






本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:LP-DETR突破DETR瓶颈 | 多尺度自适应注意力实现58%AP新高,揭示检测注意力演进规律

导读
本文提出了LP-DETR(层状渐进式DETR),这是一种通过多尺度关系建模增强基于DETR的目标检测的新方法。LP-DETR通过关系感知的自注意力机制引入了可学习的目标 Query 之间的空间关系,该机制能够自适应地学习平衡解码器层之间不同尺度的关系(局部、中度和全局)。这种渐进式设计使得模型能够有效地捕捉检测 Pipeline 中不断变化的空间依赖关系。
在COCO 2017数据集上的大量实验表明,与标准自注意力模块相比,LP-DETR提高了收敛速度和检测精度。所LP-DETR取得了具有竞争力的结果,使用ResNet-50主干网络在12个epoch时达到52.3%的AP,在24个epoch时达到52.5%的AP,并进一步使用Swin-L主干网络提高至58.0%的AP。此外,作者的分析揭示了一个有趣的模式:模型自然地学会了在早期解码器层优先考虑局部空间关系,同时在更深层次的解码器层逐渐将注意力转移到更广泛的上下文中,为未来目标检测研究提供了宝贵的见解。
1. 引言
DEtection Transformers (DETRs) [1] 通过提出一种端到端的目标检测架构取得了巨大进展。然而,其低效的训练效果仍然是一个关键挑战。根本原因在于训练过程中的监督不平衡——DETR采用匈牙利算法为每个真实框分配一个正预测,将大多数预测作为负样本。这种不足的正监督导致收敛速度慢且不稳定。虽然已经提出了各种方法通过不同的技术途径来解决这一问题,如多尺度特征学习 [2]、去噪训练 [3]、[4]、混合匹配策略 [5]、[6] 和损失对齐 [7]、[8],但它们主要关注局部特征增强或 Query 学习优化,而没有充分探索自注意力中的关系建模潜力。
在视觉领域,建模物体间关系已被证明对检测性能有益。先前的方法主要集中在两个方面:物体类别的共现模式[9]-[12]以及使用各种标准的空间关系[13]-[15]。这些方法已经证明,通过捕捉物体之间的上下文依赖关系,引入关系信息可以有效提高检测精度。然而,在DETR领域,很少有工作研究自注意力中物体 Query 的可学习关系,这是DETR解码器中的一个关键组件。Hao等人[12]试图通过解码器自注意力中的可学习关系矩阵来建模类别相关性,但他们的方法没有考虑空间信息,并且需要将类别到类别的关联映射回 Query 到 Query 的交互。最近,Relation-DETR[16]通过跨层细化引入了边界框之间的显式位置关系。受他们的工作启发,但与这些方法不同,作者直接将几何关系权重纳入每一层的 Query 中,并提出了层特定的关系建模来捕捉不断变化的空间依赖关系。
本文提出了LP-DETR(层状渐进式DETR),通过显式建模解码器层之间的多尺度空间关系来增强目标检测。作者的关键洞察是,物体关系自然地从局部到全局上下文中演变,检测 Pipeline 中的不同尺度的空间关系可能在检测过程的各个阶段扮演不同的角色。基于这一观察,作者提出了一种渐进式关系感知自注意力模块,该模块能够自适应地学习在不同解码器层平衡不同尺度的空间关系。这种设计使得模型能够在早期层捕获细粒度的局部关系,同时在深层逐渐融入更广泛的关系信息。
作者工作的主要贡献有三方面:
-
• 作者引入了一种关系感知的自注意力机制,该机制显式地建模了目标 Query 之间的多尺度空间关系。
-
• 作者提出了一种渐进式细化策略,允许模型自适应地调整解码器层之间的关系权重。
-
• 作者发现并验证了一个有趣的模式,即空间关系通过解码器层自然地从局部进展到全局上下文,为未来的研究提供了有价值的见解。
最后,作者在COCO 2017数据集上进行了广泛的实验,以验证LP-DETR的有效性。LPDETR在12个epoch的训练下,使用ResNet-50作为 Backbone 网络,实现了52.3%的AP;在24个epoch的训练下,AP达到了52.5%。使用Swin-L作为 Backbone 网络时,LP-DETR进一步提升了至58.0%的AP。更重要的是,作者的分析揭示,所提出的渐进式关系建模有助于提高收敛性和检测精度。这些结果验证了作者对层状关系建模重要性的假设,并为未来在目标检测领域的研究指明了有希望的路径。
2. 研究方法
A. DETR 前言

B. 层次渐进式关系感知注意力
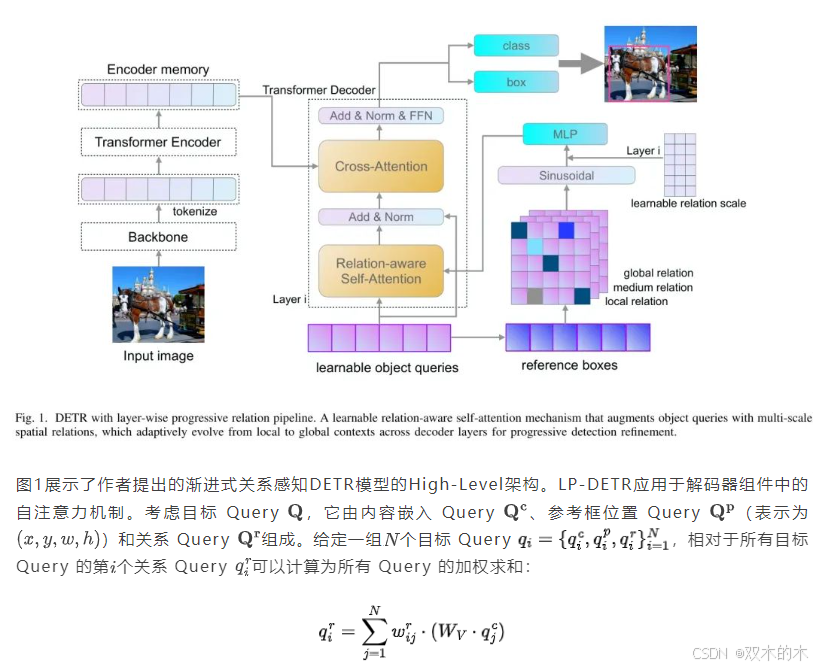

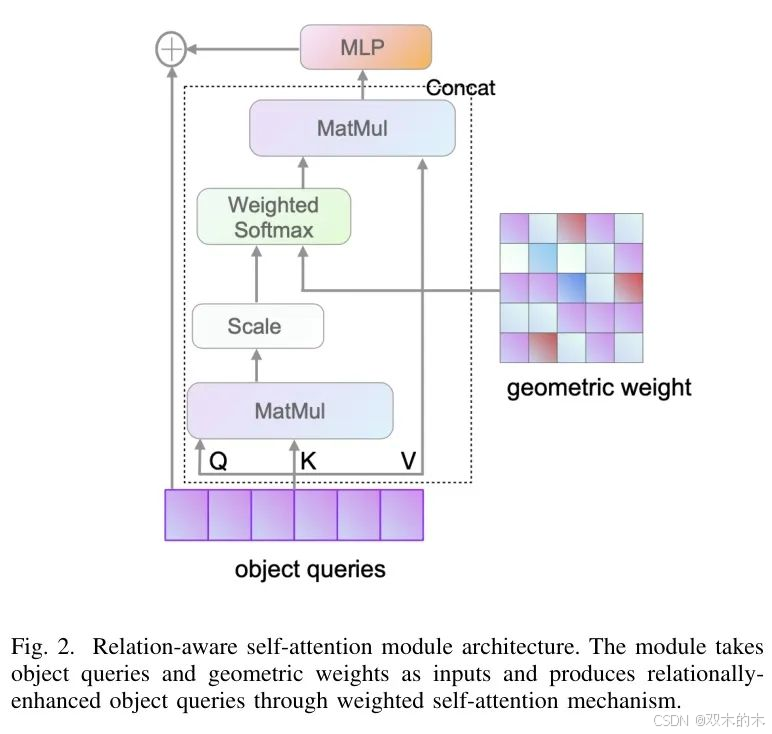
为了探究不同尺度的关系在解码器层中的演变,作者提出了三种关系度量指标:

4. 实验
A. 实验设置
数据集和 Backbone 网络:作者在COCO 2017 [26]数据集上评估了作者的渐进式关系感知DETR,该数据集包含118k个训练图像和5kΩ个验证图像,涵盖了80个物体类别。

B.实验结果
作者在COCO 2017验证数据集上使用ResNet-50 [24]和Swin-L [25]作为 Backbone 网络评估LP-DETR。
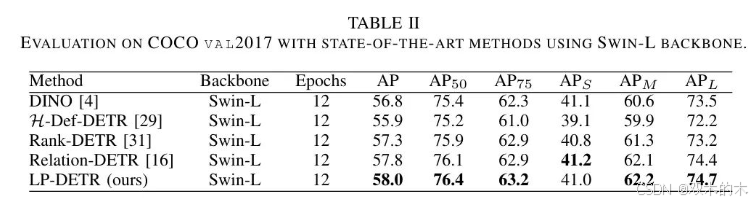
结果总结在表1和表2中。使用ResNet50 Backbone 网络进行12个epoch的训练,LP-DETR实现了具有竞争力的结果,AP达到52.3%,AP50达到69.6%,AP75达到56.8%。与Relation-DETR [16]相比,作者在所有指标上观察到一致的改进(AP提高0.6%,AP50提高0.5%,AP75提高0.5%)。
对不同尺度的物体进行分析表明,LP-DETR在S小物体上实现AP35.8%,M中物体上实现AP55.9%,L大物体上实现AP66.6%,在中等物体(APM提高0.3%)和大物体(APL提高0.5%)上取得了显著提升,同时在小物体上保持了具有竞争力的性能(APS降低0.3%)。这些改进在24个epoch的训练中更为明显,LP-DETR进一步超越了Relation-DETR,AP提高0.4%,AP50提高0.3%,AP75提高0.6%。此外,LP-DETR在更大 Backbone 网络上表现出强大的可扩展性。在12个epoch的训练下,使用Swin-L Backbone 网络,作者实现了58.0%的AP,76.4%的AP50和63.2%的AP75,在AP、AP50和AP75上均优于Relation-DETR的前期最佳结果,分别提高了0.2%,0.3%和0.3%。
C. 消融研究
关系头数量分析。作者研究了关系头数量如何影响作者的关系感知自注意力模块的模型性能。表1000l展示了在保持总共有8个注意力头的情况下,不同关系头数量的结果。不使用关系头(0头)作为作者的 Baseline ,其中该模块作为标准自注意力模块运行,实现了51.1%的AP、68.6%的AP50和55.8%的AP75。随着关系头数量的增加,性能持续提升。当所有8个头都用于关系感知注意力时,LP-DETR达到了最佳性能,AP为52.3%,相较于 Baseline 提升了1.2%的AP。在AP50(+1.0%)和AP75(+1.0%)上也观察到了相当的增长。这些结果证明了在自注意力机制中引入关系感知注意力的好处。
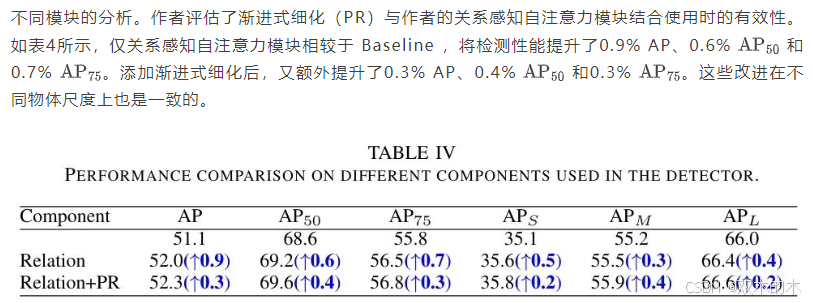
D. 逐步细化分析
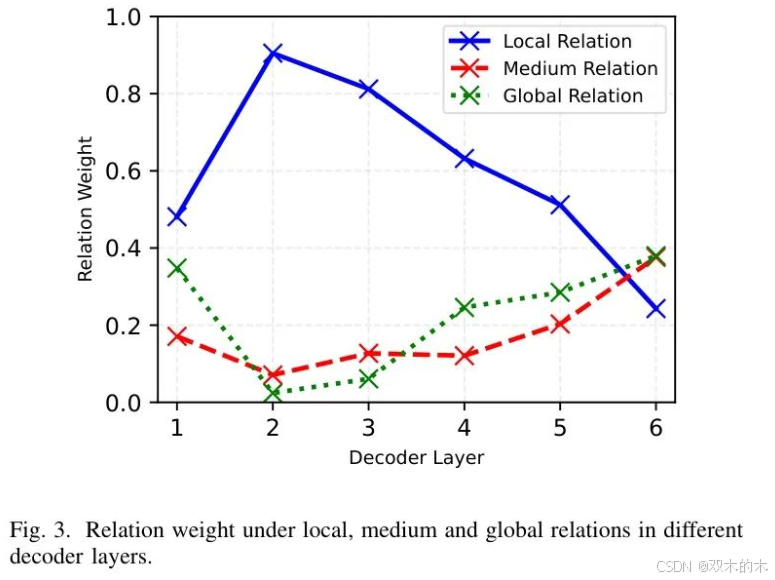
为了理解不同尺度的位置关系(局部、中等和全局)如何通过解码器层演变,作者在图3中可视化了层间学习到的关系权重。作者的分析揭示了一个有趣的模式,即模型在平衡不同空间关系方面的做法。在第一层,三个尺度的权重保持相对相似,这表明在关系尺度选择上存在初始的不确定性。从第二层开始,模型对局部关系产生了强烈的偏好,权重超过0.9,表明早期的解码器层主要关注建立 Query 之间的局部关系。随着向更深层的过渡,作者观察到注意力分布的逐渐转变:局部关系权重降至0.24,而中等和全局关系权重稳步上升到约0.4。到最后一层,中等和全局关系的权重超过了局部关系。这种从局部到更广泛空间背景的渐进过渡与直观理解相符,即目标检测需要层次化处理——从局部到全局 Query 交互。这些发现为未来关系建模的研究提供了有希望的思路,因为从局部到全局关系的清晰层间进展表明,可能存在更有效的架构,这些架构明确利用了这种层次模式。
E. 收敛性比较
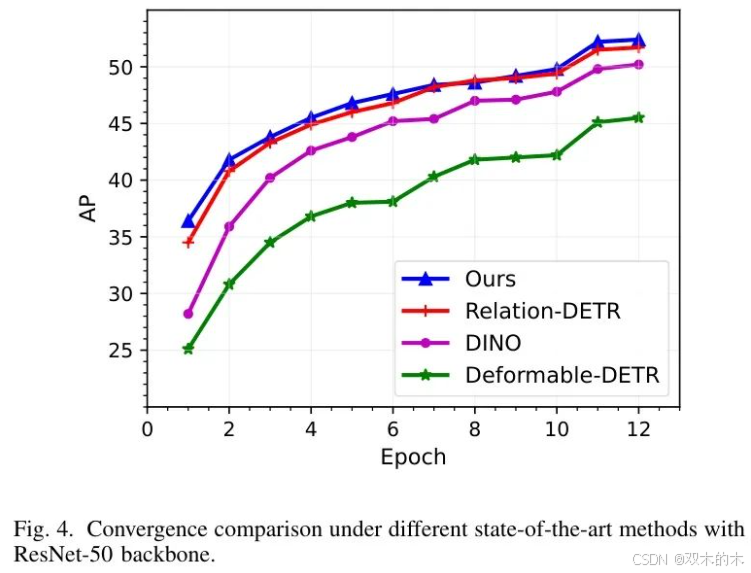
图4绘制了不同最先进方法与ResNet-50主干网络结合下的收敛曲线。LP-DETR展现出改进的收敛行为,这得益于目标 Query 之间学习到的层依赖的多尺度空间关系。尽管相对于Relation-DETR的绝对AP提升适中(+0.6% AP),LP-DETR在整个训练过程中始终优于 Baseline (DINO和Deformable-DETR)。这证明了引入层依赖的多尺度空间关系可以有效优化原始的关系建模,用于目标检测。
4. 结论
本文提出了一种渐进式关系感知自注意力模块,通过引入可学习的多尺度空间关系来增强DETR检测器。LP-DETR能够自适应地调整不同尺度和解码层之间的关系权重,在标准基准测试中实现了有竞争力的性能。通过大量实验,作者证明了与标准自注意力相比,作者的模块提高了收敛速度和检测精度。作者的分析揭示了空间关系在网络中演变的模式:在早期解码层中,局部关系占主导地位,而在更深层的解码层中,全局关系变得越来越重要。作者的发现为未来的研究开辟了几个有前景的方向。
参考
[1]. LP-DETR: Layer-wise Progressive Relations for Object Detection
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 718
718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









