






本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:使用 SAM 和 Grounding DINO 分割卫星图像

Echo 和 Shapes 简介
Echo 的使命是让世界变得易于理解,使公司能够更快地创新。我们拥有各种各样的客户,包括杂货连锁店、保险公司、广告代理商等。
我们的产品线大致可分为三个主要领域:数据(地点和形状)、洞察(移动数据和 GeoPersona)和技术(位置 SDK)。在本文中,我们将重点介绍我们的数据产品之一:Shapes 。
简而言之,Shapes 数据集由地理空间多边形数据组成,表示建筑物覆盖区、停车场、太阳能电池板等特征。我们的 Shapes 数据集是我们业务不可或缺的一部分。我们直接向客户销售它,它也是我们许多其他数据集的必要输入。例如,要计算特定地点内的停留时间,我们需要知道它的边界。
免费许可的数据集
从头开始构建卫星图像分析管道非常复杂。那么,我们为什么不简单地使用一些可用的、免费许可的数据集来构建覆盖区呢?
有一些值得注意的自由许可的建筑物覆盖区数据集:
-
-
OpenStreetMap (OSM)
-
Microsoft Building Footprints
-
Google Open Buildings
-
Overture Maps Foundation (OMF)
-
在大多数情况下,Microsoft 和 Google 数据集要么过时,要么在美国或欧洲没有得到足够的覆盖——我们的大多数客户都位于这些地区。
OSM 是一个开源的地图项目,由世界各地高度活跃的志愿者网络维护,在概念上类似于维基百科。它往往质量非常高,因为其他志愿者经常手动定义和检查足迹。尽管它在美国和欧洲都有很好的覆盖范围,但在大都市地区之外,尤其是郊区或工业区等非商业区域,它的覆盖范围非常有限。
OMF 是一项相对较新的计划,旨在结合多个开源和免费许可的地理空间数据集。他们的建筑足迹数据主要来自 OSM,因此具有相同的局限性。
这些数据集不足以满足我们的目的有几个原因:
如前所述,这些数据集中的大多数要么已过时,要么覆盖范围不足。OSM 是最好的,但即便如此,在主要大都市地区之外也是零散的。
所有这些数据集主要集中在建筑物覆盖区(或 OSM 中为道路),并且对城市区域以外的非建筑物特征(例如停车场、树木和太阳能电池板)的覆盖率较低。虽然 OSM 包括非建筑特征,但其覆盖范围在城市地区以外的可靠性甚至不如我们的客户可能感兴趣的建筑足迹和道路。
对于实际上是工业联盟的计划,例如 OMF,只有当其成员继续从中受益时,这些数据集才会更新。不控制我们公司的关键数据源是一个坏主意。
最重要的是,如果我们能够利用这些数据集,那么我们所有的竞争对手也可以。为了保持市场优势,我们需要开发自己的数据集和解决方案。当然,当有意义时,我们可以使用免费许可的数据来扩充和增强我们自己的数据集,但它不应该是我们唯一的数据源。
确定了业务需求后,让我们开始实施。
SAM
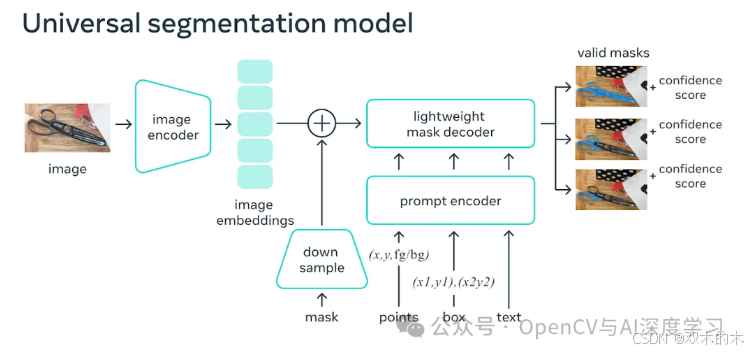
Segment Anything Model (SAM) 是 Meta 于 2023 年 4 月发布的用于图像分割的开源基础模型。它在高分辨率图像上具有出色的零拍摄性能。
虽然它是在高分辨率照片上训练的,但它在卫星图像上的表现还不错。它在小于 1 米的分辨率上效果最佳,并且与基于点的提示(与边界框提示相反)一起使用时效果最佳。毫不奇怪,它可能会遇到与具有相似材料的要素 (如人行道和道路之间的边界) 以及小的不规则要素 (如树木和阴影) 的问题。
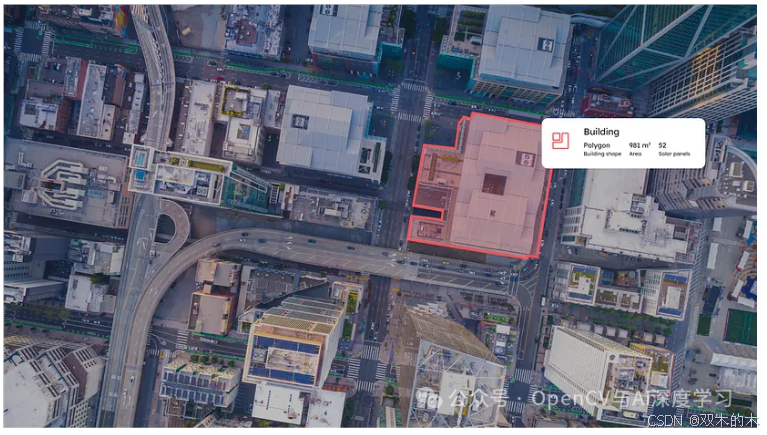
Grounded SAM
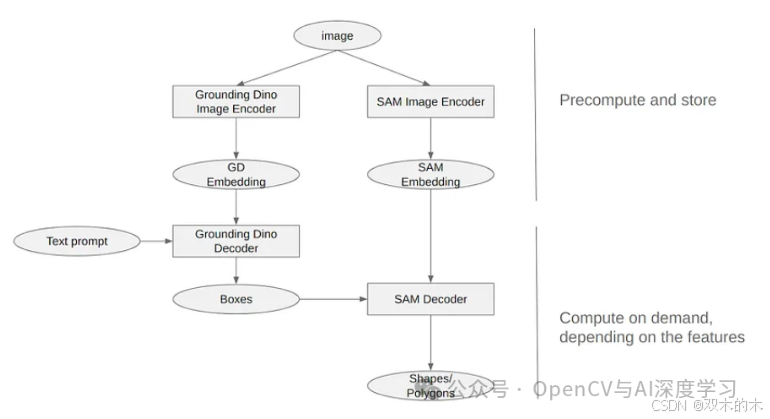
为了知道图像的哪些特征需要分割,我们需要将其与某种对象检测模型相结合。经过一些初步测试,我们使用 Grounded SAM 看到了有希望的结果。
方法相当简单。我们使用 Grounding DINO 和我们想要识别的特征的文本提示生成卫星图像的嵌入。这会在像素空间中生成一个边界框,然后我们可以将其用作 SAM 的提示(或使用边界框的中心作为点提示,因为这更适合卫星图像)。
通过使用带注释的数据微调 Grounding DINO,我们可以进一步提高嵌入性能。然而,即使是零发射性能也出奇地好,因为 Grounding DINO 和 SAM 最初都没有使用卫星图像数据进行训练。


鉴于 Grounded SAM 的零散弹性能,我们乐观地认为,使用手动注释的数据微调 Grounding DINO 编码器将产生改进。由于使用了基础模型,我们的高级架构在概念上相当简单。
计算量最大的步骤是计算每个卫星图像的图像嵌入。尽管我们正在处理的图像在卫星图像方面被认为是高分辨率(每像素 ~30 厘米),但通过图像处理,它们很容易管理。考虑到我们正在使用的分辨率下,一公顷的卫星图像只有大约 350x350 像素,而我们感兴趣的大多数特征甚至比一公顷要小得多。
图像嵌入也只需为每个区域和每种类型的嵌入计算一次,然后可以重复用于针对同一区域的对象检测和分割模型的不同运行。对于一些大都市地区,我们可能需要每隔几个月刷新一次图像,以考虑新建筑,但我们基本上可以将嵌入计算视为一次性成本。
另一个有问题的步骤是 annotation。我们与专业图像注释服务 Encord 合作,对我们从卫星图像提供商处获取的图像进行注释。与计算嵌入一样,尽管注释是一个耗时且昂贵的过程,但它是生成真实数据的唯一可靠方法。随着我们积累带注释的图像,它也将为我们提供竞争优势,因为我们将能够比竞争对手更快地微调我们的模型。
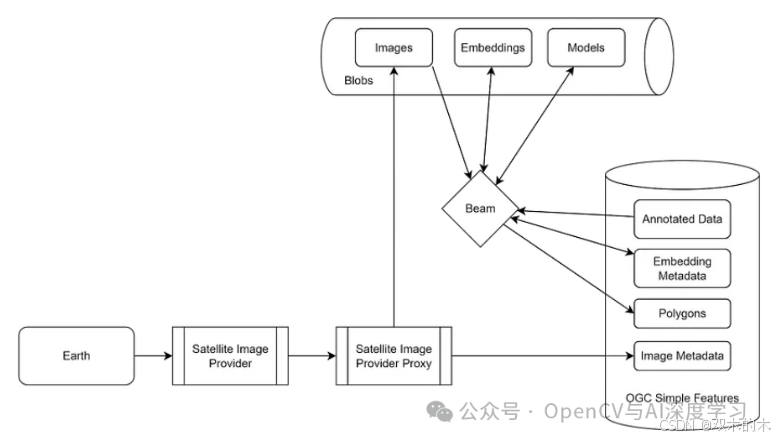
我们使用 Google (GCP) 作为我们的云平台,并选择使用 Apache Beam 作为我们的分布式计算框架来加快处理时间,因为 GCP 为 Beam 提供了一个名为 Dataflow 的执行引擎,该引擎功能相当齐全。由于我们的图像处理管道结合了自定义 Python 库以及大型外部依赖项(如机器学习模型),因此我们需要使用灵活的计算框架(如 Beam 或 Spark),而不是 BigQuery 等结构化程度更高的数据处理平台。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1115
1115

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









