






本文来源公众号“DataFunTalk”,仅用于学术分享,侵权删,干货满满。
原文链接:从Manus到OpenManus:AI产品如何赢得未来?
“ 软件吞噬世界,AI 吞噬软件。 ”
今天咱们来聊一下这两天在AI圈掀起轩然大波的Manus,以及开源版 OpenManus。这两款产品背后的技术细节、市场反应以及它们的未来发展方向,都值得我们探讨一番。
01 Manus:到底有多厉害?
Manus是由中国初创公司Monica.im开发的全球首款通用型AI智能体。它的核心定位是自主执行复杂任务并交付成果,这与传统的AI助手有着本质区别。Manus不仅能提供建议或答案,还能直接交付完整的任务成果,比如生成文件、分析数据、制作报告等。

Manus的技术特点可以总结为以下几点:
-
多代理协同架构:Manus采用“规划-执行-验证”三代理协同模式,能够将复杂任务自主拆解并并行处理。这种架构让它在跨平台数据检索等任务中表现领先竞品20%以上。
-
自主学习与动态优化:Manus能够通过与环境的交互不断学习和优化自身行为,提高任务执行效率和准确性。例如,在处理股票分析任务时,它可以根据市场变化调整分析策略。
-
强大的工具调用能力:Manus可以直接调用各种工具,如浏览器、代码编辑器、数据分析工具等,将用户的想法转化为具体成果。
-
独立运行的计算环境:Manus在云端异步工作,用户无需持续监督,可随时介入调整任务方向,灵活适应动态需求。
Manus的发布在市场上引起了强烈反响。由于其强大的功能和广泛的应用场景,Manus的内测邀请码在二手交易平台被炒到5万元以上的高价。
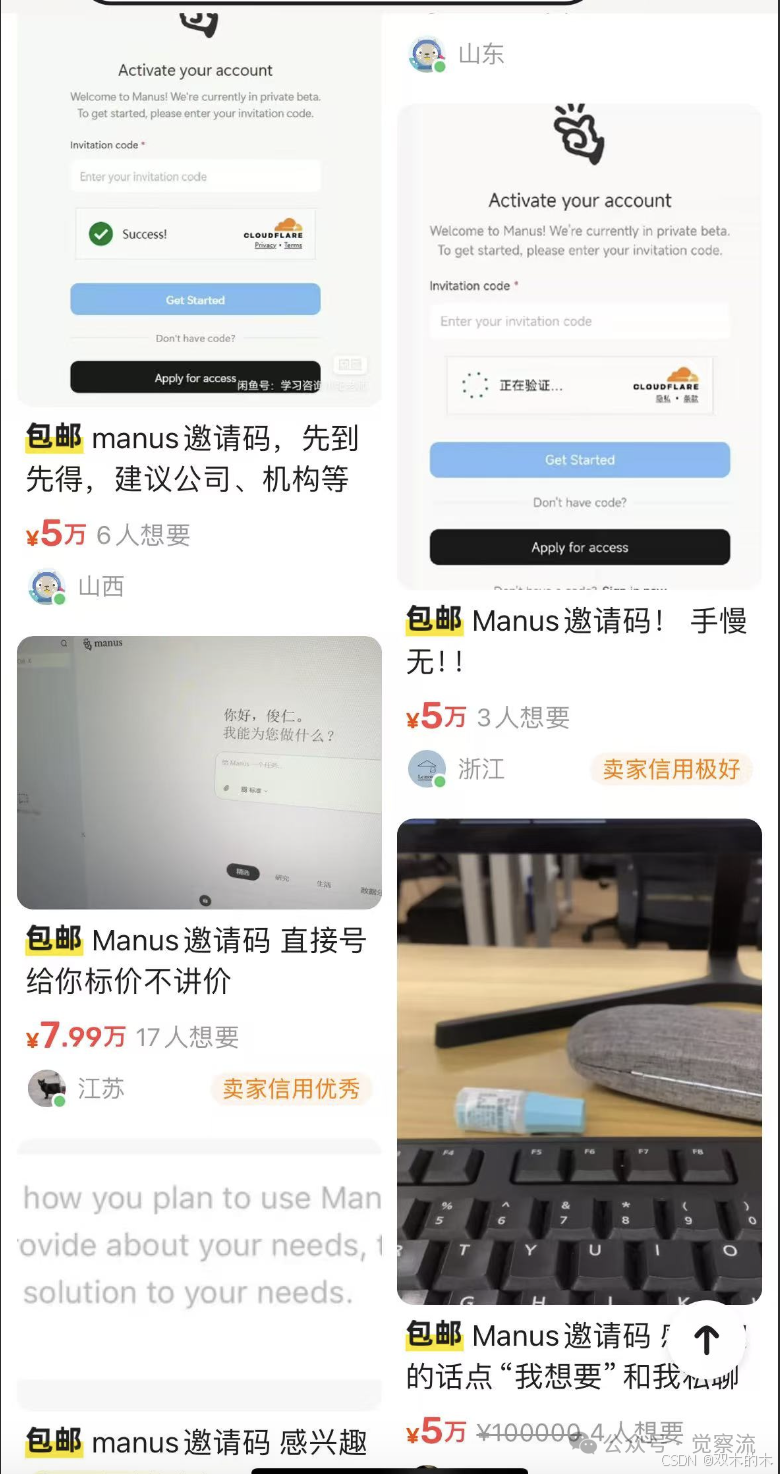
然而,这种封闭的内测模式也引发了一些质疑,许多人对其真实能力只能停留在想象中。
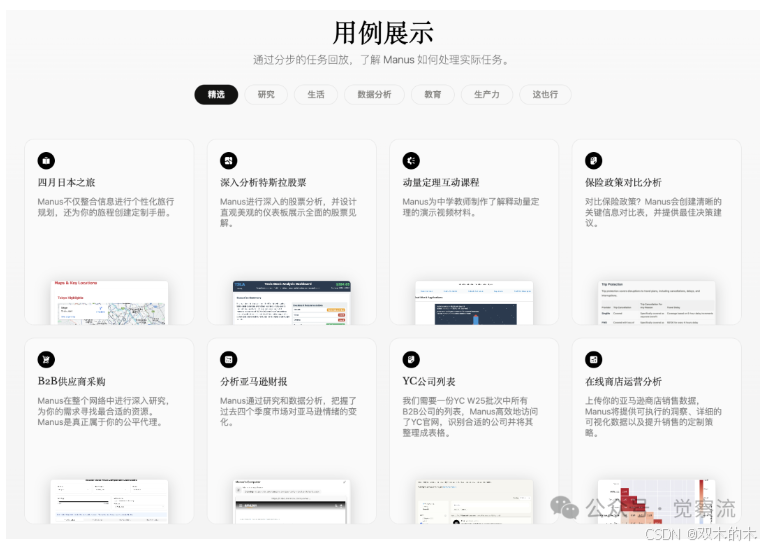
Manus 用例
02 OpenManus:开源的力量
就在Manus引发热议的同时,开源社区迅速行动,推出了OpenManus——Manus的开源复刻版。OpenManus由MetaGPT团队开发。
关联阅读
🔥 MetaGPT 最新产品 MGX - 开启 AI 软件开发新纪元
🔥干不过 AI 就加入它,MGX Agent 前端开发最佳实践-案例
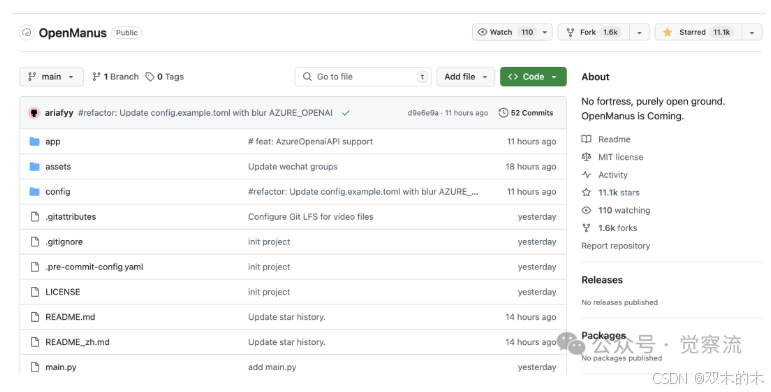
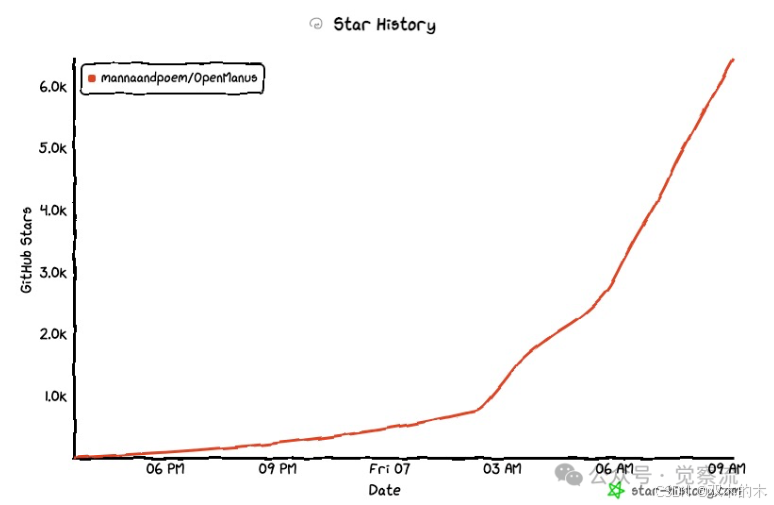
其目标就是复刻Manus的核心功能,同时提供完全开源的代码和无需邀请码的访问权限。这个项目在github上,1天的时间,截至发稿前,⭐️ 星标已突破11.1K。在github上,能在短时间内获得如此多的星标,是一个非常惊人的数字。
并且这个星标的增速没有任何放缓的迹象。(注:图中时间轴时间是美国时间)
OpenManus的主要功能包括:
-
网页浏览与信息检索:通过BrowserUseTool控制浏览器,访问网页并获取信息。
-
文件操作:支持对本地文件的读取、编辑和保存。
-
代码执行:借助PythonExecute工具,用户可以在本地运行Python代码。
-
任务规划与执行:初步支持Plan&ReAct模式,能够根据用户需求进行任务规划并逐步执行。
-
信息汇总与生成:可以根据用户需求生成结构化的报告或文档。
-
本地化操作:直接在用户的电脑上运行,无需依赖云端资源,保障数据隐私和安全性。
OpenManus的核心优势在于其开源性和透明性。用户可以清楚地看到AI的思考过程和任务执行进度。这种实时反馈机制为用户提供了干预的机会,有助于提高任务完成的质量。以下👇🏻是一视频Demo。
03 技术比拼:Manus vs. OpenManus
Manus和OpenManus各有优势,但也存在一些差异:
-
功能深度与稳定性:Manus在功能深度和稳定性上表现更强,尤其是在处理复杂任务时。然而,OpenManus作为一个开源项目,其开放性和灵活性为用户提供了更多的探索和实验空间。
-
实时反馈与透明性:OpenManus的实时反馈机制让用户能够直观地看到AI的每一步操作。这种透明性不仅有助于用户理解AI的工作方式,也为开发者提供了调试和优化的便利。
-
社区驱动:OpenManus是一个彻头彻尾的社区驱动项目。首发开源版本是由MetaGPT团队的Agent研究员,在3小时内构建完成的。用户可以通过提交问题或代码贡献来参与项目发展。这种开放的开发模式加速了项目的迭代,并为AI爱好者和开发者提供了参与技术创新的机会。
04 护城河之争:Manus的未来在哪里?
Manus的护城河可能并不在于技术本身,而在于其强大的用户数据积累和持续优化能力。通过积累用户数据,Manus能够不断优化用户体验,形成一个良性循环。这种基于用户数据的优化不仅能提升用户体验,还能吸引更多用户,最终形成难以撼动的竞争优势。
然而,OpenManus的开源模式也为Manus带来了挑战。开源社区的力量不容小觑,短时间(3小时)就可以复刻Manus的核心能力,OpenManus的快速崛起证明了这一点。除此以外,对于Manus未来面临的挑战,稍作总结如下:
1. 技术层面的挑战
-
模型能力的限制
Manus 的核心能力依赖于其底层模型的推理能力和上下文窗口长度。目前,尽管 Manus 在交互上有创新,但其模型能力可能不足以应对复杂任务的动态调整,导致生成结果趋于平庸。此外,模型的上下文窗口限制也会在资料筛选和整合过程中造成信息损耗。 -
技术实现的可复制性
Manus 的技术架构虽然有一定创新,但整体实现逻辑相对清晰,容易被其他团队模仿和山寨。其核心模块(如任务规划器、任务执行调度器、任务汇总生成器等)依赖于现有的开源模型或技术,缺乏独特性。 -
资源和效率问题
Manus 采用模拟浏览器搜索、点击、滚动并结合视觉识别的方式获取信息,这种方式不仅时间成本高,还可能导致信息缺失。同时,资源消耗较大,难以大规模扩展。
2. 市场竞争层面的挑战
-
竞争对手的技术优势
其他竞争对手(如 OpenAI 的 DeepResearch、Anthropic 的 Claude Sonnet 3.7)通过专门的模型训练和强化学习,已经在特定任务上展现出更强的性能。Manus 在模型训练和强化学习方面的投入相对不足,可能会在市场竞争中处于劣势。 -
“模型即产品”的趋势
当前 AI 行业的趋势是“模型本身即产品”,各大实验室和公司都在向模型训练和强化学习方向发展。Manus 如果不能在模型训练上取得突破,可能会被竞争对手的更强大模型所取代。 -
开源和山寨版本的冲击
随着开源模型的普及和技术实现的透明化,Manus 很快会面临开源版本和商业山寨版本的竞争。这些山寨版本可能会以更低的成本吸引用户,从而稀释 Manus 的市场优势。
3. 用户体验和数据层面的挑战
-
用户体验的可持续性
Manus 的交互设计虽然在初期给用户带来惊艳感,但这种新鲜感可能会很快消退。如果不能持续优化用户体验,用户可能会转向其他更懂他们的产品。 -
数据沉淀的不足
目前 Manus 缺乏足够的用户数据沉淀,难以实现基于用户行为的个性化优化。而竞争对手(如 Perplexity 和 Cursor)正是通过大量用户数据来构建护城河。 -
用户留存和口碑
用户对新技术的热情往往短暂,一旦有更好的替代品出现,用户会迅速流失。Manus 需要通过持续迭代和优化来留住用户,形成良好的口碑。
4. 战略和生态层面的挑战
-
生态位的巩固
Manus 需要快速占据市场生态位,并通过不断迭代和优化来巩固其地位。否则,竞争对手可能会抢先一步占据市场,使其失去先发优势。 -
技术迭代的速度
AI 技术发展迅速,Manus 需要不断跟进最新的模型训练技术和强化学习方法,否则可能会被市场淘汰。
5. 商业模式和盈利层面的挑战
-
成本与收益的平衡
Manus 的技术实现成本较高(如模拟浏览器和视觉识别),而目前 AI 市场的盈利模式尚未完全成熟。如何在高成本和低收益之间找到平衡,是一个重要的挑战。 -
API 服务的局限性
随着闭源 AI 提供商逐渐停止开放 API,Manus 如果依赖外部模型服务,可能会受到限制。未来,Manus 可能需要自己训练模型,以避免被竞争对手“训练”。
综上所述,Manus 面临的挑战不仅来自技术实现和市场竞争,还包括用户体验、数据沉淀、生态位巩固以及商业模式的可持续性。要真正构建自己的护城河,Manus 需要在模型训练、强化学习、用户体验优化和数据积累等方面持续投入和创新。
05 总结:Manus的未来,AI的未来
Manus的出现无疑为AI领域带来了新的可能性,其强大的功能和广泛的应用场景让我们看到了AI技术的巨大潜力。然而,OpenManus的开源模式也让我们看到了开源社区的力量。未来,AI的发展不仅仅是技术的竞赛,更是用户体验、用户体量和数据积累的比拼。
很有意思的是,在“觉察流”社区群,小伙伴们也有一些有趣的对话。我一起贴到下面,分享给大家。
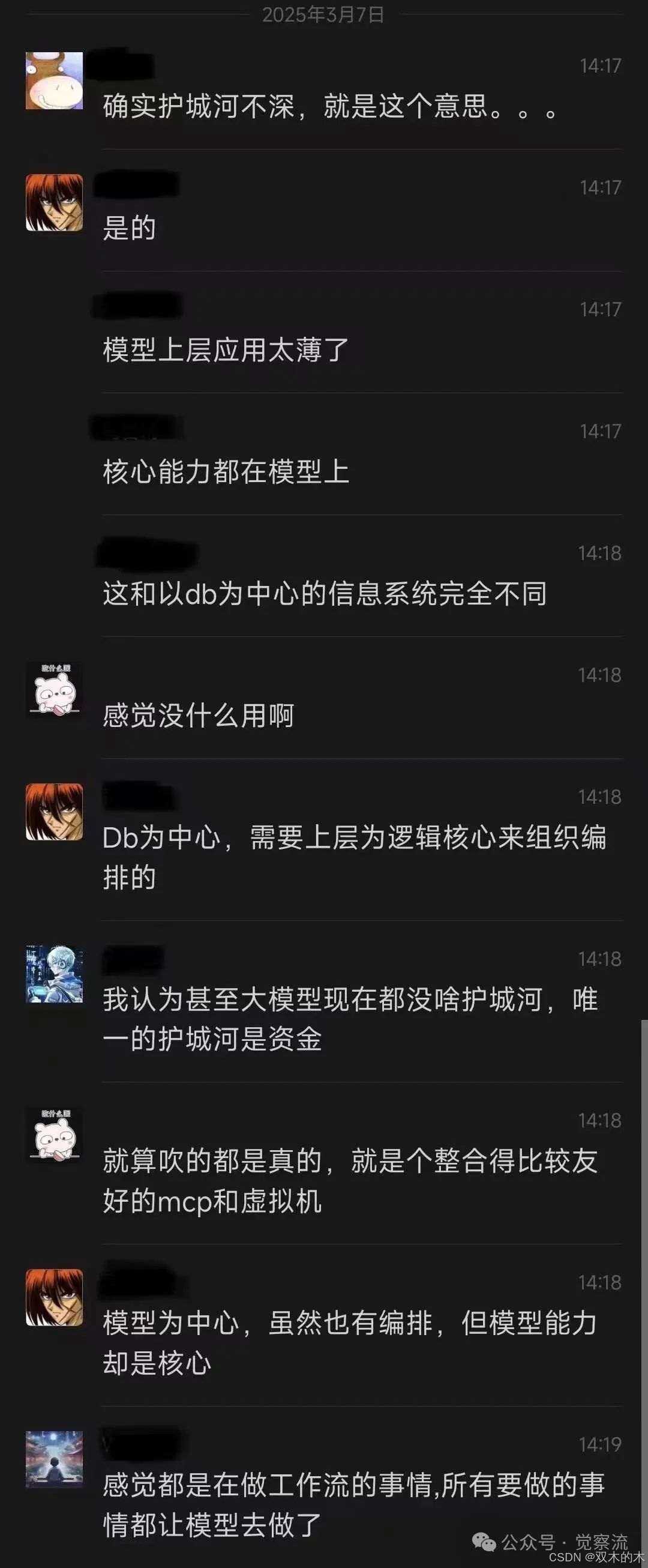 | 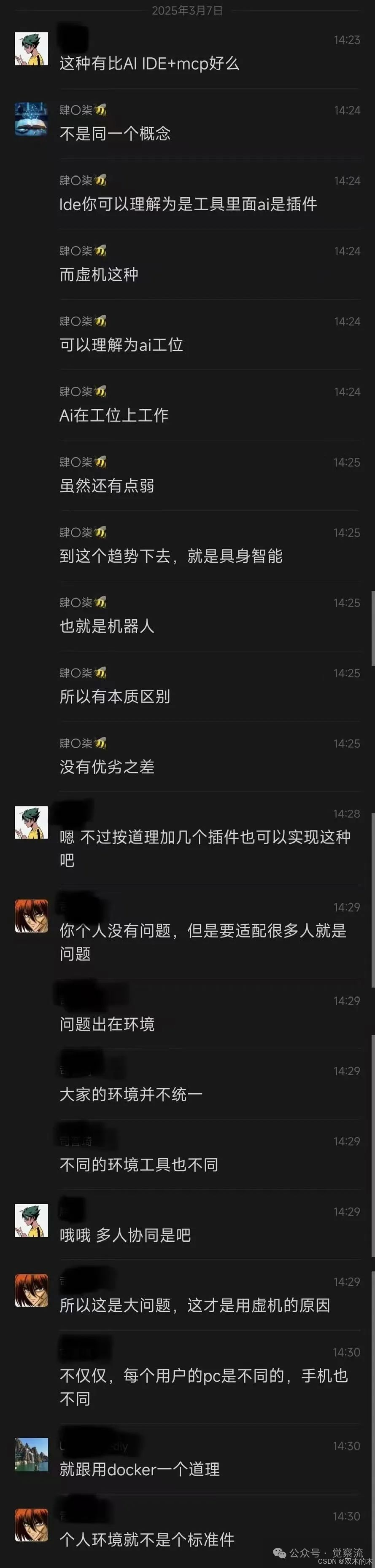 |
看过本文,你有什么想法?欢迎在评论区留言讨论!当然,还可以加入“觉察流”社区群,与群里的小伙伴一起学习、交流。加入方法,私信回复“入群”“加群”即可。
参考资料
https://yage.ai/manus.html
https://mp.weixin.qq.com/s/acMMTj8B1Wl3FSQxDnRR-Q
https://mp.weixin.qq.com/s/ji1YlVNarMfNCF3Fo6BwfQ
https://github.com/mannaandpoem/OpenManus
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 429
429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









