






本文来源公众号“AI生成未来”,仅用于学术分享,侵权删,干货满满。
原文链接:字节提出VideoWorld!从自回归视频生成模型获取世界知识!
【题外话】大年初一新年好!给大家拜年了!祝大家前(钱)途无量!

论文名:VideoWorld: ExploringKnowledge Learning from Unlabeled Videos
论文链接:https://arxiv.org/pdf/2501.09781
开源代码:https://maverickren.github.io/VideoWorld.github.io/
导读
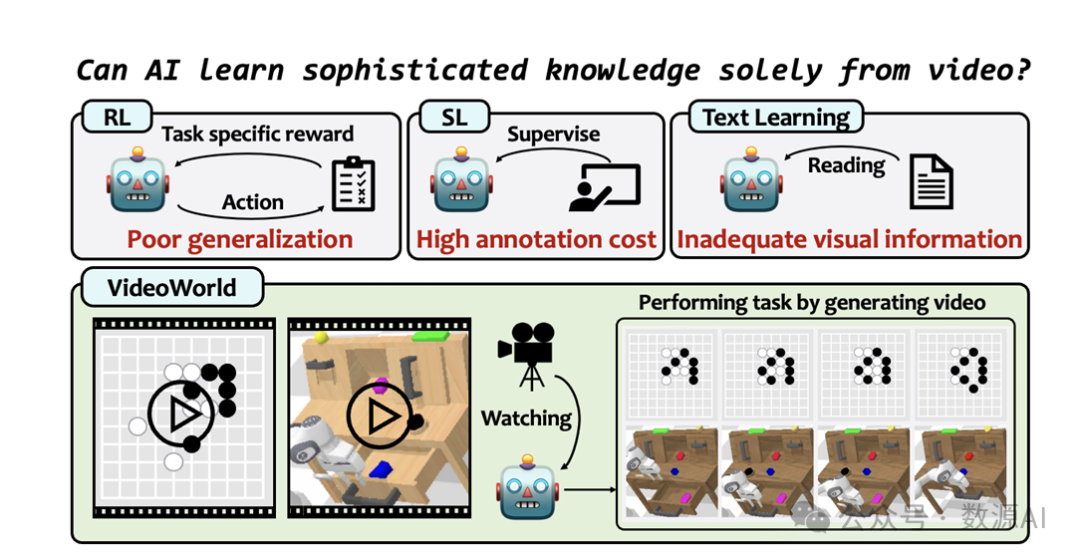
下一个标记预测训练范式赋予了大型语言模型(LLMs)显著的世界知识和智能,使它们能够帮助解决需要推理、提前规划和决策的复杂任务。然而,仅靠语言无法完全捕捉所有形式的知识或涵盖现实世界中的大量信息。在自然界中,生物体主要通过视觉信息获取知识,而不是仅仅依赖语言。例如,大猩猩和其他灵长类动物主要通过视觉观察学习觅食和社交互动等重要技能,模仿成年行为而不依赖语言。
简介
本研究探讨了深度生成模型是否能够仅从视觉输入中学习复杂知识,与当前主要关注基于文本的模型(如大型语言模型)形成对比。我们开发了VideoWorld,一个基于未标注视频数据训练的自回归视频生成模型,并在基于视频的围棋和机器人控制任务中测试其知识获取能力。我们的实验揭示了两个关键发现:(1) 仅通过视频训练提供了足够的信息来学习知识,包括规则、推理和规划能力;(2) 视觉变化的表示对于知识获取至关重要。为了提高这一过程的效率和效果,我们引入了潜在动态模型(LDM)作为VideoWorld的关键组件。值得注意的是,VideoWorld在Video-GoBench中达到了5段专业水平,仅使用了一个3亿参数的模型,而没有依赖强化学习中典型的搜索算法或奖励机制。在机器人任务中,VideoWorld有效地学习了多样化的控制操作,并在不同环境中进行了泛化,接近了CALVIN和RLBench中oracle模型的性能。这项研究为从视觉数据中获取知识开辟了新的途径,所有代码、数据和模型均已开源以供进一步研究。
3. 方法
3.1. 基本视频生成框架

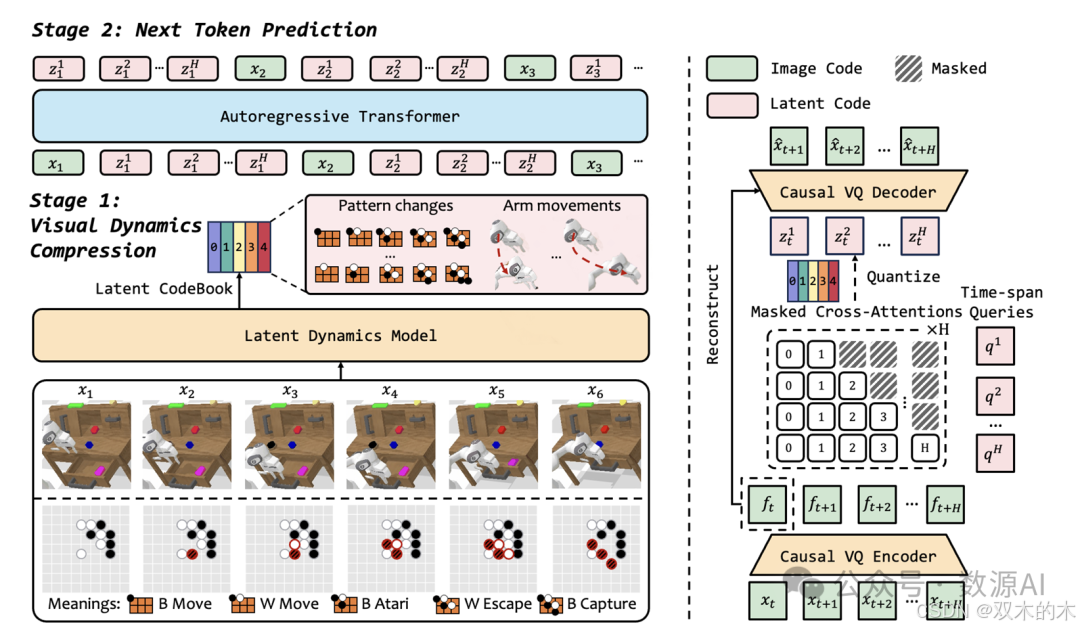
图 3. 提出的 VideoWorld 模型架构概述。(左)整体架构。(右)提出的潜在动态模型(LDM)。首先,LDM 将每一帧到其后续 H 帧的视觉变化压缩为一组潜在代码。然后,自回归 transformer 将 LDM 的输出与下一个 token 预测范式无缝集成。
在我们的实现中,VQ-VAE 使用定制的 MAGVIT-v2 [73] 实例化,配备了 FSQ 量化器 [41],而 transformer 则使用 Llama 架构 [56] 实现。这种设置使我们能够生成高质量的帧,从而为各种知识学习任务有效地建模视觉序列。
3.2. 使用潜在动态模型学习
与状态序列(例如围棋中的移动位置)相比,视频为理解任务提供了必要的视觉信息——例如,围棋中棋子之间的局部模式或机器人环境。在初步实验中,我们发现基本框架已经能够仅从视频中学习基础知识(见第 5.3 节)。然而,如图 2 所示,其学习效率仍然落后于在状态上训练的模型。我们将此归因于与关键决策和行动相关的视觉变化表示效率低下。例如,虽然围棋中的移动可以通过状态序列中的几个位置 token 编码,但原始视频在通过视觉编码器后需要更多的 token。这种差异对学习效率和性能都有不利影响。因此,我们开发了 VideoWorld,它将丰富的视觉信息与视觉变化的紧凑表示相结合,以实现更有效的视频学习。
潜在动态模型。视频编码通常需要数百或数千个 VQ token 来捕捉完整的视觉信息,导致知识在这些 token 中的稀疏嵌入。为了提高效率,我们引入了一个潜在动态模型,该模型使用查询嵌入来表示跨多个帧的视觉变化。例如,围棋中的多步棋盘变化或机器人中的连续动作表现出强的时间相关性。通过将这些多步变化压缩为紧凑的嵌入,我们不仅增加了策略信息的紧凑性,还编码了前向规划的指导。

图4. 在Go(左)和CALVIN(右)训练集上学习到的潜在代码的UMAP投影[34]。每个点代表由LDM生成的连续(预量化)潜在代码。在Go示例中,奇数步代表白方的移动,偶数步代表黑方的移动。我们可视化了步骤2/4/6中黑方移动的潜在代码。图例显示了为新黑方移动学习的常见模式示例。为了清晰起见,这些移动在棋盘上用添加的颜色和线条突出显示,以指示新模式。在右侧,我们可视化了机器人手臂沿X/Y/Z轴在1、5和10帧间隔内的移动的潜在代码。点按位移范围进行颜色编码,紫色和红色表示沿每个轴相反方向的最大位移。

实验与结果
1. 实现细节
我们的自回归 transformer 是随机初始化的,其编码器最初在目标数据集上进行重建训练,然后冻结。可训练参数包括 transformer 层、投影层和输出层。LDM 和 transformer 编码器的默认词汇量为 64,000,对应于 FSQ 级别 [8,8,8,5,5,5] 。对于围棋和 CALVIN 环境,我们增加了每个编码器中的下采样层数,将每帧压缩到 4x4 。我们使用 6 帧长度用于围棋,10 帧用于 CALVIN。我们在 CALVIN ABCD --> D 分割中进行训练和测试。RLBench 与 CALVIN 共享相同的训练设置,使用自定义脚本生成的 20k 轨迹数据。训练使用 AdamW [37] 优化器,学习率为 0.0003,无权重衰减。围棋的批量大小设置为 256,CALVIN 为 32,分别在 8 个 A100 GPU 上需要大约 4 天和 2 天的训练时间。
2. 基准测试
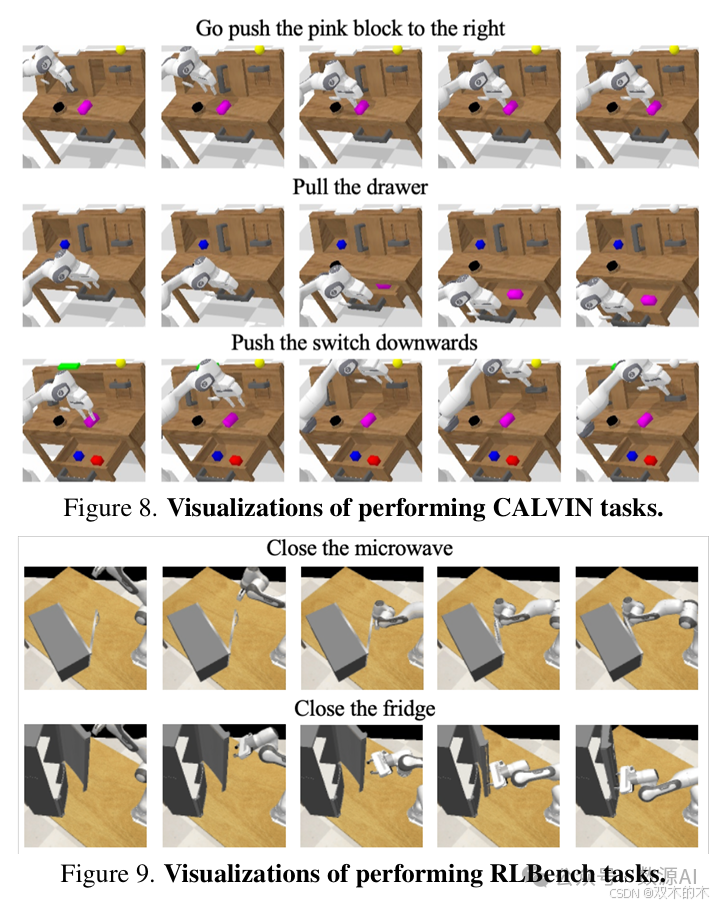
我们在三个基准测试上评估了 VideoWorld:Video-GoBench、CALVIN 和 RLBench。Go 测试了长期推理和复杂的前向规划,而后两者涉及更复杂的视觉信息。对于 Go,我们使用第4.2节中详述的评估指标。在 CALVIN 基准测试中,我们的模型控制一个带有平行夹爪的 Franka Emika Panda 机器人,在一个有桌子、可打开的抽屉、彩色积木以及 LED 和灯泡的环境中。我们评估了三个任务:推积木、打开/关闭抽屉和打开/关闭灯。每个任务都由一个指令标签指定,例如“去把红色积木向右推”,该标签作为视频生成的条件提供给 transformer。在 RLBench 基准测试中,模型控制相同的机械臂,但环境和摄像头视角与 CALVIN 不同。我们评估了两个任务:关闭微波炉和关闭冰箱。两个环境中的物体位置在每次执行时都是随机生成的。我们随机抽取了500个任务并记录了成功率。
3. 基本框架的关键发现
模型可以从原始视频中学习基本知识。如表1(索引5)和表2(第二行)所示,使用基本框架在 Go 视频和机器人视频上进行训练,使模型能够掌握 Go 的规则,并学习基本的机器人操作技能。在 Go 测试集上,模型展示了几乎100%的合法性,表明它已经掌握了包括禁止重复移动、自杀移动以及更高级的规则如劫争等规则。此外,它在预测最佳移动时达到了接近 50% 的准确率,显示出对 Go 策略的中等理解。在机器人场景中,模型也展示了一定的完成任务能力。与 Go 相比,处理更复杂的外观而不依赖预训练对模型的生成质量提出了更高的要求。
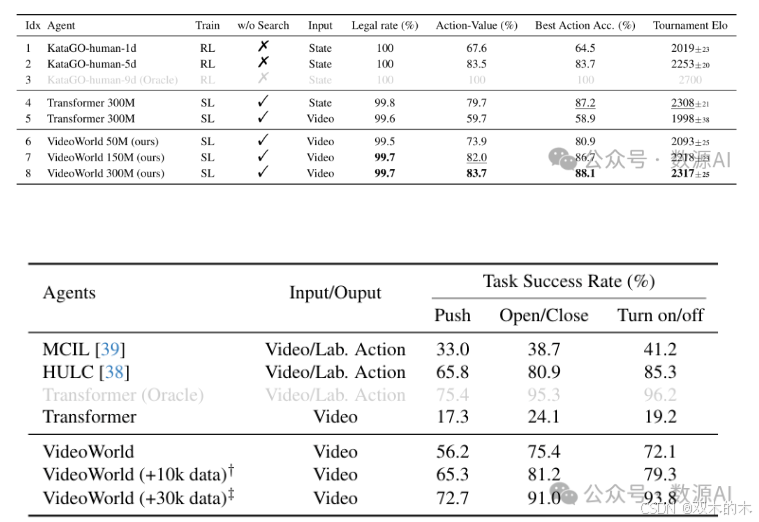
视觉变化的表示至关重要。虽然基本框架可以从视频中学习,但我们发现使用更紧凑的视觉变化表示可以显著提高性能和效率。在 Go 中,状态序列编码每一步移动及其对应的位置标记来表示棋盘上的变化;相比之下,原始视频捕捉了这些关键动作之外的额外视觉细节,因此需要更多的标记。尽管基于状态的方法在表示棋子之间的局部模式和形状(Go 中的一个重要属性)方面存在不足,但其紧凑性带来了更高的学习效率和更好的结果。如表1所示,在相同的数据预算下,使用这些状态序列进行训练显著提高了所有指标的性能(索引4 vs. 5)。图2进一步展示了状态表示收敛得更快。在机器人场景中,尽管完全用状态序列表示环境可能不可行,但为每一帧添加动作标签仍然显著提高了任务完成率。这些发现强调了紧凑的视觉变化表示对于有效视频学习的重要性。
4. LDM 结果
基于上述观察,我们引入了潜在动态模型(LDM)以提高效率和效果
围棋结果。在表1中,我们将VideoWorld与三个官方KataGo模型进行了比较,这些模型根据人类技能水平进行了校准:1段、5段和9段。1段模型代表对围棋有基础理解的玩家,而5段和9段水平则代表逐渐提高的技能,9段作为最高人类水平的Oracle。值得注意的是,所有这些模型都是基于强化学习的,使用了搜索和奖励机制。
我们在三个参数规模上评估了VideoWorld:50M、 150M和 300M。所有模型在新棋盘上都表现出强大的泛化能力。即使是规模最小的模型VideoWorld-50M也超过了KataGo-1d(Elo 2093 vs. 2019),而VideoWorld-300M则超过了人类水平的KataGo-5d(Elo 2317 vs. 2253),展示了VideoWorld在掌握复杂任务方面的强大能力。与没有LDM的对应模型相比,VideoWorld显示出显著的改进(Elo 2317 vs. 1998),强调了使用潜在表示学习的好处。
此外,我们观察到所有指标的性能随着模型规模的增加而持续提高,这表明VideoWorld的知识学习能力继续有效扩展,随着模型规模的增加,还有进一步改进的潜力。
CALVIN结果。表2展示了模型在CALVIN基准测试中的结果。VideoWorld仅依赖于观察到的视频,不使用动作标签,其性能接近使用真实动作标签监督的模型。这表明我们提出的LDM有效地支持了基于视频的知识学习,即使在视觉上更复杂的场景中也是如此。此外,我们使用监督学习代理[66]在CALVIN环境中生成了额外30k的轨迹数据,并将其纳入VideoWorld的训练中。如表2所示,VideoWorld展示了数据扩展能力,随着数据量的增加,进一步接近Oracle性能。这表明我们的方法在大规模训练中应用的潜力。
跨多个环境的泛化。为了进一步验证VideoWorld在不同环境中的泛化能力,我们引入了来自RL-Bench的两个额外任务,这些任务在视觉上与CALVIN不同:关闭微波炉和关闭冰箱。对于每个任务,我们生成了10k轨迹,并在这些数据与CALVIN结合的情况下训练VideoWorld。然后我们评估了两种环境中的任务成功率。如表3所示,VideoWorld在两种设置中表现出良好的泛化能力,同时掌握了两种环境中的技能,并接近Oracle性能。强化学习方法通常难以在不同环境中泛化,因为它们严重依赖于特定任务的状态/动作/奖励等。这也展示了我们的方法作为通用知识学习者的潜力。更多细节请参见附录A。

总结
在这项工作中,我们迈出了探索使用下一个标记预测范式从原始视频数据中学习知识的第一步。我们在定制的Video Go和机器人模拟环境中进行了系统实验。我们提出了两个关键发现:i)模型可以掌握围棋规则并学习基本的机器人操作,以及ii)视觉变化的表示对知识学习至关重要。基于这些发现,我们提出了一个潜在动态模型(LDM)以提高知识获取的效率和效果。尽管将这种方法应用于现实世界场景仍面临高质量视频生成和泛化等挑战,但我们相信视频生成模型有潜力作为通用知识学习者,并最终成为能够在现实世界中思考和行动的人工大脑。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









