






本文来源公众号“集智书童”,仅用于学术分享,侵权删,干货满满。
原文链接:边缘AI革命!MicroViT 革新轻量视觉Transformer:3.6倍速+40%能效提升,突破边缘部署极限

导读
视觉Transformer(ViT)在各种计算机视觉任务中展现了最先进的性能,但其高计算需求使其在资源有限的边缘设备上不切实际。本文提出了MicroViT,这是一种轻量级的视觉Transformer架构,通过显著降低计算复杂度,同时保持高精度,针对边缘设备进行了优化。MicroViT的核心是高效单头注意力(ESHA)机制,该机制利用分组卷积来减少特征冗余,并仅处理部分通道,从而减轻了自注意力机制的负担。MicroViT采用多阶段MetaFormer架构进行设计,通过堆叠多个MicroViT编码器来提升效率和性能。在ImageNet-1K和COCO数据集上的全面实验表明,MicroViT在保持与MobileViT系列相当精度的同时,显著提高了3.6倍的推理速度,并提高了40%的效率,减少了能耗,使其适用于移动和边缘设备等资源受限的环境。
1. 引言
近年来,Transformer在计算机视觉领域受到了广泛关注,并取得了显著成就。该领域的一个显著发展是视觉Transformer(ViT)[1]的引入,它利用纯Transformer进行图像分类任务。继ViT之后,提出了多个模型以提高性能,在包括图像分类、目标检测和分割等在内的多种视觉任务中取得了有希望的结果[2]-[6]。
尽管vanilla Vision Transformer(ViT)[1]表现强劲,但在处理ImageNet分类任务时,它需要介于8500万到6.32亿个参数。其前向传播需要大量的计算资源,导致推理速度缓慢,使其不适合许多特定应用。在内存、处理能力和电池寿命受限的低成本环境中,如移动和边缘设备上应用Transformer模型尤其具有挑战性[7]。因此,作者的工作重点在于构建一个轻量级且高效的深度学习模型,以降低计算需求和功耗,同时确保在边缘设备上实现快速推理和高性能。
多项研究尝试通过将视觉Transformer与卷积神经网络(CNNs)集成来降低其计算复杂度[8]、[9]。例如,MobileViT在早期阶段使用MobileNetV2的倒置 Bottleneck 卷积块[10],以降低ViT的计算复杂度。众多研究[11]-[13]指出,自注意力(SA)机制,尤其是在Transformer的空间特征混合器中,是最耗计算的资源。金字塔视觉Transformer(PVT)通过应用空间缩减注意力(SRA)来缩短 Token 长度,从而降低了SA的二次复杂度(O(n^2))。MobileViTv2提出了可分离线性注意力[12],以减轻SA的负担,而EdgeNeXt[13]则采用转置SA来解决边缘设备实现的复杂度挑战。另一种方法,SHViT,提出多头自注意力(MHSA)可能在头之间出现特征冗余,并引入了仅处理四分之一图像 Token 或特征的单头注意力。然而,这些方法大多数都是独立开发的,没有考虑在边缘计算设备等有限资源环境中的功耗。
本文介绍了Micro ViT,这是一种针对边缘设备部署优化的新型视觉Transformer模型。该模型通过使用高效单头注意力(ESHA)显著降低了计算复杂度和功耗,通过分组卷积和单头SA最小化特征冗余,仅处理整体通道的四分之一。MicroViT建立在MetaFormer架构之上,确保在边缘设备上进行快速推理和低功耗使用,同时保持高精度,使其非常适合能量受限的环境。
2. 提出方法
MicroViT新型视觉模型的主要思想是降低图像特征处理的计算复杂性和冗余。MicroViT模型集成了高效单头注意力(ESHA)技术,该技术能够以低复杂度SA生成低冗余的特征图。
A. 高效单头注意力(ESHA)
ESHA将局部和全局空间操作结合在一个块中,以实现高效的 Token 信息提取。与原始SA不同,原始SA使用线性或PWConv来形成 Query 、 Key和Value ,而ESHA使用基于核的分组卷积进行局部信息获取。在SA中, Token 经过缩放点积操作以检索全局特征上下文。
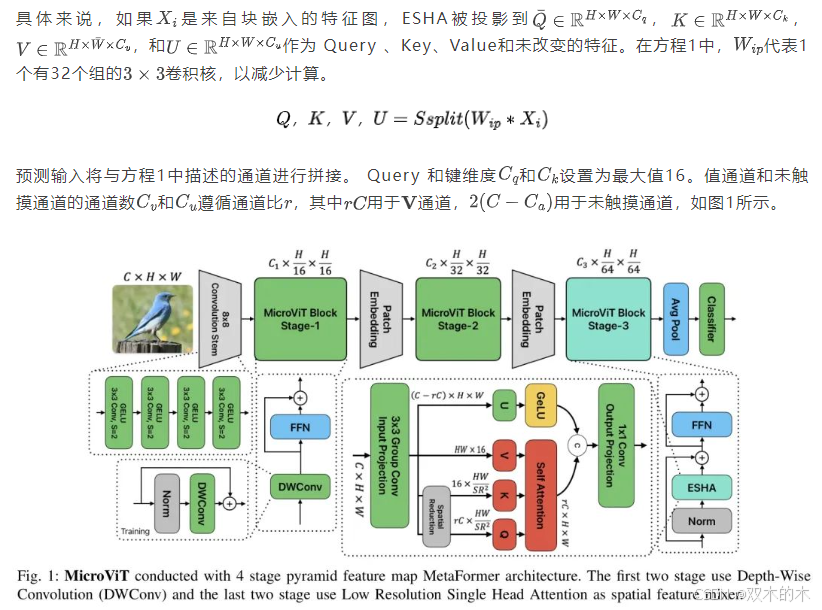

B. 总体架构
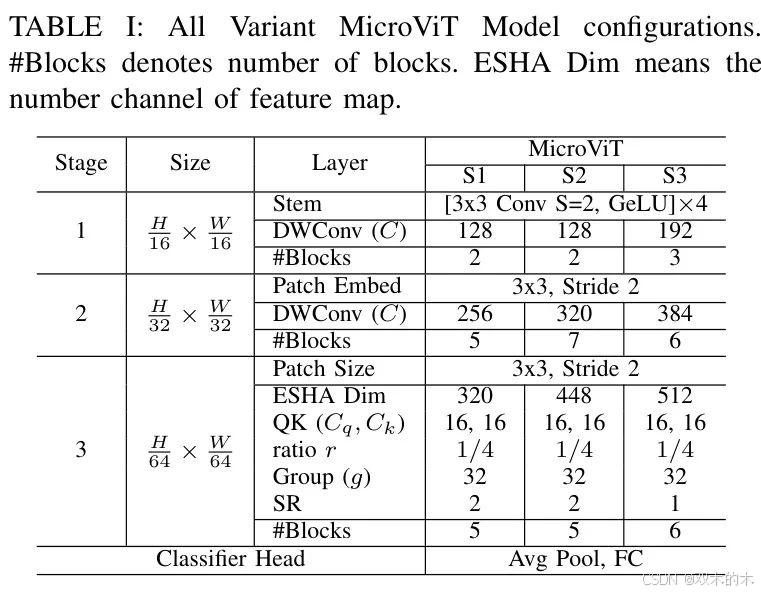
MicroViT采用了三阶段的金字塔结构,起始阶段是一个16x16的茎干,包含四个3x3的卷积,以16倍的比例缩小特征。采用MetaFormer [18]框架,它使用了两个残差块进行空间混合,随后通过残差 FFN (FFN)进行通道混合,具体内容如方程5所述。

MicroViT模型采用一系列可分离卷积和一个残差全连接神经网络(FFN)进行图像块嵌入,第二阶段采用32倍降采样率,第三阶段采用64倍降采样率,并使用3x3图像块嵌入。在早期阶段,深度可分离卷积(DW convolution)作为空间混合器以满足更高的内存需求。最终阶段利用表1中概述的高效单头注意力(ESHA)机制。批归一化(Batch Normalization,BN)用于更好地与相邻的卷积层集成并减少 Reshape ,从而提高推理速度。该架构使用全局平均池化,随后通过全连接层进行特征提取和分类。
3. 结果
为了评估MicroViT,使用了包含128万张训练图像和5万张验证图像,涵盖1000个类别的ImageNet-1K数据集[19]。遵循DeiT的训练方法[20],模型在224x224的分辨率下训练了300个epoch,初始学习率为0.004,并使用了多种数据增强。使用了AdamW优化器[21],批大小为512,在三个A6000GPU上运行。
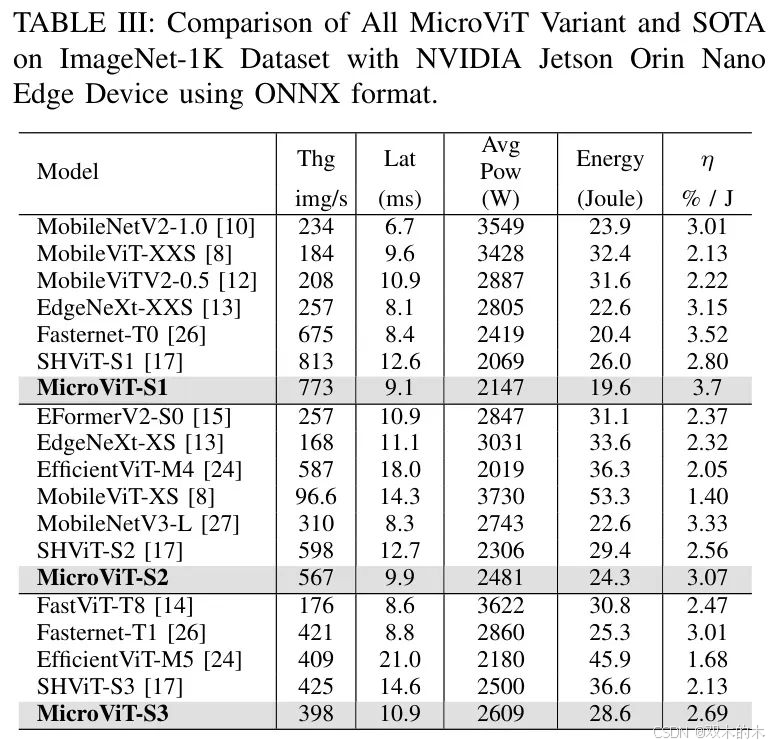
作者评估了模型在不同计算环境中的吞吐量,包括GPU(RTX-3090)、CPU(Intel i5-13500)以及Jetson Orin Nano边缘设备。对于吞吐量,GPU和CPU的批次大小为256,而边缘设备使用ONNX Runtime,批次大小为64。为了提高推理性能,尽可能地将BN层与相邻层融合。在Jetson Orin Nano上,作者还检查了在1000张图像的延迟测试中,保持一致分辨率时的功耗和能耗。
作者进一步在COCO数据集[22]上使用RetinaNet[23]评估MicroViT,并进行12个epoch(1x计划)的训练,遵循[24]在mmdetection[25]中使用的配置。在目标检测实验中,作者采用AdamW[21],批大小为16,学习率为1x10^-3,权重衰减率为0.025。
A. ImageNet-1K 分类结果
表2展示了在ImageNet-1K数据集上,各种MicroViT变体与最先进(SOTA)模型的比较。评估重点在于模型的计算效率和准确性,突出了资源消耗与性能之间的权衡。
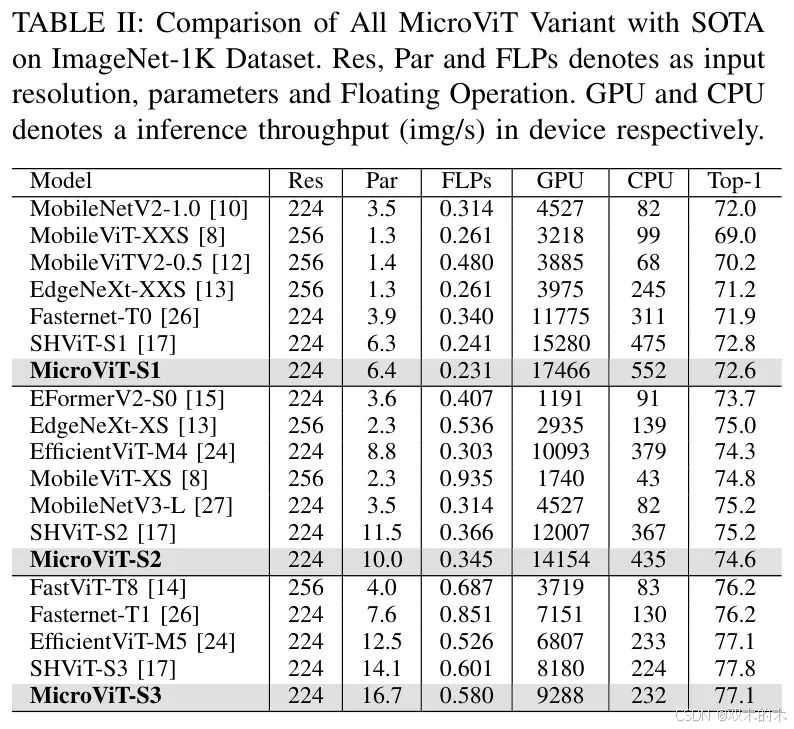
MicroViT-S1在性能上优于传统的CNN模型,超越了MobileNetV2-1.0 [10]和Fasternet-T0 [12],在GPU上的速度提升了3.6倍,在CPU上提升了6.7倍,同时保持了比MobileNetV2-1.0高0.8的准确率。此外,MicroViT-S2在效率指标相似的情况下,超越了EfficientFormerV2-S0 [15]和EfficientViT-M4 [24]等移动 Transformer ,实现了0.3%的更高准确率。在整个MicroViT模型系列中,CPU的吞吐量非常稳定,特别是MicroViT-S1达到了552img/s ,这比几个EfficientViT变体快了8倍,展示了MicroViT对高端GPU和CPU设置的适应性。

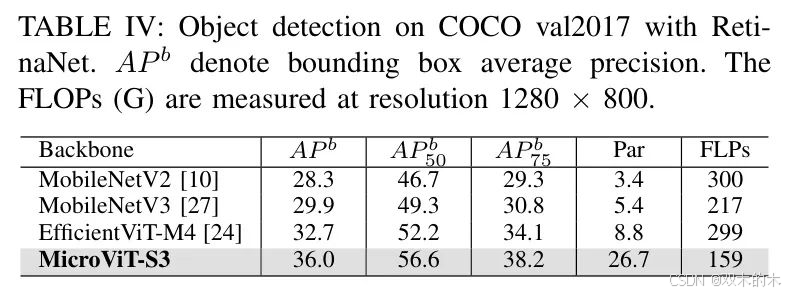
B. 目标检测结果
作者将MicroViT-3与高效的模型[10]、[24]、[27]在COCO[22]目标检测任务上进行比较,并在表4中展示了结果。具体来说,MicroViT-3在具有可比Flops的情况下,AP值比MobileNetV2[10]高出7.7%。与EfficientViT-M4相比,作者的MicroViT-3使用了46.8%更少的Flops,同时AP值提高了3.3%,这证明了其在不同视觉任务中的能力和泛化能力。
4. 结论
本文介绍了MicroViT,这是一种针对边缘设备优化的新型轻量级视觉Transformer架构,考虑了计算能力和能效。通过采用高效单头注意力(ESHA)机制,MicroViT在保持视觉任务中具有竞争力的准确率的同时,实现了计算复杂度和能耗的显著降低。在ImageNet-1K和COCO数据集上的大量实验表明,MicroViT不仅提高了3.6倍的吞吐量和推理速度,而且在边缘设备上的效率和性能方面超过了多个MobileViT模型,效率提升了40%。这些结果证实,MicroViT是部署视觉Transformer在资源受限环境中的一种有前景的解决方案。未来的工作将探索对该架构的进一步优化以及在其他边缘计算任务中的更广泛应用。
参考
[1]. MicroViT: A Vision Transformer with Low Complexity Self Attention for Edge Device
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1906
1906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









