




本文来源公众号“戎易大数据”,仅用于学术分享,侵权删,干货满满。
原文链接:数据分析实操篇:关于【B站】iPhone 16 Pro国行评测视频评论数据的分析
数据整理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import jieba
from wordcloud import WordCloud
from textblob import TextBlob
from PIL import Imagedf1 = pd.read_excel('/home/mw/input/iPhone9412/B站视频-影视飓风_241020_1729431473.xlsx')
df2 = pd.read_excel('/home/mw/input/iPhone9412/B站视频-何同学_241020_1729431535.xlsx')
print(df1.head())
print(df2.head())输出如下:
oid rpid rrpid 评论层级 用户昵称 \0 113158849174933 244965773840 NaN 一级评论 看了这样1 113158849174933 244683461313 NaN 一级评论 焖鸡米饭2 113158849174933 244683367713 NaN 一级评论 尸兄弟姐妹3 113158849174933 244858677040 NaN 一级评论 如约而至就好4 113158849174933 244841753904 NaN 一级评论 土豆Boy评论内容 评论时间 \0 牛逼 2024-10-19 15:54:471 慕名而来 2024-10-18 20:41:132 你们对AI的理解就只是用他来识别动物?2024-10-18 20:38:523 16用贴膜嘛[思考] 2024-10-18 10:28:434 AI擦除特别香。\nAI擦除这东西,真的会上瘾,就会觉得很好玩,也有用。\n我手机mate60。2024-10-18 00:53:19被回复用户 性别 用户当前等级 点赞数 回复数 视频标题 \0 NaN 保密 6 0 0 没有AI,它有什么?iPhone 16 Pro国行评测!1 NaN 男 2 0 0 没有AI,它有什么?iPhone 17 Pro国行评测!2 NaN 保密 6 1 0 没有AI,它有什么?iPhone 18 Pro国行评测!3 NaN 男 5 0 0 没有AI,它有什么?iPhone 19 Pro国行评测!4 NaN 保密 6 0 0 没有AI,它有什么?iPhone 20 Pro国行评测!视频链接0 https://www.bilibili.com/video/BV1yXtjeSEDZ/?s...1 https://www.bilibili.com/video/BV1yXtjeSEDZ/?s...2 https://www.bilibili.com/video/BV1yXtjeSEDZ/?s...3 https://www.bilibili.com/video/BV1yXtjeSEDZ/?s...4 https://www.bilibili.com/video/BV1yXtjeSEDZ/?s...oid rpid rrpid 评论层级 用户昵称 \0 113159167876462 244806579057 NaN 一级评论 萌死了的兔兔1 113159167876462 245025718800 NaN 一级评论 呆呆有昵称2 113159167876462 245019525696 NaN 一级评论 是伟豪呀3 113159167876462 245012350944 NaN 一级评论 DFK-L24 113159167876462 244774978417 NaN 一级评论 叶辞的甜梨涡评论内容 评论时间 被回复用户 性别 \0 抽我 2024-10-20 10:52:07 NaN 女1 我三星的S23U,就可以侧键双击启动相机,虽然可能技术不是很超前,但是的确很实用。2024-10-20 09:21:05 NaN 保密2 我真的好想换手机啊啊啊啊啊啊!11用到现在了 2024-10-20 06:02:50 NaN 男3 [doge_金箍] 2024-10-20 01:19:26 NaN 保密4 女朋友吗[以闪亮之名_星星眼] 2024-10-19 22:32:51 NaN 保密用户当前等级 点赞数 回复数 视频标题 \0 5 0 0 【何同学】这个按钮不重要。iPhone 16 Pro深度体验1 4 0 0 【何同学】这个按钮不重要。iPhone 17 Pro深度体验2 5 0 0 【何同学】这个按钮不重要。iPhone 18 Pro深度体验3 2 0 0 【何同学】这个按钮不重要。iPhone 19 Pro深度体验4 3 0 0 【何同学】这个按钮不重要。iPhone 20 Pro深度体验视频链接0 https://www.bilibili.com/video/BV1zWtjezEAL/?1 https://www.bilibili.com/video/BV2zWtjezEAL/?2 https://www.bilibili.com/video/BV3zWtjezEAL/?3 https://www.bilibili.com/video/BV4zWtjezEAL/?4 https://www.bilibili.com/video/BV5zWtjezEAL/?
导入数据
df1.info()输出如下:
<class 'pandas.core.frame.DataFrame'>RangeIndex: 9128 entries, 0 to 9127Data columns (total 14 columns):oid 9128 non-null int64rpid 9128 non-null int64rrpid 4321 non-null float64评论层级 9128 non-null object用户昵称 9128 non-null object评论内容 9128 non-null object评论时间 9128 non-null object被回复用户 4321 non-null object性别 9128 non-null object用户当前等级 9128 non-null int64点赞数 9128 non-null int64回复数 9128 non-null int64视频标题 9128 non-null object视频链接 9128 non-null objectdtypes: float64(1), int64(5), object(8)memory usage: 998.5+ KB
影视飓风:
1、一共9128条评论数据
2、rrpid和被回复用户存在缺失值
df2.info()输出如下:
<class 'pandas.core.frame.DataFrame'>RangeIndex: 6310 entries, 0 to 6309Data columns (total 14 columns):oid 6310 non-null int64rpid 6310 non-null int64rrpid 1290 non-null float64评论层级 6310 non-null object用户昵称 6310 non-null object评论内容 6310 non-null object评论时间 6310 non-null object被回复用户 1290 non-null object性别 6310 non-null object用户当前等级 6310 non-null int64点赞数 6310 non-null int64回复数 6310 non-null int64视频标题 6310 non-null object视频链接 6310 non-null objectdtypes: float64(1), int64(5), object(8)memory usage: 690.2+ KB
何同学:
1、一共6310条评论数据
2、rrpid和被回复用户存在缺失值
#检查重复值print(df1.duplicated().sum())print(df2.duplicated().sum())
输出:
00
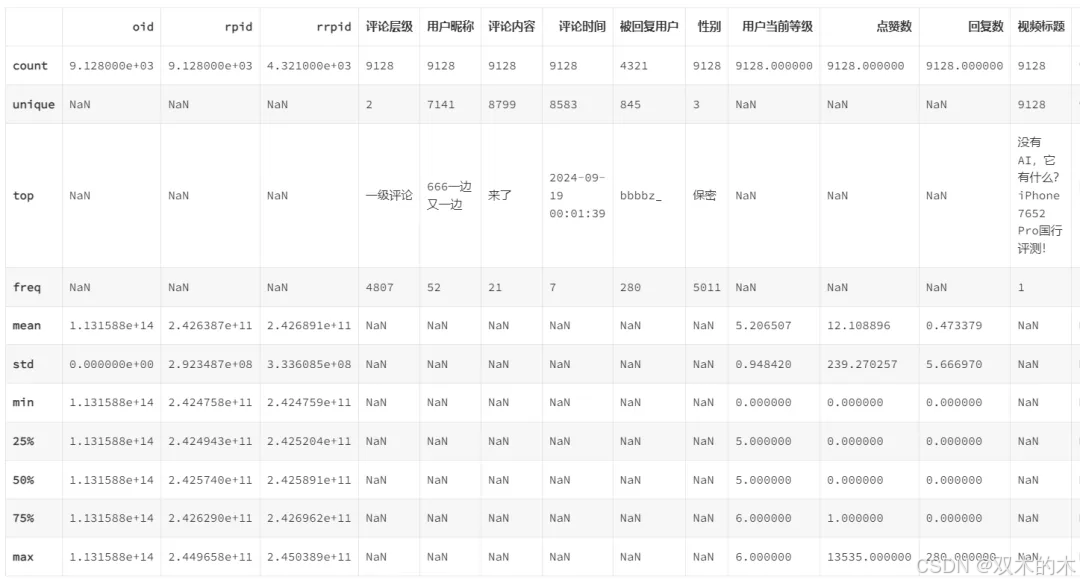
影视飓风:
1、用户昵称中出现频次最高的是:666一边又一边,一共52次
2、评论内容中出现频次最高的是:来了,一共21次
3、评论时间中最早的是:2024-09-19 00:01:39
df2.describe(include='all')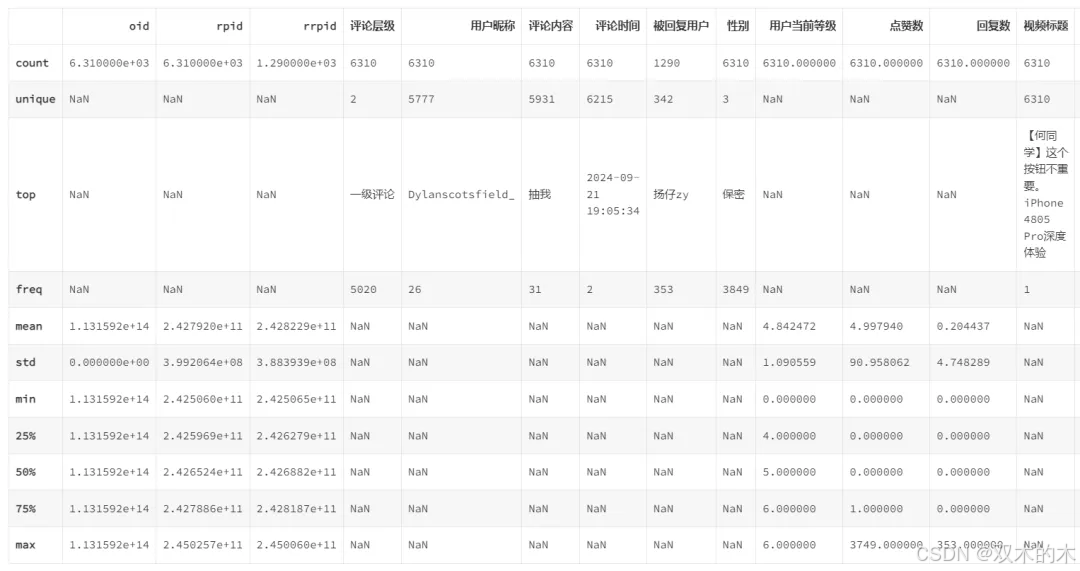
何同学:
1、用户昵称中出现频次最高的是:Dylanscotsfield_,一共26次
2、评论内容中出现频次最高的是:抽我,一共31次
3、评论时间中最早的是:2024-09-21 19:05:34
#定义情感分析函数
def analyze_sentiment(text):
analysis = TextBlob(text)
if analysis.sentiment.polarity > 0:
return "Positive"
elif analysis.sentiment.polarity == 0 :
return "Neutral"
else:
return "Negative"
df1['sentiment'] = df1['评论内容'].apply(analyze_sentiment)
df2['sentiment'] = df2['评论内容'].apply(analyze_sentiment)
#计算情感分布情况
sentiment_distribution1 = df1['sentiment'].value_counts().reindex(['Positive','Neutral','Negative'],fill_value = 0)
sentiment_distribution2 = df2['sentiment'].value_counts().reindex(['Positive','Neutral','Negative'],fill_value = 0)
# print(sentiment_distribution1)
# print(sentiment_distribution2)输出如下:
Positive 15Neutral 9066Negative 47Name: sentiment, dtype: int64Positive 13Neutral 6286Negative 11Name: sentiment, dtype: int64
可视化-双柱状图
#双柱状图函数
def plot_double_bar(ax,data,labels,title,xlabel,ylabel,color1,color2):
widths = 0.35
x = range(len(labels))
x1 = [i-widths/2 for i in x]
x2 = [i+widths/2 for i in x]
ax.bar(x1,data['影视飓风'],width=widths,color=color1,edgecolor='black',label='影视飓风')
ax.bar(x2,data['何同学'],width=widths,color=color2,edgecolor='black',label='何同学')
for i in range(len(x1)):
ax.text(x1[i], data['影视飓风'][i], f'{data["影视飓风"][i]:.0f}', ha='center', va='bottom')
ax.text(x2[i], data['何同学'][i], f'{data["何同学"][i]:.0f}', ha='center', va='bottom')
ax.set_title(title)
ax.set_xticks(x)
ax.set_xticklabels(labels)
ax.set_xlabel(xlabel)
ax.set_ylabel(ylabel)
ax.legend(title="UP主")
plt.figure(figsize=(16,6))
plt.subplot(1,3,1)
plt.bar(sentiment_distribution1.index,sentiment_distribution1.values,color='green',edgecolor='black')
plt.title(''评论内容情感分布(影视飓风)'')
plt.xlabel('情感')
plt.ylabel('数量')
for p in plt.gca().patches:
plt.annotate(str(p.get_height()),(p.get_x()+p.get_width()/2.,p.get_height()),ha='center',va='bottom',fontsize=9,color='black')
plt.subplot(1,3,2)
plt.bar(sentiment_distribution2.index,sentiment_distribution2.values,color='orange',edgecolor='black')
plt.title('评论内容情感分布(何同学)')
plt.xlabel('情感')
plt.ylabel('数量')
for p in plt.gca().patches:
plt.annotate(str(p.get_height()),(p.get_x()+p.get_width()/2.,p.get_height()),ha='center',va='bottom',fontsize=9,color='black')
ax3 = plt.subplot(1,3,3)
data = pd.DataFrame({'影视飓风':sentiment_distribution1,'何同学':sentiment_distribution2})
plot_double_bar(ax3,data,['Positive','Neutral','Negative'],'评论内容情感分析比对','情感','数量','green','orange')
plt.tight_layout()
plt.show()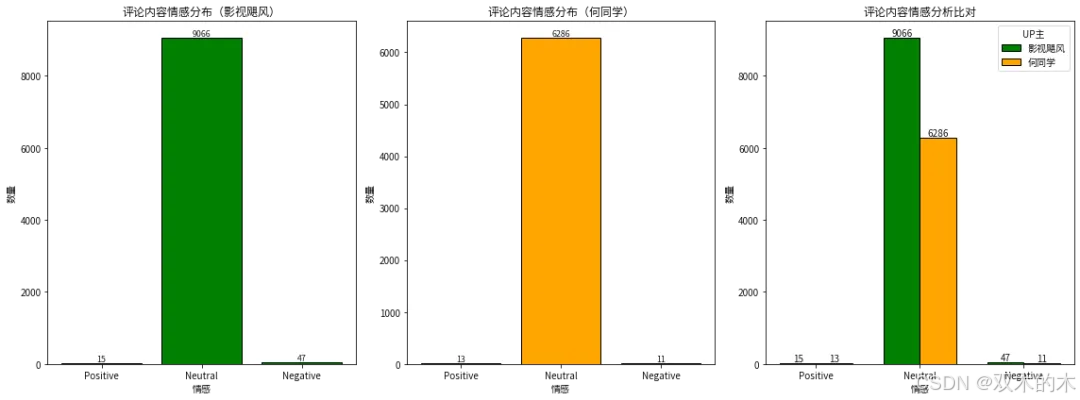
结论:
1、影视飓风评论内容的情感分布:积极15,中立9066,消极47
2、何同学评论内容的情感分布:积极13,中立6286,消极11
3、从数值上看,影视飓风评论内容的各项情感均大于何同学的
4、总体上,绝大多数评论内容均处于中立
sentiment_percent1 = sentiment_distribution1.values/sum(sentiment_distribution1.values)
sentiment_percent2 = sentiment_distribution2.values/sum(sentiment_distribution2.values)
print(sentiment_percent1)
print(sentiment_percent2)[0.0016433 0.99320771 0.00514899][0.00206022 0.99619651 0.00174326]
plt.figure(figsize=(16,6))
def autopct_format(values):
def my_format(pct):
total = sum(values)
val = int(round(pct*total/100.0))
label = "{:.1f}%\n({:d})".format(pct, val)
return label
return my_format
plt.subplot(1,2,1)
plt.pie(sentiment_percent1,labels=sentiment_distribution1.index,autopct=autopct_format(sentiment_percent1),startangle=90)
plt.title('评论内容情感分布(影视飓风)')
plt.subplot(1,2,2)
plt.pie(sentiment_percent2,labels=sentiment_distribution2.index,autopct=autopct_format(sentiment_percent2),startangle=90)
plt.title('评论内容情感分布(何同学)')
plt.tight_layout()
plt.show<function matplotlib.pyplot.show(*args, **kw)>
结论:从占比来看,影视飓风评论内容中的积极情感低于何同学的,消极情感高于何同学的。
comment_count1 = df1['评论内容'].count()comment_count2 = df2['评论内容'].count()like_count1 = df1['点赞数'].sum()like_count2 = df2['点赞数'].sum()rcount1 = df1['回复数'].sum()rcount2 = df2['回复数'].sum()# 将字典转换为 DataFramedata1 = pd.DataFrame({'影视飓风': [comment_count1, like_count1, rcount1]}, index=['评论数量', '点赞数量', '回复数量'])data2 = pd.DataFrame({'何同学': [comment_count2, like_count2, rcount2]}, index=['评论数量', '点赞数量', '回复数量'])# 合并两个 DataFrames_d = pd.concat([data1, data2], axis=1)s_d.columns = ['影视飓风', '何同学']
plt.figure(figsize=(18, 6))# 绘制影视飓风的条形图plt.subplot(1, 3, 1)plt.bar(data1.index, data1['影视飓风'], color='green', edgecolor='black')plt.title('活跃度分析(影视飓风)')plt.xlabel('指标')plt.ylabel('数量')for i in range(len(data1)):plt.text(i, data1['影视飓风'].iloc[i], f'{data1["影视飓风"].iloc[i]:.0f}', ha='center', va='bottom')# 绘制何同学的条形图plt.subplot(1, 3, 2)plt.bar(data2.index, data2['何同学'], color='orange', edgecolor='black')plt.title('活跃度分析(何同学)')plt.xlabel('指标')plt.ylabel('数量')for i in range(len(data2)):plt.text(i, data2['何同学'].iloc[i], f'{data2["何同学"].iloc[i]:.0f}', ha='center', va='bottom')# 绘制双柱状图ax3 = plt.subplot(1, 3, 3)plot_double_bar(ax3, s_d, s_d.index, '活跃度比对', '指标', '数量', 'green', 'orange')plt.tight_layout()plt.show()
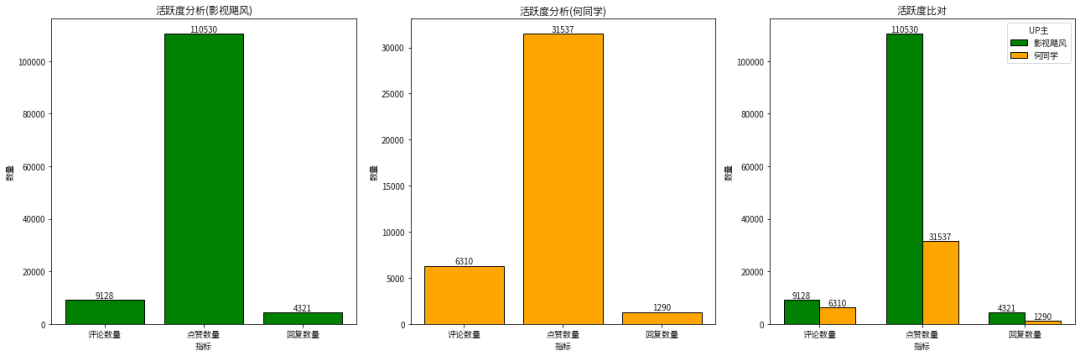
结论:
1、影视飓风的评论数量为9128,点赞数量为110530,回复数为4321
2、何同学的评论数量为6310,点赞数量为31537,回复数量为1290
3、整体上看,影视飓风视频的评论活跃度高于何同学的。
# 点赞数最高的10条评论df_like1 = df1.nlargest(10, '点赞数')[['评论内容', '点赞数']]df_like2 = df2.nlargest(10, '点赞数')[['评论内容', '点赞数']]print(df_like1)print(df_like2)
评论内容 点赞数4709 iPhone最大的贡献,就是给up主们提供了素材,一部iPhone就可以连发三四条视频 135354397 视频太棒了,完全打消我买的欲望 118648109 不得不承认的是,库克时代的iPhone 自从X系列以后,再也没有那种发布后,让人忍不住好奇畅... 71387832 影视飓风的视频比iOS18的果味更足[doge] 63126185 影视飓风真的很适合测苹果,完全就是扬长避短的典范(褒义)苹果性能部分感觉真没啥好讲的,要说期... 53776836 今年刚入行手机行业(小米之家卖手机),每天接触大量用各种各样手机的用户,也渐渐懂的手机的一点... 49908375 省流:更大的屏幕,更便捷的相机控制,几乎没有对手的视频功能,更好的超广角,更好的续航,散热[... 33125472 我从16年至今一直是双持党,果子机型体验过6s,6splus,8,8plus,X,Xs ma... 22226840 本人苹果店员(非授权店)据我这两年半的观察,现在买苹果的基本都是抱着我就想要个苹果,至于他是... 21453850 苹果缺点那么多,还是有那么多人喜欢它,营销观念和生态系统打造出来的用户粘性真的高。2105评论内容 点赞数4064 这年头60hz屏幕和128G内存可不好买到,得跟厂家定制,所以标准版成本不低,所以标准版性价... 37494613 这个按钮就跟何同学的发明一样 33092826 您猜怎么着,我奶奶的多功能老人机上有一个按钮,正常情况下能开手电筒,照相机状态下能拍照 24434567 这是何同学对于iPhone 16感想总结:\n虽然每年大家都说苹果挤牙膏,但是苹果还是在努力... 23435386 在智能手机方面,苹果已经接近巅峰,不会出现一个打败苹果的智能手机。\n但正如诺基亚也不会被按... 22193691 看完了何同学的视频,我深刻认识到了一个道理,即为:入关后,自有大儒来辩经 17073284 按钮的作用跟何同学一样 16511401 按钮的作用跟何同学一样 15695301 这个按钮就跟何同学的发明一样 10471221 按钮的作用跟何同学一样 734
结论:
从点赞数前十的评论内容来看
1、影视飓风的评论内容更为多元
2、何同学的评论内容有5条较为相似
df_comment1 = df1.nlargest(10, '回复数')[['评论内容', '回复数']]df_comment2 = df2.nlargest(10, '回复数')[['评论内容', '回复数']]print(df_comment1)print(df_comment2)
评论内容 回复数6836 今年刚入行手机行业(小米之家卖手机),每天接触大量用各种各样手机的用户,也渐渐懂的手机的一点... 2806304 手持 13 Pro,由于电量已经衰减不少,有点想换了。现在在纠结要不要买港版\n\n1. 港... 2678109 不得不承认的是,库克时代的iPhone 自从X系列以后,再也没有那种发布后,让人忍不住好奇畅... 1675472 我从16年至今一直是双持党,果子机型体验过6s,6splus,8,8plus,X,Xs ma... 1353850 苹果缺点那么多,还是有那么多人喜欢它,营销观念和生态系统打造出来的用户粘性真的高。1105039 tim让果子整点实用的,昨天合肥地震,别人的手机都有预警,果子没有[大哭][大哭][大哭][... 1084397 视频太棒了,完全打消我买的欲望 994821 很多人都没搞懂一件事,就是新增的某某功能在别的手机也有,或者和别的地方也有,我想告诉你的是,... 963276 手机小白想蹲个大佬,我之前一直是华为,但是马上要出国留学,所以想换个苹果。看下来国内好像是个... 846584 看完以后,想起来何同学对iPad的一个评价:没短板,没妥协,没必要\n 相信好多人看完i... 83评论内容 回复数5386 在智能手机方面,苹果已经接近巅峰,不会出现一个打败苹果的智能手机。\n但正如诺基亚也不会被按... 3533284 按钮的作用跟何同学一样 914613 这个按钮就跟何同学的发明一样 444567 这是何同学对于iPhone 16感想总结:\n虽然每年大家都说苹果挤牙膏,但是苹果还是在努力... 374064 这年头60hz屏幕和128G内存可不好买到,得跟厂家定制,所以标准版成本不低,所以标准版性价... 343158 期待何同学做三折叠,我觉得这完全符合一个有趣的产品,值得单开一期。311401 按钮的作用跟何同学一样 244354 感觉手机真的是到顶了,不光是苹果,国内厂商这边无非也就是拍的更清楚一点,芯片更快一点这样的升... 225301 这个按钮就跟何同学的发明一样 193691 看完了何同学的视频,我深刻认识到了一个道理,即为:入关后,自有大儒来辩经 18
结论:从评论内容来看,点赞数与回复数较高的内容有重复,说明两者之间可能存在一定关系,可以进一步探索。
df1['评论时间'] = pd.to_datetime(df1['评论时间'])df2['评论时间'] = pd.to_datetime(df2['评论时间'])df1['评论时间'] = df1['评论时间'].dt.datedf2['评论时间'] = df2['评论时间'].dt.dateplt.figure(figsize=(20, 6))plt.subplot(1,2,1)df1.groupby('评论时间')['评论内容'].count().plot(kind='bar',color='green')plt.title('评论数随着时间的变化(影视飓风)')plt.xlabel('评论时间')plt.ylabel('评论数')plt.subplot(1,2,2)df2.groupby('评论时间')['评论内容'].count().plot(kind='bar',color='orange')plt.title('评论数随着时间的变化(何同学)')plt.xlabel('评论时间')plt.ylabel('评论数')plt.tight_layout()plt.show()
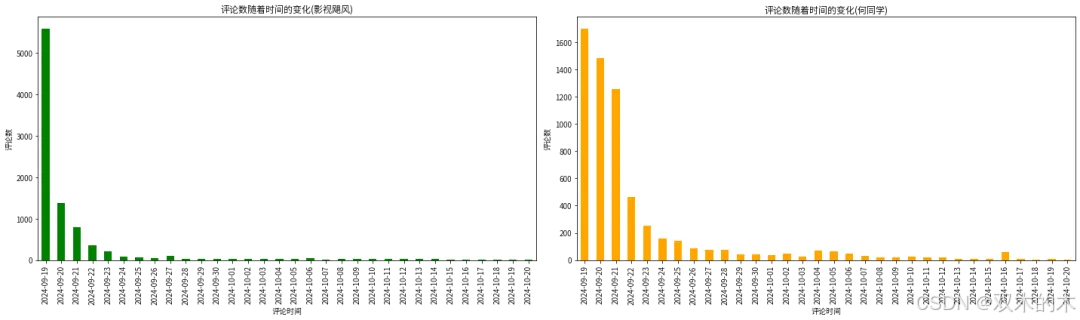
结论:两个视频都是9月19日发布的,所以评论数量集中在9月19日,之后随着时间的变化,评论数量逐步下降。
# 读取评论内容df1['评论内容'] = df1['评论内容'].astype(str)text = " ".join(df1['评论内容'])# 读取图片并转换为数组png_path = '/home/mw/project/iphone.png'iphone_mask = np.array(Image.open(png_path))# 读入停用词表exclude = []with open(r'/home/mw/project/中文停用词库.txt', 'r') as f:lines = f.readlines()for line in lines:exclude.append(line.strip())# 使用jieba进行中文分词words = ' '.join(jieba.cut(text))# 制作词云图wordcloud = WordCloud(width=1000, height=700, background_color='white',font_path = '/home/mw/project/MiSans-Regular.ttf',max_words=2000, max_font_size=100,random_state=42, mask=iphone_mask, scale=2, collocations=False).generate(words)plt.figure(figsize=(20, 20)) # 设置图形窗口的大小plt.imshow(wordcloud, interpolation='bilinear')plt.axis("off")plt.show()

# 读取评论内容df2['评论内容'] = df2['评论内容'].astype(str)text = " ".join(df2['评论内容'])# 读取图片并转换为数组png_path = '/home/mw/project/iphone.png'iphone_mask = np.array(Image.open(png_path))# 读入停用词表exclude = []with open(r'/home/mw/project/中文停用词库.txt', 'r') as f:lines = f.readlines()for line in lines:exclude.append(line.strip())# 使用jieba进行中文分词words = ' '.join(jieba.cut(text))# 制作词云图wordcloud = WordCloud(width=1000, height=700, background_color='white',font_path = '/home/mw/project/MiSans-Regular.ttf',max_words=2000, max_font_size=100,random_state=42, mask=iphone_mask, scale=2, collocations=False).generate(words)plt.figure(figsize=(20, 20)) # 设置图形窗口的大小plt.imshow(wordcloud, interpolation='bilinear')plt.axis("off")plt.show()

案例来源:
https://www.heywhale.com/mw/project/67184f44f320a7e988f4d117
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









