






本文来源公众号“Coggle数据科学”,仅用于学术分享,侵权删,干货满满。
尽管大模型在微调后表现出色,但它们需要足够的数据来进行下游任务。数据增强(DA)是解决这一问题的替代方案之一。
数据增强方法主要分为两类:文本生成和文本修改。文本生成方法通过深度学习模型生成句子,如回译法,但计算成本高且生成句子的多样性有限。相比之下,文本修改方法通过简单的修改操作生成多样化的句子,成本较低。
COLING 2024 https://aclanthology.org/2024.lrec-main.1325.pdf
为了解决上述挑战,文章提出了STAGE(Simple Text Data Augmentation by Graph Exploration)方法。 STAGE利用简单的修改操作(如插入、删除、替换和交换),但其独特之处在于通过一个称为共现图(co-graph)的词关系图来选择最佳的操作数。
什么是文本增强?
文本修改方法
文本修改方法通过对文本进行简单的修改操作(如删除、插入、替换等)来生成新的句子。
基于词级别的修改
对单个词(token)进行修改,通常随机选择词并应用简单的操作。这些方法简单有效,但由于操作数的选择是随机的,性能提升有限。
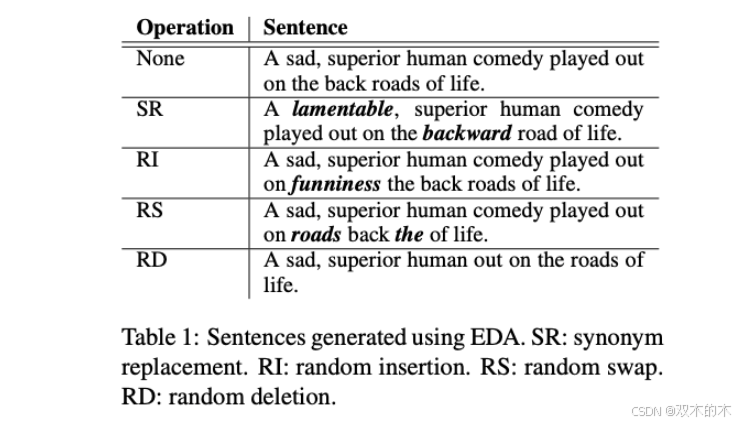
典型的方法包括EDA(Easy Data Augmentation),它通过随机选择词并进行插入、删除、替换等操作来生成新句子。
基于句子片段的修改
不是修改单个词,而是修改句子中的一个片段。它们通常利用额外的信息(如显著性)来选择重要的片段进行修改。然而,片段修改可能会导致句子被过度修改,从而降低性能。
基于图的文本修改方法
利用图结构来进行文本修改,生成的样本质量优于EDA,但过程复杂且计算成本高。
文本生成方法
与文本修改不同,文本生成方法旨在生成自然语言句子。
回译(Back-Translation)
通过将句子翻译成另一种语言,然后再翻译回原语言来生成新句子。虽然回译可以生成语义相似的句子,但需要经过两次推理过程,计算成本较高。
生成句子表示的方法
通过生成新的句子表示来进行数据增强,例如Text Smoothing。这些方法生成的是句子的表示(如向量),而不是实际的句子,因此不够透明,难以应用于预训练语言模型的微调。
基于GPT-3的生成方法
最近的研究利用GPT-3等大型语言模型来生成句子。这些方法虽然强大,但依赖于大型语言模型,计算成本较高。
现有方法的局限性
大多数方法随机选择操作数,导致性能提升有限。片段修改方法可能会过度修改句子,导致性能下降。
此外回译方法计算成本高,通过大模型生成句子表示的方法不够透明,难以应用于微调。
STAGE方法
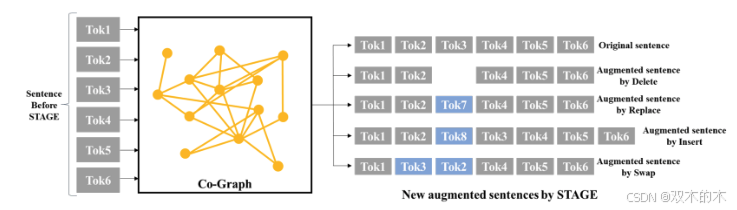
STAGE方法的核心在于利用共现图(co-graph)来选择文本修改操作的操作数。共现图从文本数据中构建,能够建模词与词之间的关系,从而为操作数的选择提供重要信息。
与现有方法依赖随机选择不同,STAGE利用共现图中的词频、共现关系、语义和重要性等信息来优化操作数的选择。
共现图的生成
-
分词:将训练数据集中的所有句子进行分词,得到唯一的词(token)作为图的节点。
-
共现统计:统计两个词在句子中的共现次数。如果两个词在窗口大小 ww 内共现次数超过阈值 ττ,则在图中连接这两个节点。
-
孤立节点:有些节点可能没有连接任何边,称为孤立节点。与之相对,连接了边的节点称为边节点(edge-nodes)。
-
句子图(sen-graph):为单个句子构建句子图,它是共现图的子图。句子图的节点是句子中的词,如果两个词在共现图中相连,则在句子图中也连接它们。
共现图的理解
语义和语法关联:
-
如果两个词在图中相连,说明它们在语义和语法上高度相关。
-
例如,在电影评论数据集中,词“movie”可能与“star”、“horror”、“making”等词相连,这些词在语义和语法上具有强关联性。
-
这种关联性对于生成流畅和地道的语言非常重要。
词的重要性:
-
通过节点的边数可以判断词的重要性。
-
孤立节点:边数很少的词(如孤立词)可能不重要,因为它们与其他词的关联性很弱。
-
高频边节点:边数很多的词(如停用词)也可能不重要,因为它们与许多词共现,缺乏特异性。
-
中等边数的节点:边数适中的词通常更重要,因为它们与特定词有强关联性。
基于共现图的操作
STAGE方法使用四种简单的文本修改操作:删除(Delete)、替换(Replace)、插入(Insert)和交换(Swap)。
删除操作(Delete)
删除操作的目标是通过删除句子中的某些词来生成新句子。STAGE提出了四种删除方法:
-
D-RE:随机删除一个边节点(edge-word)。
-
D-RI:随机删除一个孤立节点(isolated word)。
-
D-ME:删除句子中边数最多的词。这些词通常是停用词或与许多词共现的词。
-
D-LE:删除句子中边数最少的词。这些词可能是某些特定模式(如习语)中的关键词。
替换操作(Replace)
替换操作的目标是通过替换句子中的某些词来生成新句子。STAGE提出了六种替换方法:
-
R-RC:随机选择一个边节点,并用其共现图中的随机邻居节点替换。
-
R-RS:随机选择一个边节点,并用其共现图中最相似的邻居节点替换。
-
R-RDS:随机选择一个边节点,并用其共现图中最不相似的邻居节点替换。
-
R-MC:选择句子中边数最多的词(重要词),并用其共现图中的随机邻居节点替换。
-
R-MS:选择句子中边数最多的词,并用其共现图中最相似的邻居节点替换。
-
R-MDS:选择句子中边数最多的词,并用其共现图中最不相似的邻居节点替换。
插入操作(Insert)
插入操作的目标是通过在句子中插入新词来生成新句子。STAGE提出了四种插入方法:
-
I-EE:随机选择一个边节点,并在其旁边插入其共现图中的随机邻居节点。
-
I-REN:从共现图中随机选择一个与句子中边节点相连的词,并插入到句子的随机位置。
-
I-MEN:选择与句子中边节点相连且边数最多的词,并插入到句子的随机位置。
-
I-LEN:选择与句子中边节点相连且边数最少的词,并插入到句子的随机位置。
交换操作(Swap)
交换操作的目标是通过交换句子中的两个词来生成新句子。STAGE提出了三种交换方法:
-
S-RP:随机选择一对在句子图中相连的词进行交换。
-
S-SP:选择一对在句子图中相连且语义最相似的词进行交换。
-
S-DSP:选择一对在句子图中相连且语义最不相似的词进行交换。
实验与对比
实验设置
在多种环境下评估了STAGE方法的性能,使用了六个文本分类数据集(SST-2、CR、SUBJ、TREC、PC、IMDB),涵盖了不同规模和领域。
实验还使用了三种预训练模型(BERT、DistilBERT、RoBERTa)来验证STAGE在不同模型上的有效性。
为了模拟数据稀缺的情况,实验使用了训练数据集的1%、2%、5%、10%、30%、50%、70%和100%子集进行微调,每个实验运行五次并取平均值。
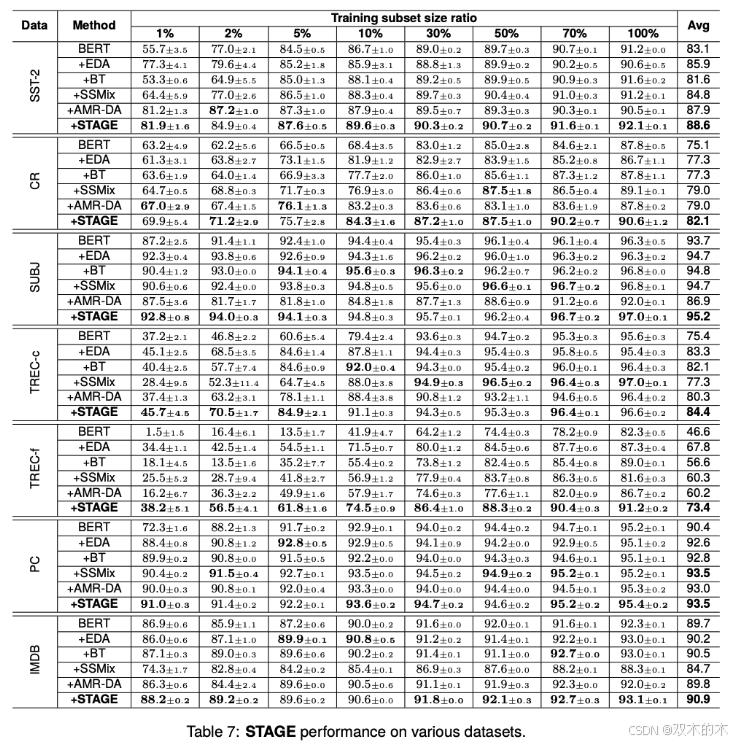
表7展示了STAGE与其他数据增强方法的性能对比。对比方法包括:
-
EDA:使用简单操作并随机选择操作数。
-
BT(回译):基于文本生成的经典方法。
-
SSMix:在数据增强时考虑词的重要性。
-
AMR-DA:通过AMR图进行数据增强。
实验结果
STAGE在多分类任务(如TREC-c和TREC-f)中的性能提升尤为显著,相比二分类任务(如SST-2、CR、SUBJ、PC、IMDB),STAGE在多分类任务中的性能提升幅度更大(11.9%到35.0%)。这表明STAGE在处理复杂分类任务时具有显著优势。
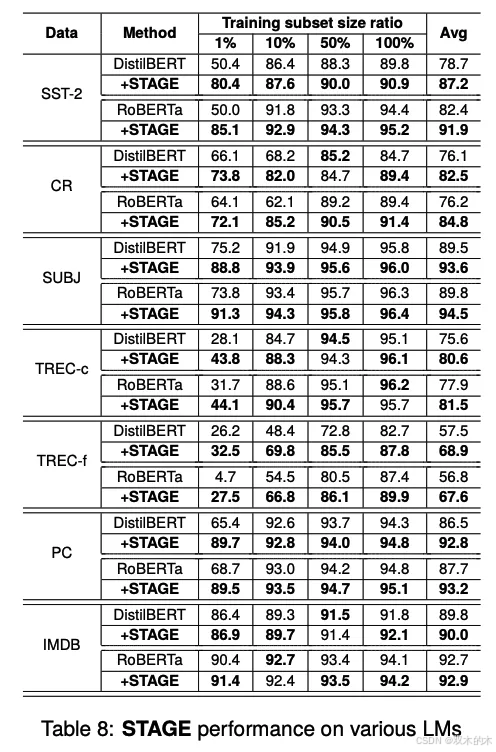
STAGE的计算成本较低,与基于深度学习的方法(如回译和SSMix)相比,STAGE的计算成本更低,适合低资源环境。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









