







本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:基于YOLO11的车体部件检测与分割
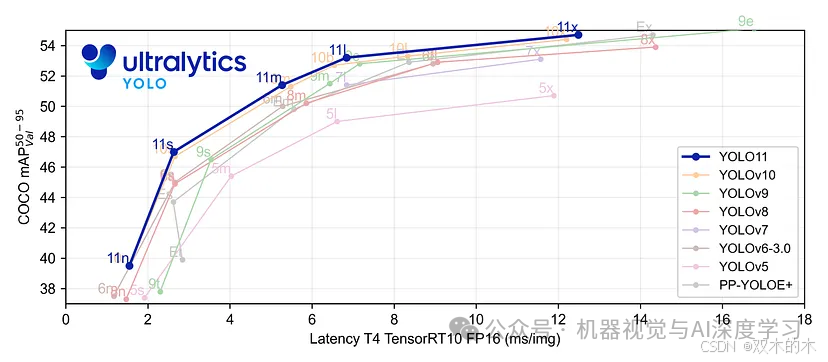
YOLOv11 有哪些新功能?
YOLOv11 在 YOLOv10 的基础上进行了重大升级,在性能和适应性方面有了显著的提高。主要增强功能包括:
1. 改进的模型架构:YOLOv11 引入了更高效的模型架构,旨在优化图像处理和预测准确性。
2. GPU 优化:利用现代机器学习的进步,YOLOv11 针对 GPU 训练进行了高度优化,可提供更快的模型训练和更高的准确性。
3. 速度提升:YOLOv11 模型的延迟降低了 25%,比之前的版本快得多。速度提升增强了实时性能。
4. 更少的参数,相同的精度:简化的架构可减少参数,从而无需牺牲模型的精度即可实现更快的处理速度。
5. 增强适应性和任务支持:YOLOv11 支持更广泛的任务、对象类型和图像格式,扩展了其多功能性并使其适用于更加多样化的应用。
通过这些增强功能,YOLOv11 为物体检测设立了新的标准,在不牺牲准确性的情况下提供更快、更高效的模型。
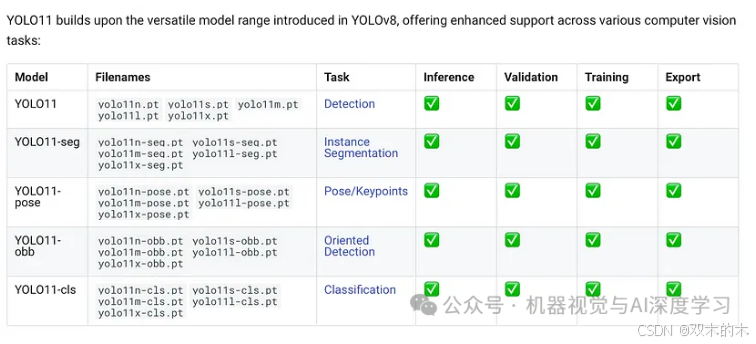
YOLOv11 包含哪些模型?
YOLOv11 提供了多种针对各种任务而设计的模型。这些包括:
1. 边界框模型:用于检测图像中对象的标准 YOLOv11 模型,没有任何后缀。2
2. 实例分割(-seg):不仅可以检测对象,还可以在图像中区分和分割对象的模型。
3. 姿势估计(-pose):非常适合根据关键点识别和估计人体或物体的姿势。
4. 方向边界框(-obb):这些模型检测并绘制旋转的边界框,对于有角度的物体特别有用。
5.分类(-cls):旨在将对象分类到预定义类别中的模型。
此外,这些模型有不同的尺寸以满足不同的性能需求:
-Nano (n):超轻且快速。
-Small (s):针对速度和中等精度进行了优化。
-Medium (m):在速度和精度之间取得平衡。
-Large (l):增强精度,适用于复杂任务。
-Extra-Large (x):最高精度,专为资源密集型任务而设计。
这些选项使 YOLOv11 高度灵活,可满足各种用例和资源需求。
如何使用模型?
您可以参考https://docs.ultralytics.com/models/yolo11/#usage-examples上的文档来了解如何使用该模型。
YOLOv11 图像分割演示
1. 安装依赖项
!pip install ultralyticsfrom IPython import displaydisplay.clear_output()import ultralyticsultralytics.checks()from ultralytics import YOLOfrom IPython.display import display, Image
之后,我们需要将模型下载到我们的环境中。请从Ultralytics页面选择并下载所需的模型。
! wget https://github.com/ultralytics/assets/releases/download/v 8.3.0 / yolo11x-seg.pt2. 准备自定义数据集
我将使用来自 Roboflow 的数据集(对于其他任务,请参阅文档以获取有关准备数据集的具体说明)。现在,让我们从 Roboflow 下载正确的格式。
import roboflowroboflow.login()rf = roboflow.Roboflow()project = rf.workspace("model-examples").project("car-parts-instance-segmentation")dataset = project.version(1).download("yolov11")
创建一个data.yaml文件,为模型提供有关数据集的信息。
import yamlwith open(f"{dataset.location}/data.yaml", 'r') as f:dataset_yaml = yaml.safe_load(f)dataset_yaml["train"] = "../train/images"dataset_yaml["val"] = "../valid/images"dataset_yaml["test"] = "../test/images"with open(f"{dataset.location}/data.yaml", 'w') as f:yaml.dump(dataset_yaml, f)
3. 训练模型
训练模型的步骤因任务而异。请确保选择正确的任务并相应地正确配置路径和模型设置。
%cd {HOME}!yolo task=segment mode=train model="/content/yolo11x-seg.pt" data="/content/car-parts-instance-segmentation-1/data.yaml" epochs=10 imgsz=640
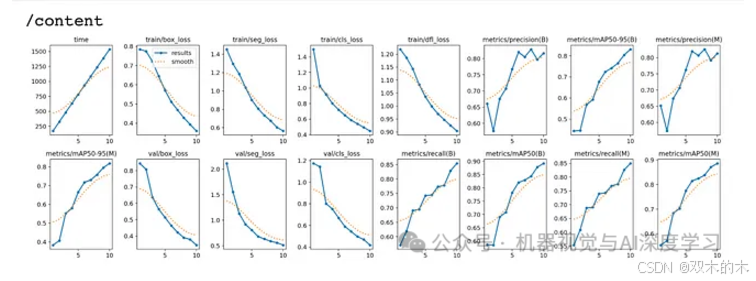
4. 检查矩阵和结果
!ls {HOME}/runs/segment/train/
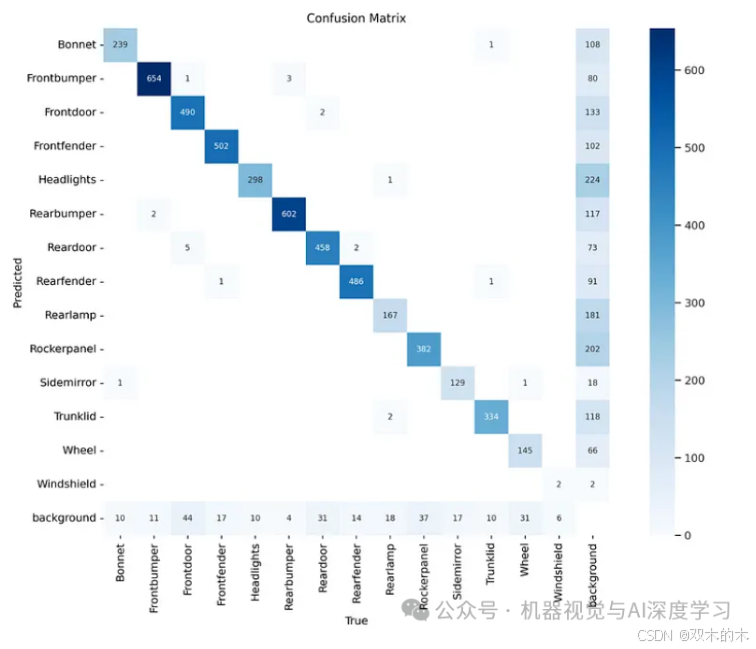
%cd {HOME}Image(filename=f'{HOME}/runs/segment/train/confusion_matrix.png', width=600)
%cd {HOME}Image(filename=f'{HOME}/runs/segment/train/results.png', width=600)
%cd {HOME}Image(filename=f'{HOME}/runs/segment/train/val_batch0_pred.jpg', width=600)

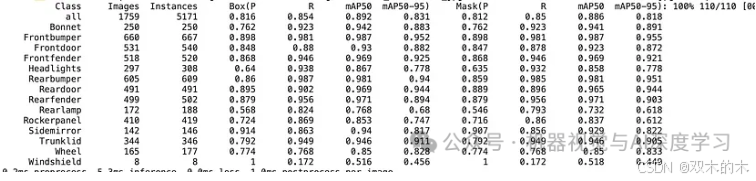
5. 验证自定义模型
训练模型后,验证其性能以确保其符合您的期望非常重要。验证过程涉及使用一组之前从未见过的数据测试模型,以评估其准确率、精确率、召回率和其他指标。
%cd {HOME}!yolo task=segment mode=val model={HOME}/runs/segment/train/weights/best.pt data={dataset.location}/data.yaml
6. 使用自定义模型进行推理
%cd {HOME}!yolo task=segment mode=predict model={HOME}/runs/segment/train/weights/best.pt conf=0.25 source={dataset.location}/test/images save=true
import globfrom IPython.display import Image, displayfor image_path in glob.glob(f'{HOME}/runs/segment/predict2/*.jpg')[:3]:display(Image(filename=image_path, height=600))print("\n")

源码下载:
https://github.com/tententgc/notebook-colab/blob/main/yolo11x_segmentation.ipynb https://github.com/tententgc/notebook-colab/blob/main/train_yolo11_object_detection_on_custom_dataset.ipynbTHE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









