






本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:一文带你读懂YOLOv1~YOLOv11
可以和之前的文章江大白 | 目标检测YOLOv1-YOLO11,算法进化全记录(建议收藏!)_yolov5 江大白-优快云博客结合来看。
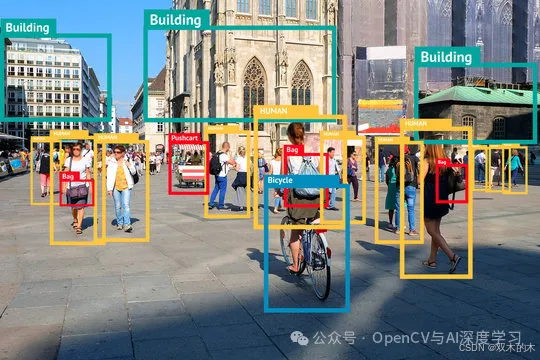
YOLO (You Only Look Once) 是一系列实时对象检测机器学习算法。对象检测是一项计算机视觉任务,它使用神经网络对图像中的对象进行定位和分类。这项任务的应用范围很广,从医学成像到自动驾驶汽车。多种机器学习算法用于对象检测,其中一种是卷积神经网络 (CNN)。
CNN 是任何 YOLO 模型的基础,研究人员和工程师使用这些模型执行对象检测和分割等任务。YOLO 模型是开源的,它们在该领域得到了广泛的应用。这些模型从一个版本到另一个版本都在改进,从而提高了准确性、性能和附加功能。本文将探讨整个 YOLO 家族,我们将从原始到最新开始,探索它们的架构、用例和演示。
YOLOv1
在引入 YOLO 对象检测之前,研究人员使用了基于卷积神经网络 (CNN) 的方法,如 R-CNN 和 Fast R-CNN。这些方法使用两步过程来预测边界框,然后使用回归对这些框中的对象进行分类。这种方法速度缓慢且占用大量资源,但 YOLO 模型彻底改变了对象检测。当 Joseph Redmon 和 Ali Farhadi 于 2016 年开发第一个 YOLO 时,它通过新的增强架构克服了传统对象检测算法的大部分问题。
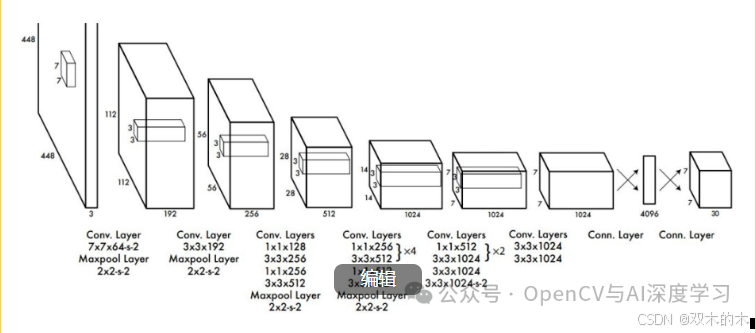
最初的 YOLO 架构由 24 个卷积层和 2 个完全连接的层组成,其灵感来自用于图像分类的 GoogLeNet 模型。YOLOv1 方法在当时是第一个。
网络的初始卷积层从图像中提取特征,而全连接层预测输出概率和坐标。这意味着边界框和分类都在一个步骤中进行。这个一步式流程简化了操作并实现了实时效率。此外,YOLO 体系结构还使用了以下优化技术。
-
-
Leaky ReLU 激活:Leaky ReLU 有助于防止“垂死的 ReLU”问题,即神经元在训练过程中可能会卡在不活跃的状态。
-
Dropout 正则化:YOLOv1 在第一个全连接层之后应用 dropout 正则化,以防止过拟合。
-
数据增强
-
如何工作的?
YOLO 模型的本质是将对象检测视为回归问题。YOLO 方法是将单个卷积神经网络 (CNN) 应用于完整图像。此网络将图像划分为多个区域,并预测每个区域的边界框和概率。
这些边界框由预测概率加权。然后,可以对这些权重进行阈值处理,以仅显示高分检测。
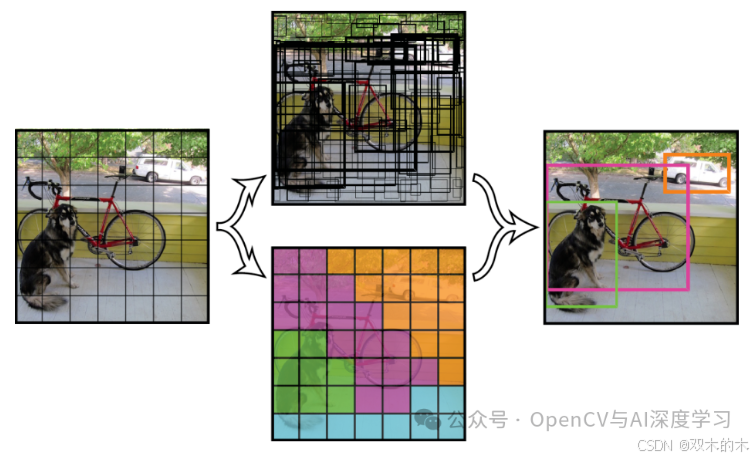
YOLOv1 将输入图像划分为一个网格 (SxS),每个网格单元负责预测其内部对象的边界框和类概率。每个边界框预测都包含一个置信度分数,指示框中存在对象的可能性。研究人员使用交并比 (IOU) 等技术计算置信度分数,该技术可用于筛选预测。尽管 YOLO 方法新颖且速度很快,但它面临一些限制,如下所示。
-
-
泛化:YOLOv1 难以检测在训练中无法准确看到的新对象。
-
空间约束:在 YOLOv1 中,每个网格单元格只能预测两个框,并且只能有一个类,这使得它难以处理成群出现的小对象,例如鸟群。
-
损失函数限制:YOLOv1 损失函数在小边界框和大边界框中处理错误的方式相同。大框中的小错误通常是可以的,但小错误对 IOU 的影响要大得多。
-
定位错误:YOLOv1 的一个主要问题是准确性,它经常错误地定位对象在图像中的位置。
-
现在我们已经介绍了 YOLO 的基本机制,让我们看看研究人员如何在下一个版本中升级此模型的功能。
YOLOv2
YOLO9000在 YOLOv1 发布一年后推出,以解决当时对象检测数据集的局限性。YOLO9000之所以这样命名,是因为它可以检测 9000 多个不同的对象类别。这在准确性和泛化性方面具有变革性。
YOLO9000 背后的研究人员提出了一种独特的联合训练算法,该算法可以根据检测和分类数据训练对象检测器。这种方法利用标记的检测图像来学习精确定位对象,并使用分类图像来增加其词汇量和鲁棒性。
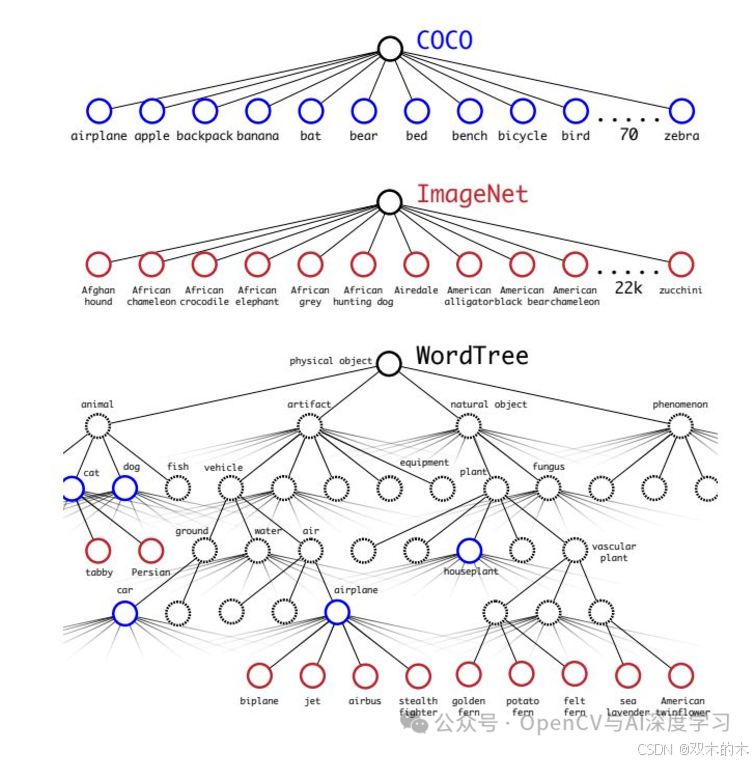
通过组合来自不同数据集的特征进行分类和检测,YOLO9000 显示出比其前身 YOLOv1 有很大的改进。YOLO9000 被宣布为更好、更强、更快。
-
-
分层分类:YOLO9000 中使用的一种基于 WordTree 结构的方法,允许增加对看不见对象的泛化,并增加对象的词汇量或范围。
-
架构变化:YOLO9000引入了一些变化,例如使用批量规范化来加快训练和稳定性、使用锚框或滑动窗口方法,并使用 Darknet-19 作为主干。Darknet-19 是一个具有 19 层的 CNN,旨在准确和快速。
-
联合训练:一种算法,允许模型利用分层分类框架并从分类和检测数据集(如 COCO 和 ImageNet)中学习。
-
不过,YOLO 系列继续改进,接下来我们来看看 YOLOv3。
YOLOv3
几年后,YOLO 背后的研究人员提出了下一个版本 YOLOv3。虽然 YOLO9000 是一种最先进的模型,但对象检测通常有其局限性。提高准确性和速度始终是对象检测模型的目标之一,这也是 YOLOv3 的目标,在这里和那里进行少量调整,我们就会得到性能更好的模型。
改进从边界框开始,虽然它仍然使用滑动窗口方法,但 YOLOv3 有一些增强。YOLOv3 引入了多尺度预测,它可以在三种不同尺度上预测边界框。这意味着可以更有效地检测不同大小的物体。除其他改进外,这让 YOLO 重新回到了最先进模型的地图上,并在速度和准确性之间进行了权衡。
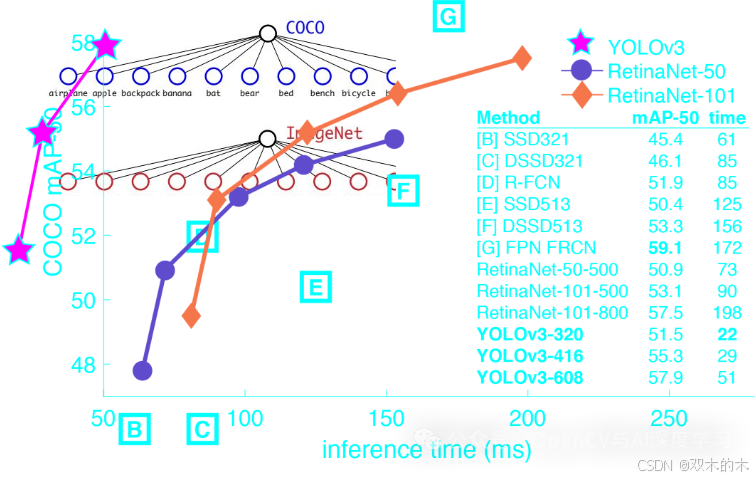
如图所示,YOLOv3 使用平均精度均值 (mAP-50) 指标提供了最佳的速度和准确性之一。此外,YOLOv3 还引入了其他改进,如下所示。
-
-
骨干网:YOLOv3 使用更好、更大的 CNN 骨干网,即 Darknet-53,它由 53 层组成,是 Darknet-19 和深度学习残差网络 (Resnets) 之间的混合方法,但比 ResNet-101 或 ResNet-152 更高效。
-
跨尺度预测:YOLOv3 预测三种不同尺度的边界框,类似于特征金字塔网络。这使模型能够更有效地检测各种大小的对象。
-
分类器:使用独立的 Logistic 分类器代替 softmax 函数,允许每个盒子有多个标签。
-
数据集:研究人员仅在 COCO 数据集上训练 YOLOv3。
-
此外,虽然不太重要,但 YOLOv3 修复了 YOLOv2 中的一个小数据加载错误,这帮助了大约 2 mAP 点。接下来,让我们看看 YOLO 模型是如何演变成 YOLOv4 的。
YOLOv4
延续 YOLO 系列的传统,YOLOv4 引入了多项改进和优化。让我们更深入地了解 YOLOv4 机制。
结构
最显着的变化是 3 部分架构,虽然 YOLOv4 仍然是一个单阶段的目标检测网络,但架构涉及 3 个主要组件,即 backbone、head 和 neck。这种架构拆分是 YOLO 发展过程中非常重要的一步。在 YOLO 中,backbone、head 和 neck 都有自己的功能。
主干是特征提取部分,通常是跨层学习特征的 CNN。然后,neck 对从 backbone 的不同级别提取的特征进行细化和组合,从而创建丰富且信息丰富的特征表示。最后,head 执行实际预测,并输出边界框、类概率和对象性分数。
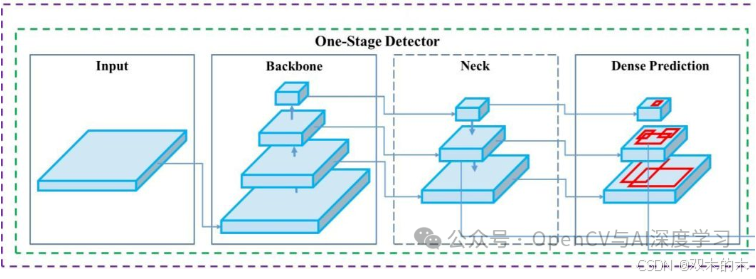
对于 YOLOv4,研究人员将以下组件用于 backbone、neck 和 head。
-
-
主干网:CSPDarknet53 是一个卷积神经网络和对象检测主干网,它使用使用跨阶段部分网络 (CSPNet) 策略的 DarkNet-53。
-
Neck:修改后的空间金字塔池化 (SPP) 和路径聚合网络 (PAN) 用于 YOLOv4,从而产生更精细的特征提取、更好的训练和更好的性能。
-
头部:YOLOv4 采用 YOLOv3 的(基于锚点的)架构作为 YOLOv4 的头部。
-
这并不是 YOLOv4 引入的全部,在优化和选择正确的方法和技术方面还有很多工作,让我们接下来探索这些。
优化
正如研究人员在论文中介绍的那样,YOLOv4 模型带有两袋方法:免费赠品袋 (BoF) 和特价袋 (BoS)。这些方法对 YOLOv4 的性能很有帮助,在本节中,我们将探讨研究人员使用的重要方法。
-
-
马赛克数据增强:这种数据增强方法将 4 张训练图像合二为一,使模型能够学习在更广泛的上下文中检测对象,并减少对大小批量的需求。研究人员将其用作骨干训练的 BoF 的一部分。
-
自我对抗训练 (SAT):一种两阶段数据增强技术,其中网络欺骗自己并修改输入图像以认为没有对象。然后,它在这个修改后的图像上进行训练,以提高稳健性和泛化性。研究人员将其用作检测器或网络头的 BoF 的一部分。
-
跨小批量归一化 (CmBN):交叉迭代批量归一化 (CBN) 的修改版,使训练更适合单个 GPU。研究人员用作探测器 BoF 的一部分。
-
改进的空间注意力模块 (SAM):研究人员将原始 SAM 从空间注意力修改为点注意力,增强了模型在不增加计算成本的情况下专注于重要特征的能力。用作 BoS 的一部分,作为网络检测器的附加块。
-
然而,这还不是全部,YOLOv4 在 BoS 和 BoF 中使用了许多其他技术,例如作为 BoS 一部分的骨干网的 Mish 激活和跨级部分连接 (CSP)。所有这些优化修改为 YOLOv4 带来了最先进的性能,尤其是在速度和准确性方面。
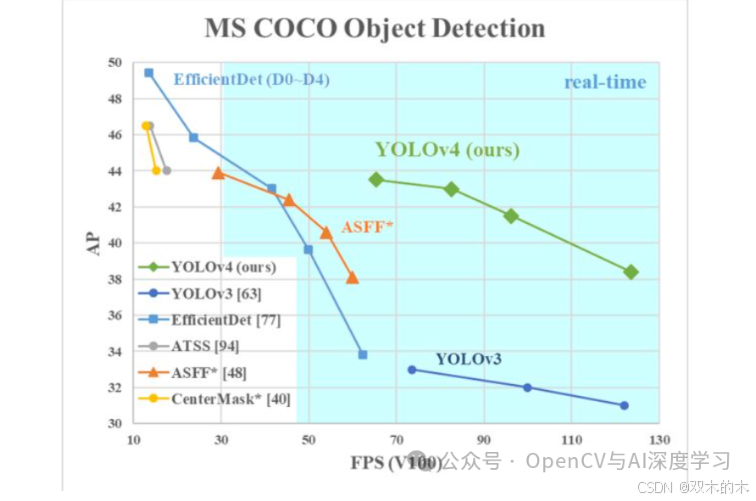
YOLOv5
虽然 YOLOv5 没有附带专门的研究论文,但该模型给所有开发人员、工程师和研究人员留下了深刻的印象。YOLOv5 在 YOLOv4 之后几个月推出,没有太大的改进,但速度略快。Ultralytics 设计的 YOLOv5 更易于实现,并且具有多种语言支持的更详细的文档,最值得注意的是 YOLOv5 基于 Pytorch 构建,使其易于开发人员使用。
与此同时,它的前辈稍微难以实现。Ultralytics 宣布 YOLOv5 为世界上最受欢迎的视觉 AI,此外,YOLOv5 还具有一些很棒的功能,例如用于模型导出的不同格式、用于使用您自己的数据进行训练的训练脚本,以及多种训练技巧,如测试时增强 (TTA) 和模型集成。
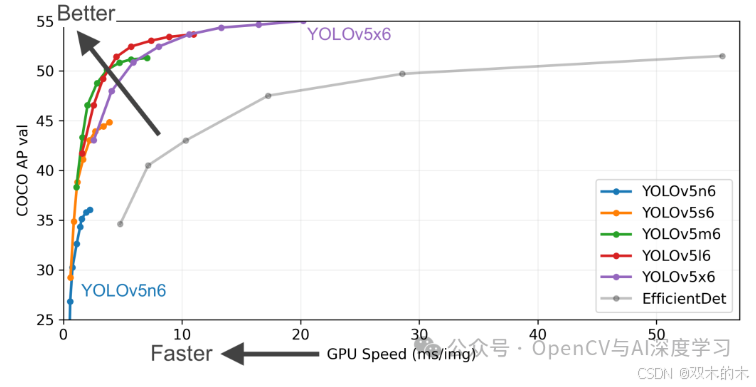

易用性、持续更新、庞大的社区和良好的文档使 YOLOv5 成为完美的紧凑型模型,它可以在轻量级硬件上运行,并且几乎实时地提供不错的准确性。YOLO 模型在 YOLOv5 到 YOLOv6 之后继续发展,让我们在下一节中探讨一下。
YOLOv6
YOLOv6 是 YOLO 系列中的一次重大演变,它引入了一些关键的架构和训练变化,以实现速度和准确性之间的更好平衡。值得注意的是,YOLOv6 以专注于工业应用而著称。这种工业重点提供了部署就绪型网络,并更好地考虑了实际环境的约束。
在速度和准确性之间取得平衡,它可以在常用硬件上运行,例如 Tesla T4 GPU,这使得在工业环境中部署对象检测比以往任何时候都更容易。YOLOv6 并不是当时唯一可用的模型,还有 YOLOv5、YOLOX 和 YOLOv7 都是高效探测器部署的竞争候选者。现在,让我们讨论一下 YOLOv6 引入的变化。
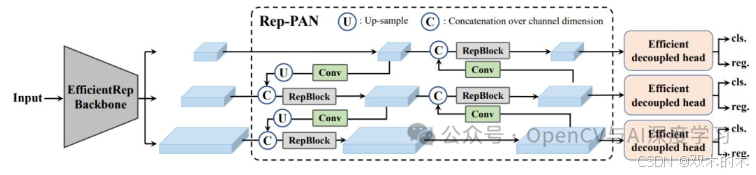
-
-
Backbone:研究人员使用 EfficientRep 构建主干,EfficientRep 是一种硬件感知型 CNN,具有用于小型模型(N 和 S)的 RepBlock,以及用于大型模型(M 和 L)的 CSPStackRep Block。
-
Neck:使用 Rep-PAN 拓扑,使用 RepBlock 或 CSPStackRep 块增强 YOLOv4 和 YOLOv5 中修改后的 PAN 拓扑。这提供了来自主干网不同级别的更高效的特征聚合。
-
Head:YOLOv6 引入了 Efficient Decoupled Head,简化了设计以提高效率。它采用混合通道策略,减少了中间 3×3 卷积层的数量,并与 backbone 和 neck 一起缩放宽度。
-
YOLOv6 还整合了其他几种技术来提高性能。
-
-
标签分配:利用任务对齐学习 (TAL) 来解决分类和框回归任务之间的错位。
-
Self-Distillation:它将 Self-Distillation 应用于分类和回归任务,进一步提高了准确性。
-
损失函数:它使用 VariFocal Loss 进行分类,并结合使用 SIoU 和 GIoU Loss 进行回归。
-
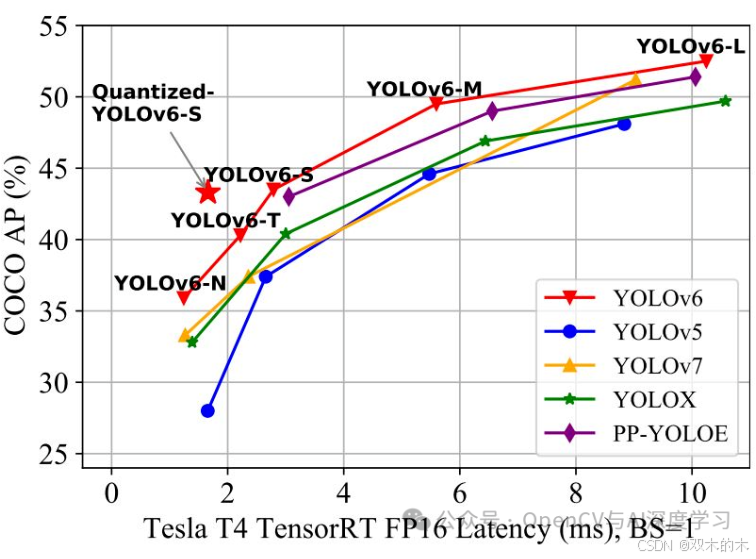
YOLOv6 代表了一种经过改进和增强的对象检测方法,它建立在其前辈的优势之上,同时引入了创新的解决方案来应对实际部署的挑战。它专注于效率、准确性和工业适用性,使其成为工业应用的宝贵工具。
YOLOv7
虽然从技术上讲,YOLOv6 是在 YOLOv7 之前引入的,但 YOLOv6 的生产版本是在 YOLOv7 之后推出的,并在性能上超越了它。然而,YOLOv7 引入了一个新颖的概念,称其为可训练的免费赠品袋 (BoF)。这包括一系列细粒度的改进,而不是彻底的改革。
这些改进主要集中在优化训练过程和增强模型学习有效表示的能力,而不会显著增加计算成本。以下是 YOLOv7 引入的一些主要功能。
-
-
模型重新参数化:YOLOv7 提出了一个有计划的重新参数化模型,这是一种适用于不同网络中的层的策略,具有梯度传播路径的概念。
-
动态标签分配:使用多个输出层训练模型会带来一个新问题:“如何为不同分支的输出分配动态目标?为了解决这个问题,YOLOv7 引入了一种新的标签分配方法,称为粗到细铅引导标签分配。
-
扩展和复合缩放:YOLOv7 为对象检测器提出了“扩展”和“复合缩放”方法,可以有效地利用参数和计算。
-
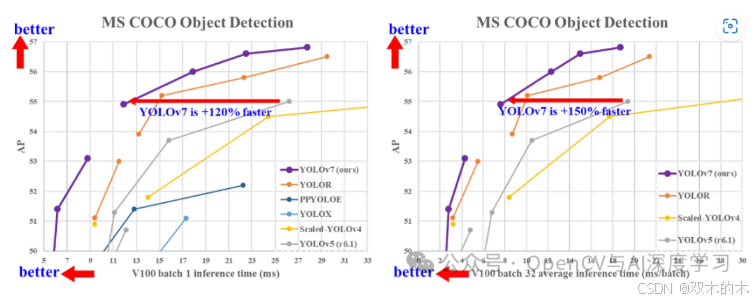
YOLOv7 专注于精细的细化和优化策略,以增强实时对象检测器的性能。它强调可训练的免费赠品袋、深度监督和架构改进,从而在不牺牲速度的情况下显着提高准确性,使其成为 YOLO 系列中的宝贵进步。然而,进化继续产生 YOLOv8,这是我们接下来的主题。
YOLOv8
YOLOv8 是 YOLO 系列实时对象检测器的迭代版本,在准确性和速度方面提供尖端性能。但是,YOLOv8 没有官方论文,但与 YOLOv5 类似,这是一个用户友好的增强型 YOLO 对象检测模型。YOLOv8 由 Ultralytics 开发,引入了新功能和优化,使其成为各种应用中各种对象检测任务的理想选择。以下是其功能的快速概述。
-
-
高级 Backbone 和 Neck 架构
-
无锚分体式 Ultralytics 头:YOLOv8 采用无锚分体式 Ultralytics 头,与基于锚的方法相比,这有助于提高准确性和更高效的检测过程。
-
优化的准确性-速度权衡
-
除此之外,YOLOv8 还是 Ultralytics 维护良好的模型,提供了多种模型,每个模型都专门用于计算机视觉中的特定任务,如检测、分割、分类和姿势检测。由于 YOLOv8 通过 Ultralytics 库易于使用,让我们在演示中尝试一下。

YOLOv8 模型在各种基准测试数据集中实现了 SOTA 性能。例如, YOLOv8n 模型在 COCO 数据集上实现了 37.3 的 mAP (平均精度均值),在 A100 TensorRT 上实现了 0.99 毫秒的速度。接下来,让我们看看 YOLO 家族是如何通过 YOLOv9 进一步演变的。
YOLOv9
与其前辈相比,YOLOv9 采用了不同的方法,直接解决了深度神经网络中的信息丢失问题。它引入了可编程梯度信息 (PGI) 的概念和一种称为广义高效层聚合网络 (GELAN) 的新架构,以应对信息瓶颈并确保训练期间可靠的梯度流。
研究人员之所以引入 YOLOv9,是因为现有的方法忽略了这样一个事实,即当输入数据进行逐层特征提取和空间变换时,会丢失大量信息。这种信息丢失会导致梯度不可靠,并阻碍模型学习准确表示的能力。
YOLOv9 引入了 PGI,这是一种通过使用辅助可逆分支生成可靠梯度的新方法。此辅助分支为计算目标函数提供了完整的输入信息,从而确保用于更新网络权重的梯度信息量更大。辅助分支的可逆性质确保在前馈过程中不会丢失任何信息。
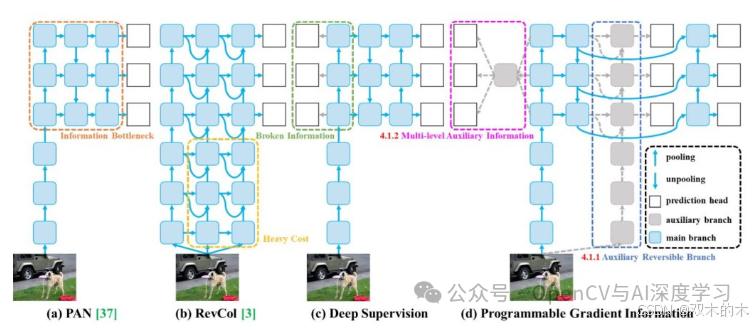
YOLOv9 还提出了 GELAN 作为一种新的轻量级架构,旨在最大化信息流并促进获取相关信息以进行预测。GELAN 是 ELAN 架构的通用版本,利用任何计算块,同时保持效率和性能。研究人员基于梯度路径规划设计了它,确保了通过网络的高效信息流。

YOLOv9 通过关注信息流和梯度质量,为对象检测提供了全新的视角。PGI 和 GELAN 的推出使 YOLOv9 有别于其前身。这种对深度神经网络中信息处理基础知识的关注可以提高性能,并更好地解释对象检测中学习过程。
YOLOv10
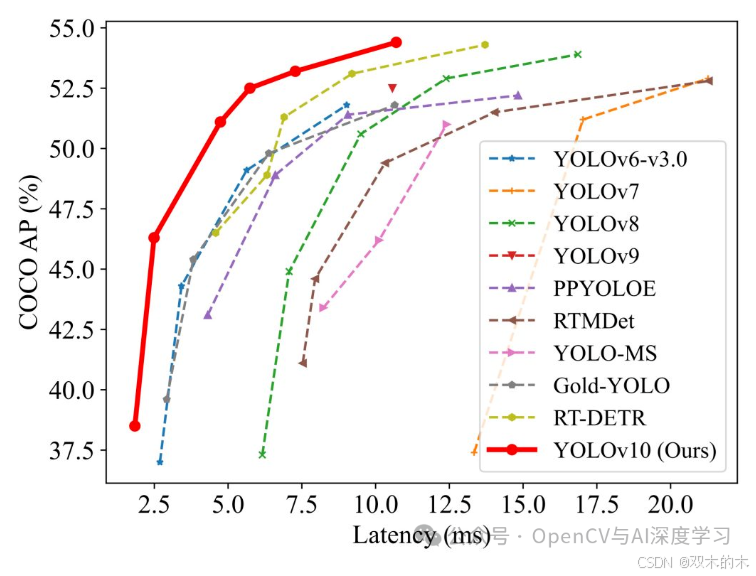
YOLOv10 的推出对于实时端到端对象检测具有革命性意义。YOLOv10 超越了之前的所有速度和精度基准,实现了真正的实时对象检测。YOLOv10 无需使用 NMS 检测进行非极大值抑制 (NMS) 后处理。
这不仅提高了推理速度,还简化了部署过程。YOLOv10 引入了一些关键功能,例如无 NMS 培训和整体设计方法,使其在所有指标上都表现出色。
-
-
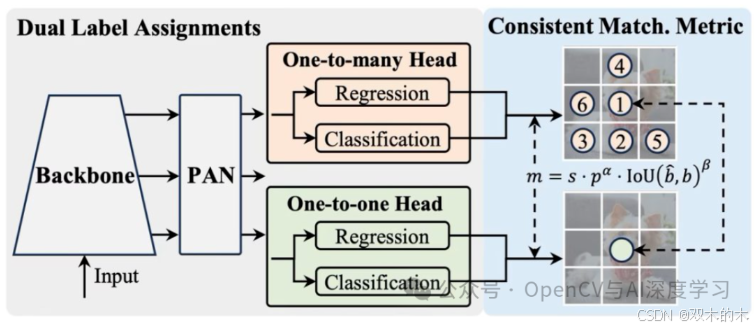
无 NMS 检测:YOLOv10 提供了一种基于一致双重分配的新颖无 NMS 训练策略。它采用双标签分配(一对多和一对一)和一致的匹配指标,在训练期间提供丰富的监督,同时在推理过程中消除 NMS。在推理过程中,仅使用 1 对 1 头,从而实现无 NMS 检测。
-
整体效率-精度驱动设计:YOLOv10 采用整体方法进行模型设计,优化各种组件以提高效率和准确性。它引入了轻量级分类头、空间通道解耦下采样和秩导向块设计,以降低计算成本。
-
YOLO11:体系结构增强功能
YOLO11 于 2024 年 9 月发布。它经历了一系列架构改进,并专注于在不牺牲准确性的情况下提高计算效率。
它引入了 C3k2 块和 C2PSA 块等新型组件,有助于改进特征提取和处理。这会导致性能略好,但模型的参数要少得多。以下是 YOLO11 的主要功能。
-
-
C3k2 模块:YOLO11 引入了 C3k2 模块,这是一种跨阶段部分 (CSP) 瓶颈的计算高效实现。它取代了 backbone 和 neck 中的 C2f 块,并采用两个较小的卷积而不是一个大型卷积,从而减少了处理时间。
-
C2PSA 模块:在 Spatial Pyramid Pooling – Fast (SPPF) 模块之后引入跨阶段部分空间注意力 (C2PSA) 模块,以增强空间注意力。这种注意力机制使模型能够更有效地关注图像中的重要区域,从而有可能提高检测准确性。
-
有了这个,我们讨论了整个 YOLO 系列的对象检测模型。但有一件事告诉我,进化不会就此止步,创新将继续,我们将在未来看到更好的表现。
YOLO 模型的未来
YOLO 系列一直在突破计算机视觉的界限。它已经从一个简单的架构演变成一个复杂的系统。每个版本都引入了新的功能并扩展了支持的任务范围。
展望未来,提高准确性、速度和多任务能力的趋势可能会继续下去。潜在的发展领域包括以下内容。
-
-
改进的可解释性:使模型的决策过程更加透明。
-
增强的稳健性:使模型对具有挑战性的条件更具弹性。
-
高效部署:针对各种硬件平台优化模型。
-
YOLO 模型的进步对各个行业都有重大影响。YOLO 执行实时对象检测的能力有可能改变我们与视觉世界的交互方式。但是,解决道德考虑和潜在偏见很重要。确保公平、问责和透明对于负责任的创新至关重要。
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









