







本文来源公众号“OpenCV与AI深度学习”,仅用于学术分享,侵权删,干货满满。
原文链接:提升小水果检测效果:基于块技术的零样本RT-DETR与YOLO-WORLD
本文主要分成两个部分。首先,我们将深入研究RT-DETR和YOLO-WORLD模型。然后,我们将继续讨论基于补丁的技术,如SAHI和其他类似方法。最后,我将总结一下检测效果。
现在我们先来谈谈 RT-DETR 以及它为什么如此酷!
RT-DETR:实时端到端物体检测器
lyuwenyu/RT-DETR:[CVPR 2024] 官方 RT-DETR (RTDETR paddle pytorch),实时检测变压器,DETR 在实时物体检测上击败 YOLO。🔥 🔥 🔥
https://github.com/lyuwenyu/RT-DETR?tab=readme-ov-file创建 RT-DETR 的研究人员希望开发一种超快速的物体检测系统,能够非常准确地识别图像中的物体。他们研究了两种主要方法:
1. DETR模型——这些模型非常酷,因为它们可以检测物体而不需要非最大抑制等一系列额外步骤。但问题是它们的计算成本很高,因此运行速度很慢。
2. YOLO模型——以速度超快而闻名,但它们并不总是能获得最好的准确度。
因此,RT-DETR 团队想出了一些巧妙的想法,制作了一个基于 DETR 的模型,可以在速度和准确性上击败 YOLO :
-
-
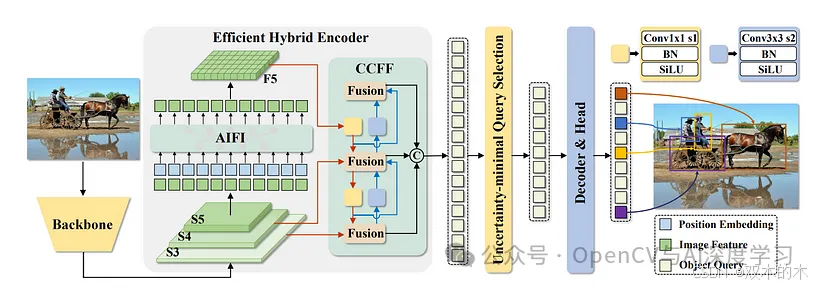
他们通过分离不同尺度的特征处理,使模型的编码器部分更加高效。这让它运行得更快。
-
他们还找到了一种巧妙的方法来选择输入到模型解码器部分的初始对象猜测。这提高了准确率。
-
另一个巧妙之处在于 RT-DETR 让您通过更改一个设置轻松调整速度,而无需重新训练整个模型。
-
YOLO-World:零样本物体检测
AILab-CVC/YOLO-World:[CVPR 2024] 实时开放词汇对象检测
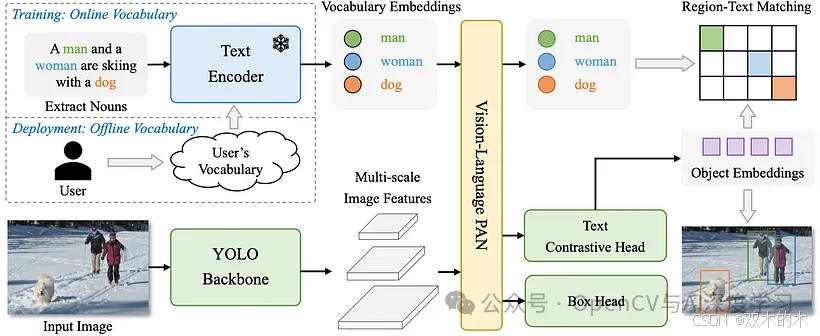
https://github.com/AILab-CVC/YOLO-World- 无需先接受“零样本学习”训练,即可识别图像中的物体
- 通过将视觉模型(擅长分析图像)与语言模型(擅长理解文本)相结合来工作
- 你提供一张图像和一段关于它要检测的内容的描述,它就会判断出物体是什么
- 使用更快的 YOLO 架构实现实时性能,同时不牺牲准确性
- 克服了以前使用缓慢、复杂的 Transformer 模型的零样本检测器的局限性
测试图像

无人机拍摄龙眼试验图像
使用YOLO-WORLD预测(不包括Patch-Based)
模型:yolov8x-worldv2.pt
预测结果跟原图一样:

使用YOLO-WORLD预测(使用SAHI)
模型:yolov8x-worldv2.pt(相同模型)
预测结果有改善,但还是很糟糕:
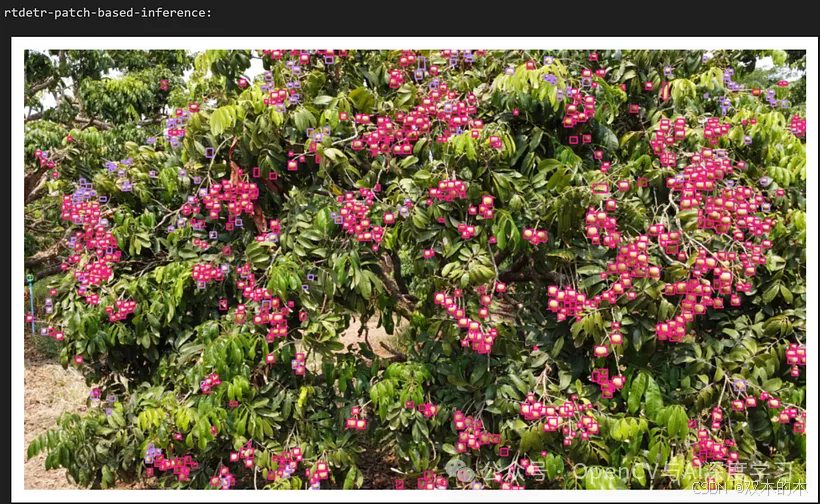
预测使用 RTDETR 和 RTDETR Patch-Based
基本RTDETR推理

RTDETR Patch-Based的推理(效果最佳)
THE END !
文章结束,感谢阅读。您的点赞,收藏,评论是我继续更新的动力。大家有推荐的公众号可以评论区留言,共同学习,一起进步。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









