






本文来源公众号“Coggle数据科学”,仅用于学术分享,侵权删,干货满满。
原文链接:行业落地分享:RAG范式选择与系统设计
今天我们来聊聊 RAG(Retrieval-Augmented Generation) 的基本范式选择与系统设计。RAG 是近年来自然语言处理领域的热门技术,它将信息检索与生成模型结合,极大地提升了模型在问答、对话等任务中的表现。
我们为什么需要RAG?
大语言模型(LLM)如 GPT 系列在自然语言处理领域取得了巨大成功,但它们也面临一些根本性问题。RAG(Retrieval-Augmented Generation)技术的出现,正是为了解决这些痛点。

LLM 的两个核心问题
-
再训练成本高
-
世界在变化:现实世界的数据分布不断变化(Distribution Shift / Concept Drift 等),而 LLM 的训练数据是静态的,导致模型容易过时。
-
牵一发而动全身:基于反向传播训练的 LLM,任何微小的调整都可能影响整体模型性能,导致再训练成本极高。
-
训练结束即过时:对于通用模型而言,训练完成的那一刻,模型的知识就已经开始落后于现实世界的变化。
-
-
幻觉问题
-
自回归概率模型的局限性:LLM 是自回归概率模型,其生成内容基于概率分布,而非真实世界的确定性知识。
-
无法彻底根除幻觉:尽管可以通过一些方法缓解幻觉问题,但无法完全消除。模型可能会生成看似合理但实际错误的内容。
-
主流 LLM(如 GPT)是基于 Transformer 架构的自回归模型,本质上是条件概率模型。理论上,通过调整输入提示(prompt),我们可以让 LLM 生成任何可能的 token 组合。

RAG 利用检索技术(如 SQL、搜索引擎、向量数据库、Elastic Search 等)从外部知识源中动态获取相关文档。这些文档作为 prompt 的补充材料,为生成过程提供更丰富的上下文。
Semantic Search 到底在做什么?
语义搜索(Semantic Search)是现代信息检索和自然语言处理中的核心技术之一。它的目标是通过理解文档和查询的语义,找到最相关的内容,而不仅仅是依赖关键词匹配。

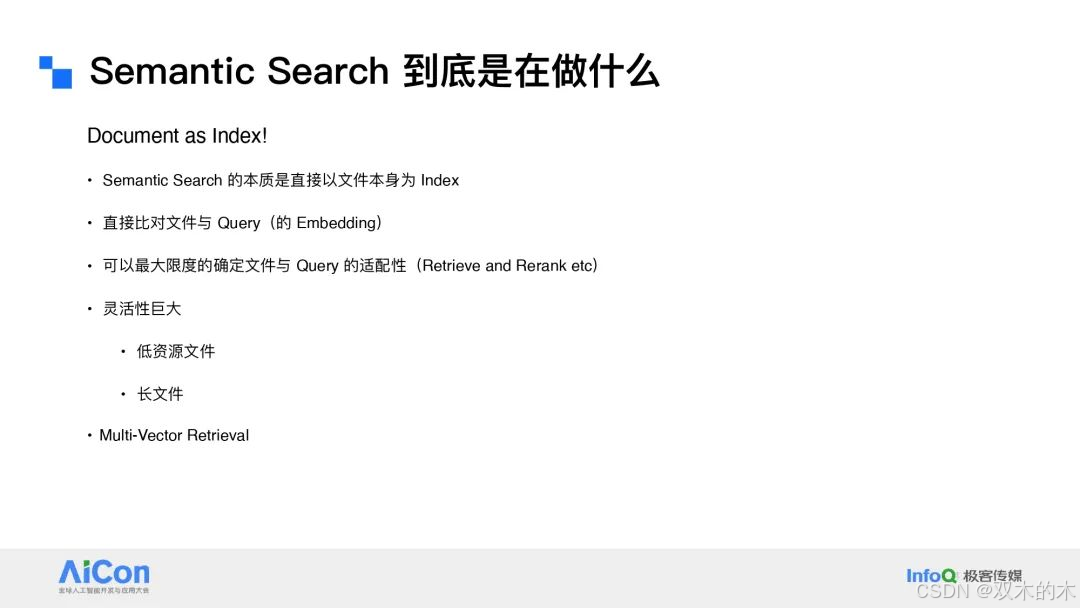
语义搜索的核心价值在于:
-
理解语义:通过捕捉文档和查询的深层语义,超越传统的关键词匹配。
-
灵活性:支持多种距离度量方式,适应不同的应用场景。
-
高效检索:在高维空间中快速找到最相关的文档,提升检索效率。
语义搜索的核心思想是直接将文件本身作为索引,而不是依赖传统的关键词索引。通过将文档和查询映射到同一语义空间(如通过 Embedding 模型),可以直接比较它们的语义相似性。

-
多向量检索(Multi-Vector Retrieval):通过多个向量表示文档的不同部分,进一步提升检索精度。
-
重排序阶段:对候选集进行精细排序,找到最相关的结果。
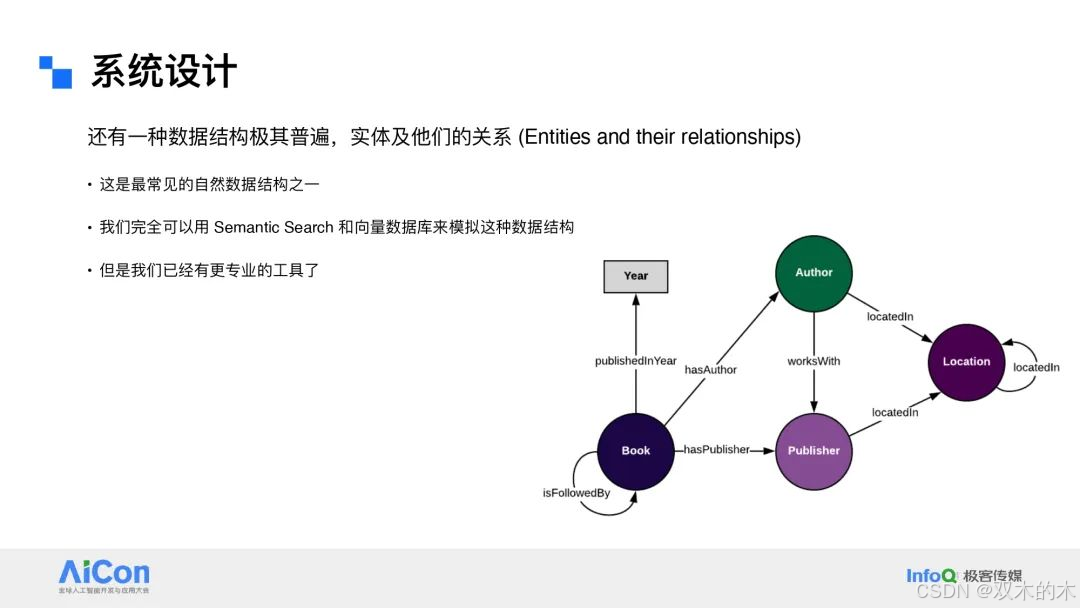
要快速检索一批数据,我们需要对数据进行结构化处理。传统数据库通过以下方式实现高效检索:
-
数据结构:使用树、图、哈希表、实体关系模型等数据结构。
-
归纳偏置(Inductive Bias):不同类型的数据适合不同的数据结构,这种偏置能够显著提升检索效率。
然而,Naive RAG(基于语义搜索的简单实现) 本身缺乏系统化的数据结构:
-
无结构化检索的局限性:语义搜索依赖于向量空间中的距离计算,但很多数据并不适合这种完全无结构的检索方式。
-
效率问题:在大规模数据场景下,无结构化检索可能导致效率低下。
系统设计


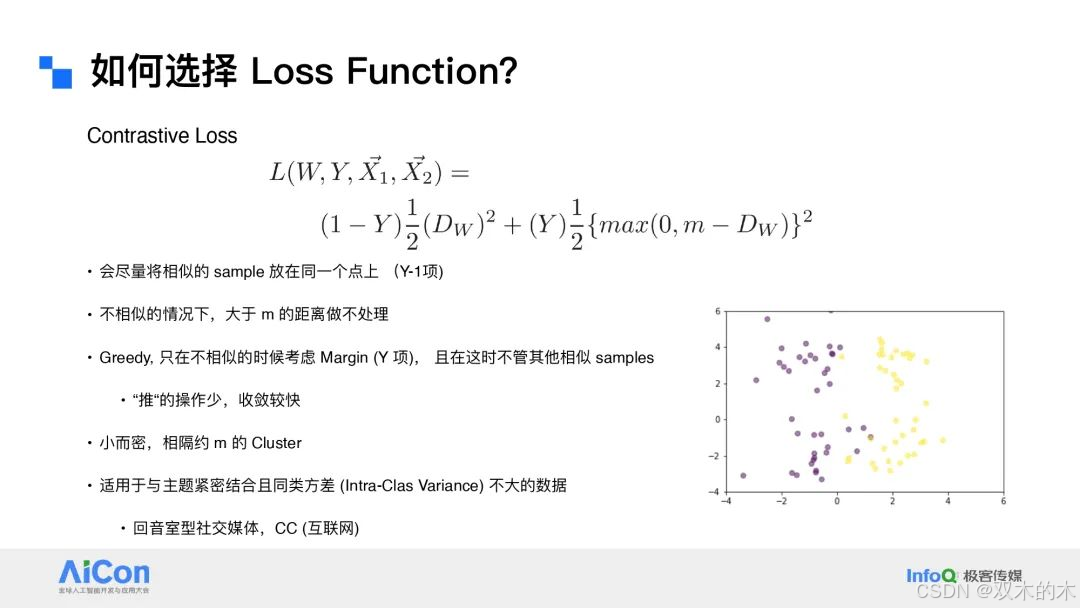

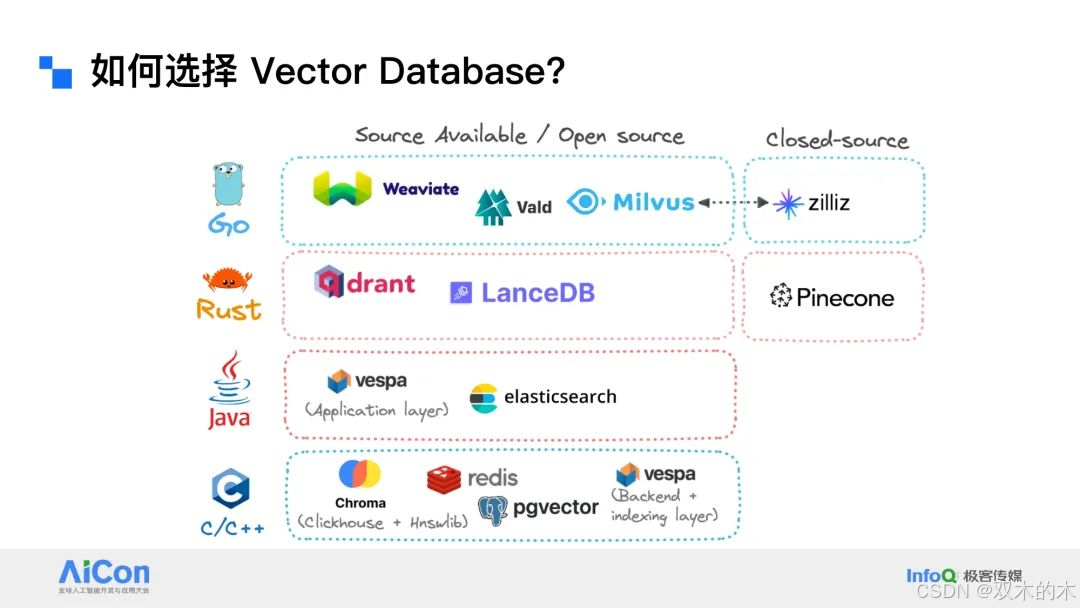
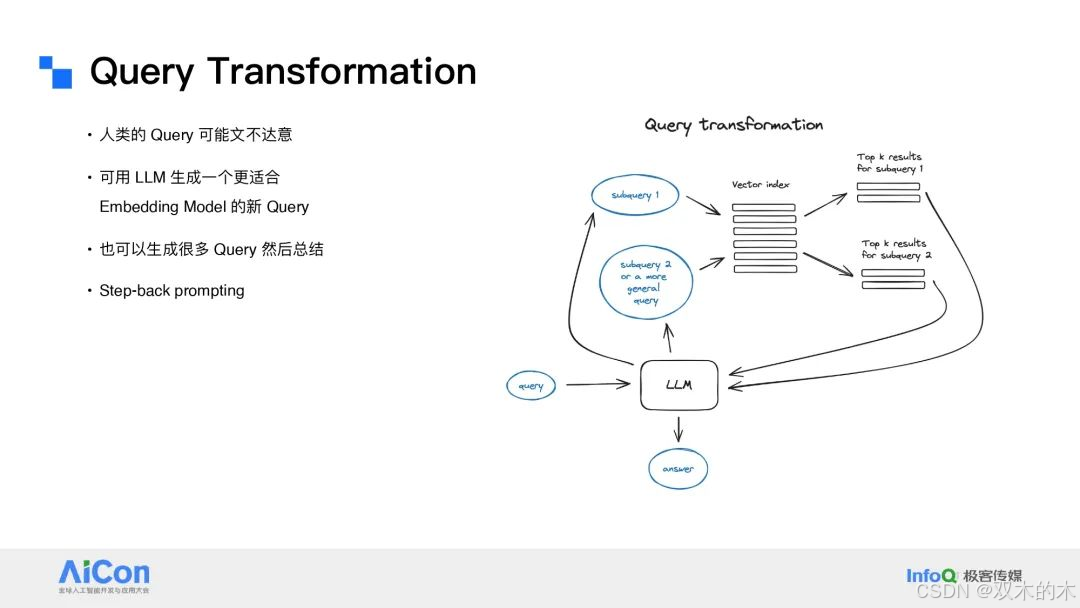
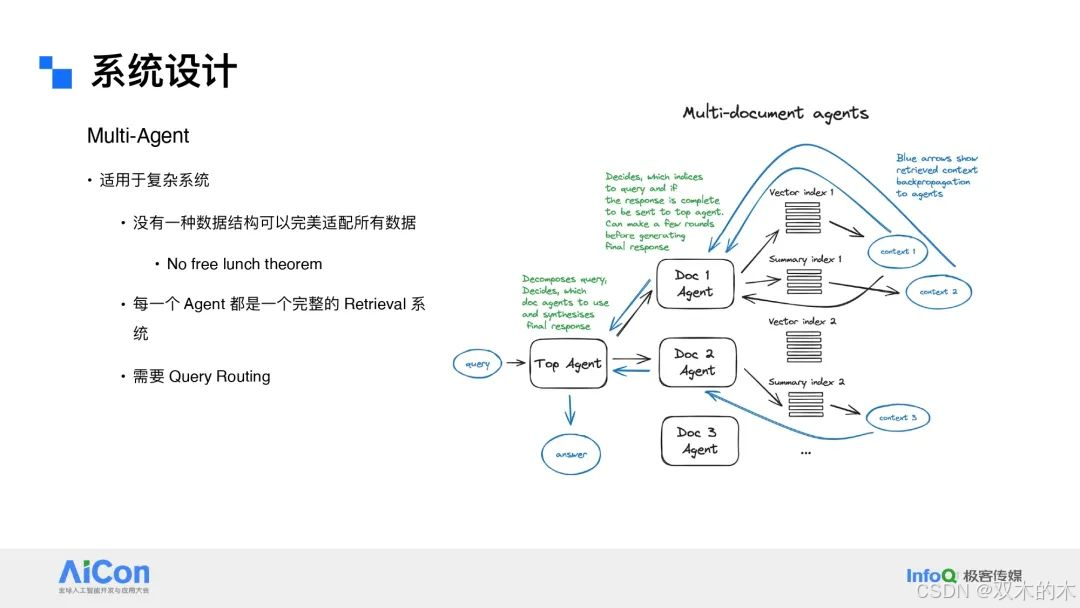
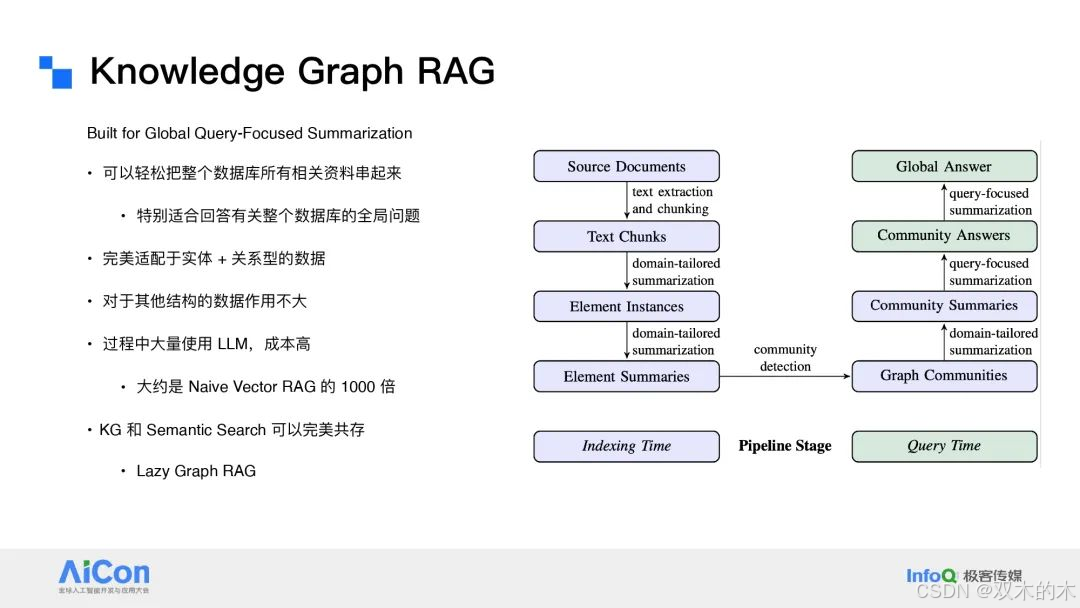
KG RAG
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









