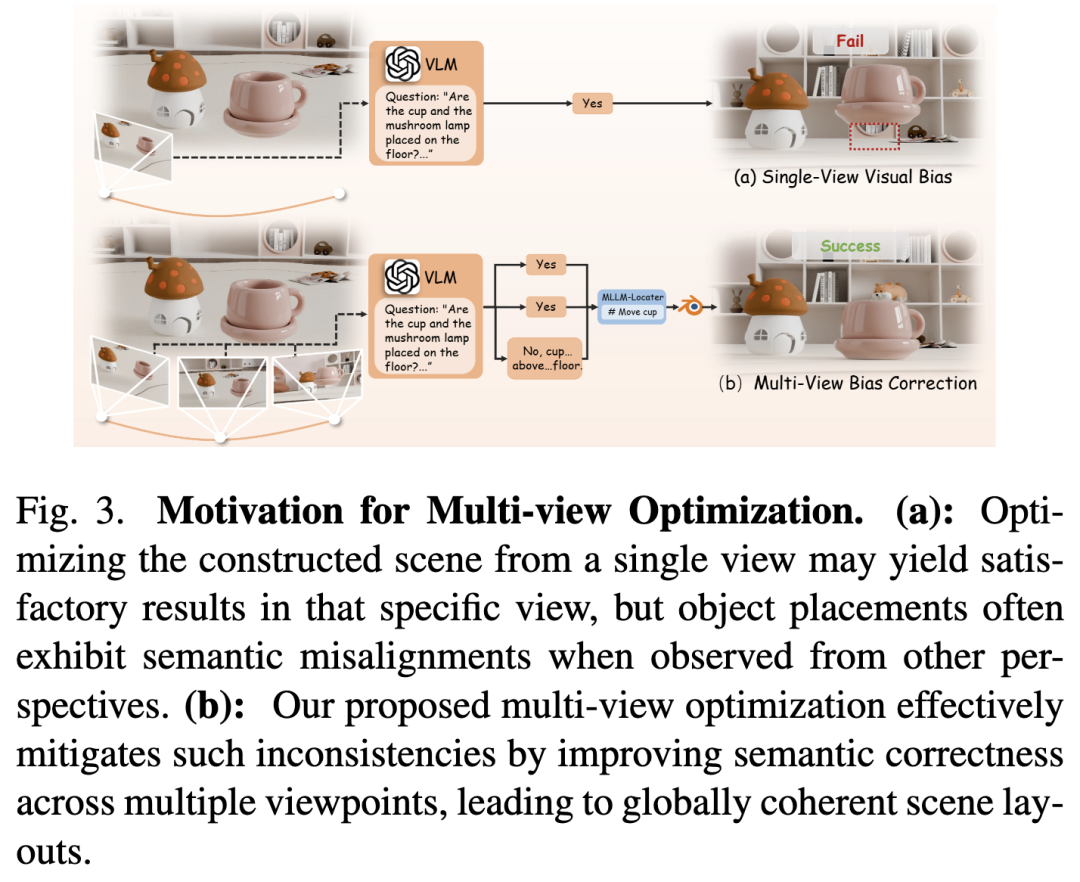

MLLM引导的任务规划
尽管MLLM-Optimizer生成的2D图像数据集足以支持简单任务(如2D物体移除、重光照与补全),我们仍需为实际应用合成高质量视频数据集。借助MLLM的上下文学习与长期学习能力,我们引入MLLM-Planner进行视频生成。
如图2所示,MLLM-Planner接收人类指令与生成场景作为输入,首先理解视觉场景并创建视觉状态描述,定位当前帧的主对象;随后结合人类指令与VLM优化器的反馈精炼动作,推理准确目标;最终将语言计划转化为可执行计划以生成后续帧。
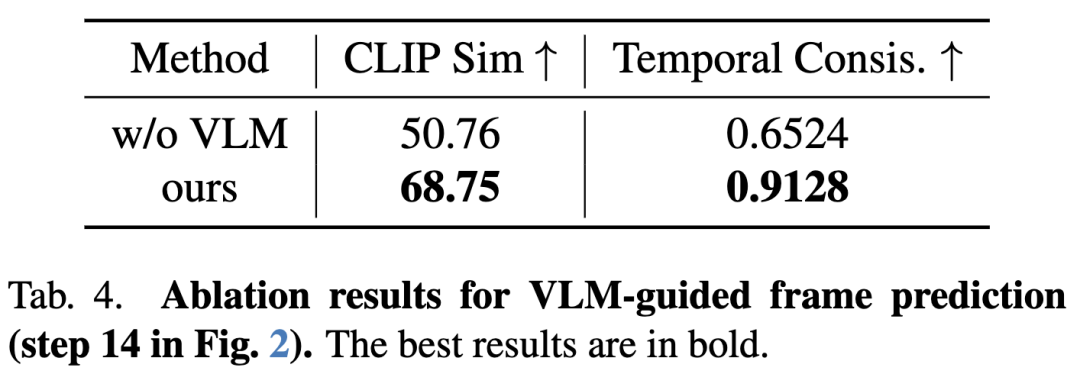
但连续帧间的时间不一致性问题仍然存在,这源于MLLM-Planner专注于离散动作执行而未能确保平滑过渡,导致生成序列可能出现突变、不自然运动或中间状态缺失。为此,我们引入VLM引导的帧预测模块(图2步骤14),利用VLM的视觉推理能力评估帧间运动、对象状态与场景动态。当检测到不一致时,该模块反馈至MLLM-Planner促使其优化动作或插入中间步骤,通过迭代提升时间连贯性与视频质量。
实验
生成场景质量评估
实验设置
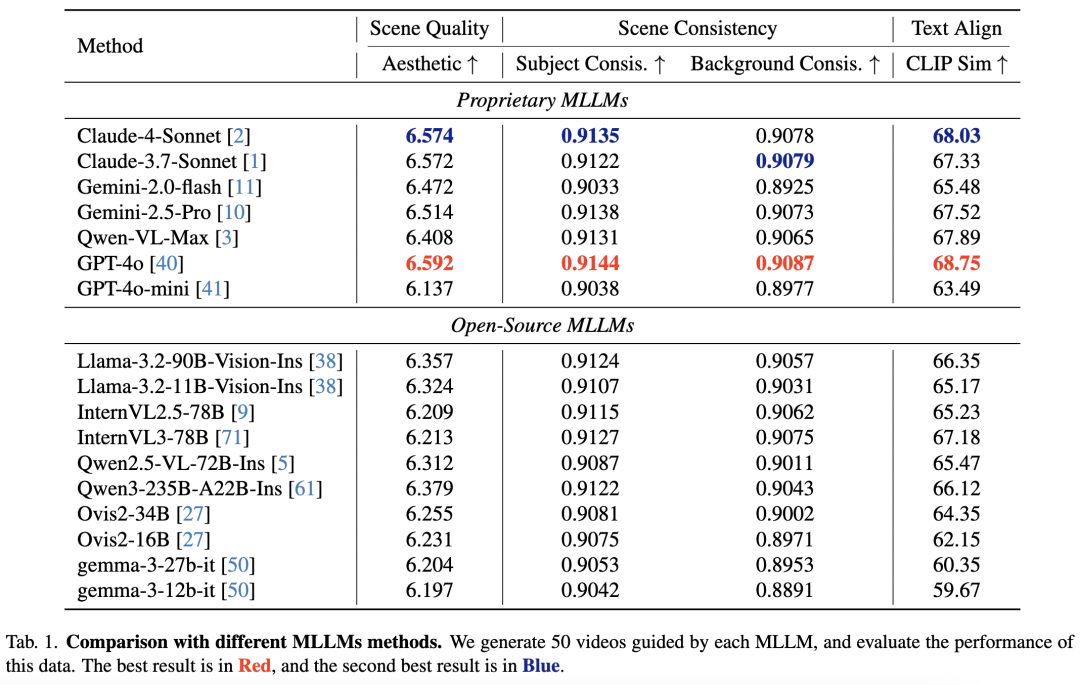
现有大多数多模态大语言模型(MLLMs)已展现出优秀的视觉与语言理解能力。参照近期工作[63],对比的基线为最先进的MLLMs,可分为闭源专有模型与开源模型,因其代表了多模态推理与决策的前沿水平。
闭源模型包括GPT-4o与GPT-4o-mini、Claude-3.5-Sonnet与Claude-4-Sonnet、Gemini-2.5-Pro与Gemini-2.0-flash以及Qwen-VL-Max。这些模型以通用多模态任务中的强大性能著称,具备先进的推理能力与互联网规模数据的广泛训练。开源模型如Llama-3.2 Vision Instruct、InternVL2.5与InternVL3、Qwen3与Qwen2.5-VL、Gemma-3及Ovis2,覆盖7B至90B参数量级,为研究提供可深入分析架构设计与缩放效应的替代方案。
实验结果
下表1展示了不同MLLMs应用于数据合成智能体的定量对比。我们使用美学分数评估感知质量,并基于VBench衡量主体外观与背景稳定性的场景一致性,文本对齐度通过CLIP相似度评估。结果表明MLLM引导在Follow-Your-Instruction中的关键作用:GPT-4o在所有指标中表现最优,凸显其卓越的跨模态推理与对齐能力;Claude-4-Sonnet与Claude-3.7-Sonnet在美学与一致性上紧随其后,但对齐度稍逊。开源模型中InternVL3-78B与Qwen3-235B-A22B-Ins综合表现最佳,但与GPT-4o仍有显著差距。需注意,本实验旨在证明框架核心MLLM驱动能力对多样AIGC任务与MLLM结构的普适性,而非追求单一MLLM的峰值性能。
应用展示
如下图4所示,展示了若干代表性任务及智能体生成的对应真实标注。这些案例凸显了智能体跨环境与任务目标的泛化能力。所提智能体的应用涵盖2D(物体移除与重光照)、3D(重建、旋转与具身智能)及4D环境(4D补全与重建),体现了Follow-Your-Instruction在新兴研究领域内容创作中的潜力。

下游应用评估
基线模型
为全面评估合成数据质量,在2D/3D/4D AIGC应用(包括物体移除、3D重建与4D视频生成)上微调多个基线模型。2D物体移除任务采用RoRem作为基线,评估数据微调后的改进;3D重建任务使用最新多视角重建框架MV-Adapter,衡量几何精度与一致性的提升;4D视频生成任务通过ReCamMaster评测动态场景合成的时间连贯性与保真度。这些基线系统化量化了合成数据对多维度AIGC模型的影响。
定性结果
下图5展示了2D/3D/4D应用的视觉对比。可见:未使用生成数据微调时,物体移除任务在语义补全上表现欠佳(如图5首行2D任务,模型生成异常白色物体而非修补砧板),移除后存在伪影(图5第二行2D任务);经数据微调后这些问题显著缓解。3D任务中,未微调模型虽能生成优质前视图,但后视图质量与一致性较差,微调后幻觉问题得以修正。

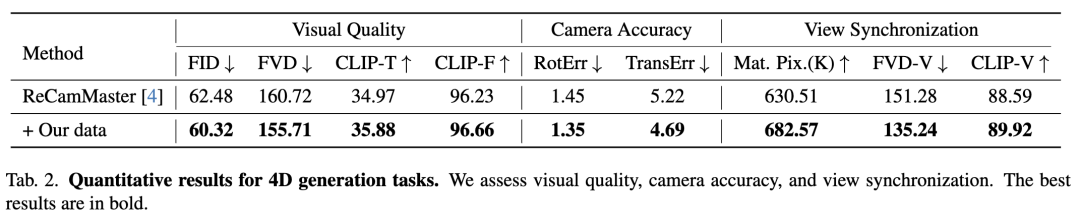
4D生成作为新兴范式,需在相机轨迹引导下合成可控视频。如图5所示,尽管ReCamMaster实现了较好的姿态精度与平滑镜头运动,背景仍存在不一致性与伪影,而我们的生成数据提升了其性能。
定量结果
针对三类应用的定量实验显示(2D物体移除与3D重建结果详见附录),4D生成结果如下表2所示。参照ReCamMaster,评估视觉质量、相机精度与视角同步性:通过旋转/平移误差衡量相机轨迹精度,计算CLIP-V与FVD-V评估同场景多视角同步性。结果表明基线模型经微调后性能均获提升。
消融实验
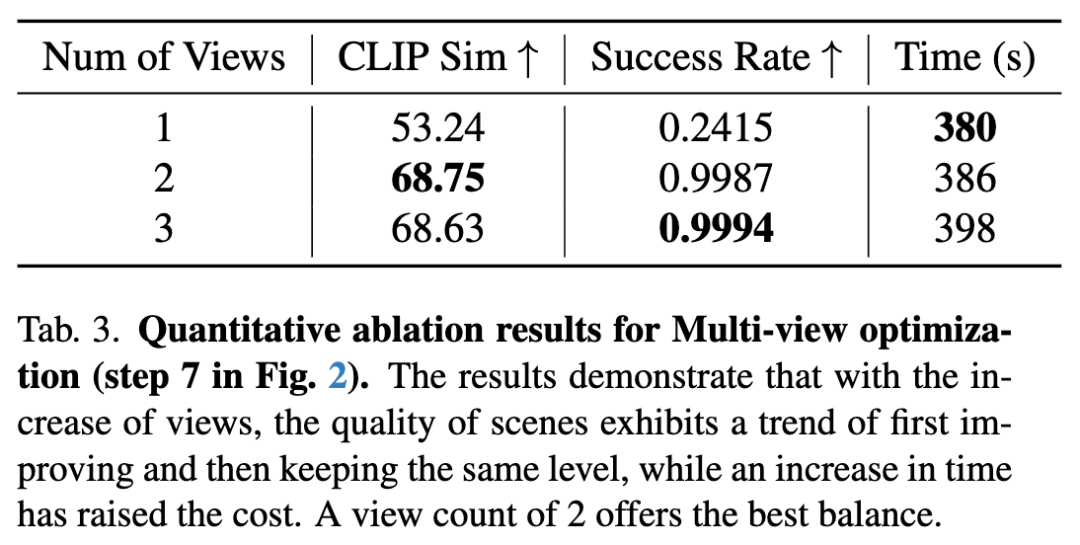
多视角优化有效性
如下图6所示,评估多视角优化策略中不同帧数的影响。仅使用单视角优化时,当前视角物体位置虽正确,但其他视角常出现错位;增加优化视角可缓解该问题。定量消融实验(下表3)表明:视角增加会延长生成时间,而优化成功率提升有限。基于此,我们选择双视角作为效率与性能平衡的最优配置。
VLM引导帧预测的有效性
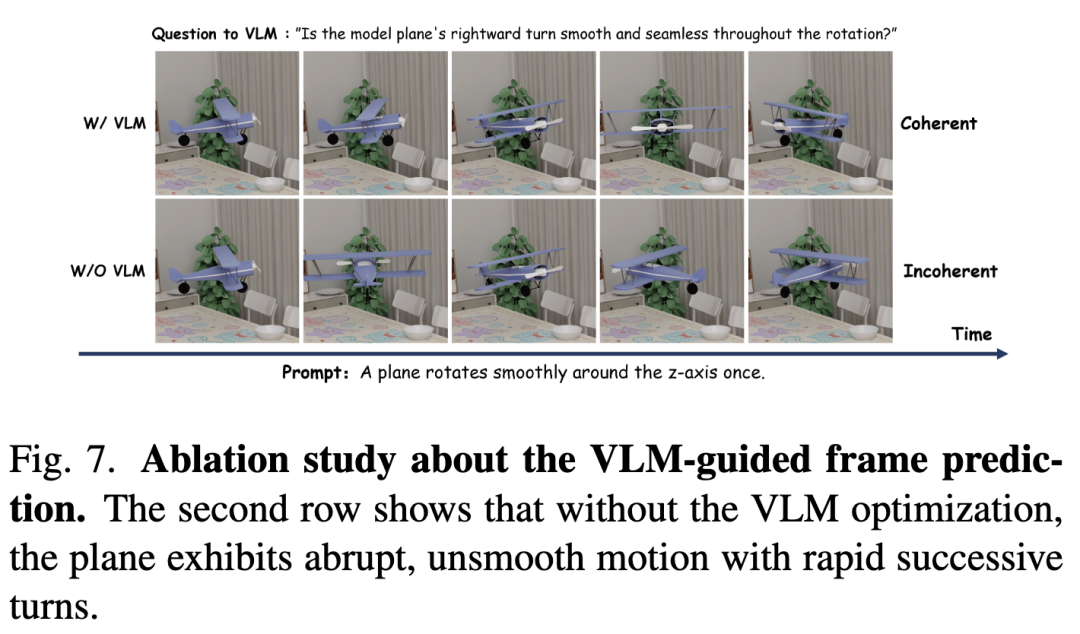
下图7与表4展示了VLM引导帧预测模块的贡献。如图7第二行所示,未采用该策略时,生成视频常出现时间不一致性——相邻帧间运动突变且不连贯。具体表现为:飞机旋转角度在连续帧间过大,导致短时间内呈现两次转向。这表明规划动作缺乏连续性,从而产生次优的视觉质量与时间断层。
结论与讨论
结论
Follow-Your-Instruction——一种基于MLLM的高效数据合成智能体框架,能够从多模态输入(如文本、图像或混合文件)生成跨2D、3D与4D层级的逼真场景。该框架以多模态大语言模型为核心,结合四大组件:MLLM-Collector、MLLM-Generator、MLLM-Optimizer与MLLM-Planner。
首先,MLLM-Collector将文本输入转化为资产或整合视觉输入的资产,增强用户导向的场景创建;
随后,MLLM-Generator构建场景3D布局并由MLLM-Optimizer优化;
最终,MLLM-Planner生成后续帧并通过VLM引导的帧预测模块进行精修。
实验结果表明,我们的智能体在数据合成过程中充分发挥了MLLM的能力,显著促进了多种下游AIGC应用。
局限性
当前方法存在三点不足:(1) 性能依赖于底层专有MLLM的能力;(2) 未验证生成数据对提升其他真实世界基准泛化性的效果;(3) 可扩展性受限于对既有资产库的依赖。
参考文献
[1] Follow-Your-Instruction: A Comprehensive MLLM Agent for World Data Synthesis
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 404
404

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









