




本文来源公众号“码科智能”,仅用于学术分享,侵权删,干货满满。
原文链接:Meta又一巨作!以人为中心的视觉基础模型:可用于姿势估计、深度估计、身体分割等任务

面向四大任务的人体基础模型
Meta Reality Labs 推出的 Sapiens 是一套专注于人类视觉任务的先进模型系列,这些模型专为 2D 姿势估计、身体部位分割、深度估计和表面法线预测等四项基本视觉任务设计。Sapiens 的一大亮点是其原生支持高达 1K 分辨率的高分辨率推理,这使得模型在处理细节丰富的图像时更为出色。
此外,Sapiens 模型通过在超过 3 亿张自然人类图像上进行预训练,能够轻松通过微调适应各种特定任务。Sapiens 模型的简单设计还带来了可扩展性,当模型参数从 0.3 亿扩展到 20 亿时,跨任务的模型性能得到了显著提升。这一点在多个以人为中心的基准测试中得到了验证,Sapiens 在这些基准测试中持续超越了现有的基线。直接来上视频看效果:
sapiens
论文链接:https://arxiv.org/pdf/2408.12569网页链接:https://about.meta.com/realitylabs/codecavatars/sapiens
1.该基础模型能做到多细致?
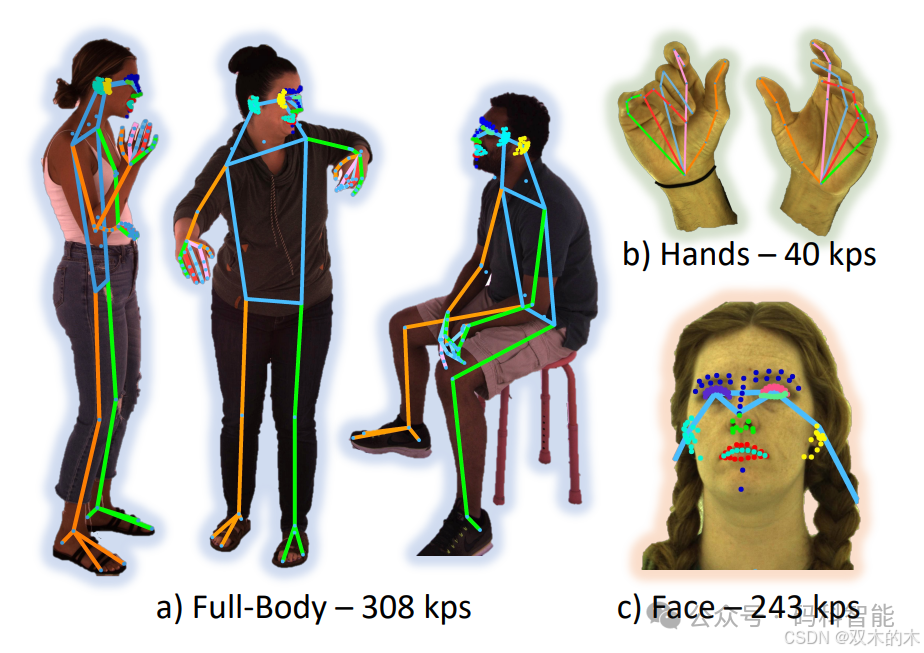
1.1 可预测人体关键点308个
-
全身关键点支持308个,涵盖身体、手、脚、表面和面部。
-
手部关键点支持40个;
-
脸部关键件支持243个;
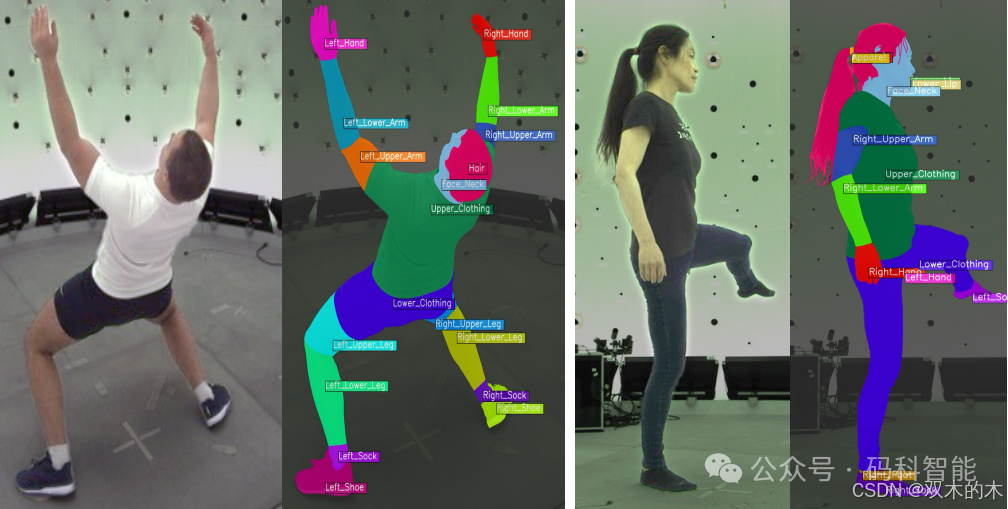
1.2 可分割人体部位28个类别
将分割类别词汇表扩展到28个类别,覆盖头发、舌头、牙齿、上/下唇和躯干等身体部位。
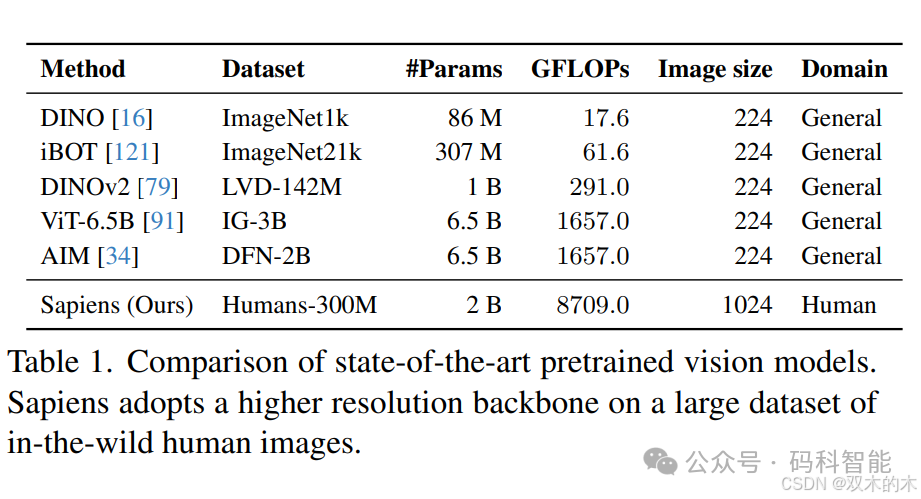
1.3 史无前例的数据量
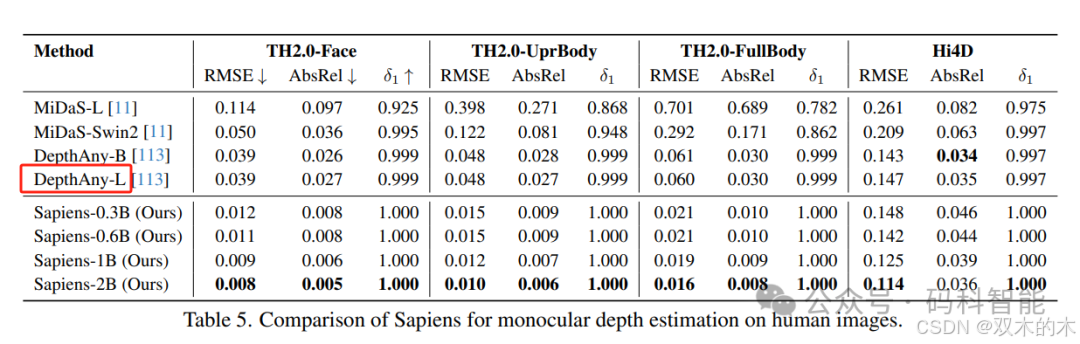
1.4 深度估计怎么样?
模型与现有的最先进单目深度估计器。仅在合成数据上微调的 Sapiens-2B 在所有单人体尺度和多人体场景中显著优于先前的技术。我们观察到与 Hi4D 图像上表现最佳的 Depth-Anything 模型相比,RMSE 降低了 20%。重要的是要强调,虽然基线模型是在各种场景上训练的,但 Sapiens 专门用于以人为中心的深度估计。下图展示了 Sapiens-1B 和 DepthAnything-L 之间深度估计的定性比较。

2. 总结
Sapiens 标志着将以人为本的视觉模型提升至基础模型领域的重大进步。我们的模型在各种以人为中心的任务上展示了强大的泛化能力。我们将模型的最先进性能归因于:(i) 在专为理解人类量身定制的大型精选数据集上进行大规模预训练,(ii) 高分辨率和高容量的视觉变换器主干的扩展,以及 (iii) 对增强的工作室和合成数据的高质量注释。我们相信这些模型可以成为众多下游任务的关键构建块,并向更广泛的社区提供高质量的视觉主干。未来工作的一个潜在方向是将 Sapiens 扩展到 3D 和多模态数据集。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









