




 本文深入探讨Transformer模型,重点介绍Encoder和Decoder的结构。Encoder由6个包含多头self-attention和前馈神经网络模块的大块堆叠组成,每个大块的输入不同。Decoder同样由6个大块构成,包含多头self-attention、Encoder-Decoder attention和前馈神经网络,其输入处理方式在训练和测试阶段有所不同。在实际应用中,Decoder的输入处理可通过mask策略实现。
本文深入探讨Transformer模型,重点介绍Encoder和Decoder的结构。Encoder由6个包含多头self-attention和前馈神经网络模块的大块堆叠组成,每个大块的输入不同。Decoder同样由6个大块构成,包含多头self-attention、Encoder-Decoder attention和前馈神经网络,其输入处理方式在训练和测试阶段有所不同。在实际应用中,Decoder的输入处理可通过mask策略实现。
知乎专栏:10分钟带你深入理解Transformer原理及实现
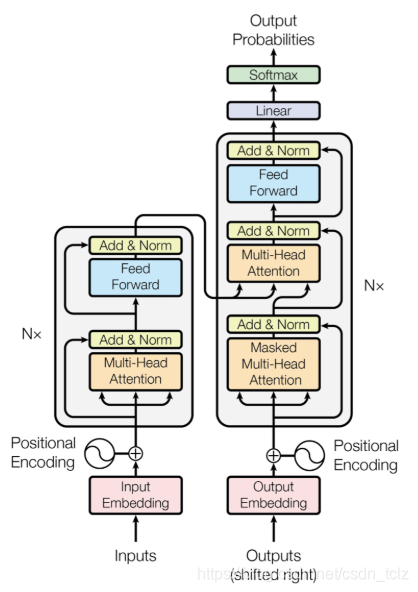
关于encoder和decoder
Encoder总览
Encoder端由N(原论文中N=6)个相同的大模块堆叠而成,其中每个大模块又由两个子模块构成,这两个子模块分别为多头self-attention模块,以及一个前馈神经网络模块。
需要注意的是,Encoder端每个大模块接收的输入是不一样的,第一个大模块(最底下的那个)接收的输入是输入序列的embedding(embedding可以通过word2vec预训练得来),其余大模块接收的是其前一个大模块的输出,最后一个模块的输出作为整个Encoder端的输出。
Decoder总览
Decoder端同样由N(原论文中N=6)个相同的大模块堆叠而成,其中每个大模块则由三个子模块构成,这三个子模块分别为多头self-attention模块,多头Encoder-Decoder attention交互模块,以及一个前馈神经网络模块。
同样需要注意的是,Decoder端每个大模块接收的输入也是不一样的,其中第一个大模块(最底下的那个)训练时和测试时的接收的 输入是不一样的,并且每次训练时接收的输入也可能是不一样的(也就是模型总览图示中的shifted right),其余大模块接收的是同样是其前一个大模块的输出,最后一个模块的输出作为整个
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1330
1330

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









