




爬取公众号所有文章
想要爬取微信公众号的所有文章,微信只有文章是有地址的,如何找到这个公众号的所有文章呢?
找到该公众号的链接
打开公众号平台,找到创作图文消息

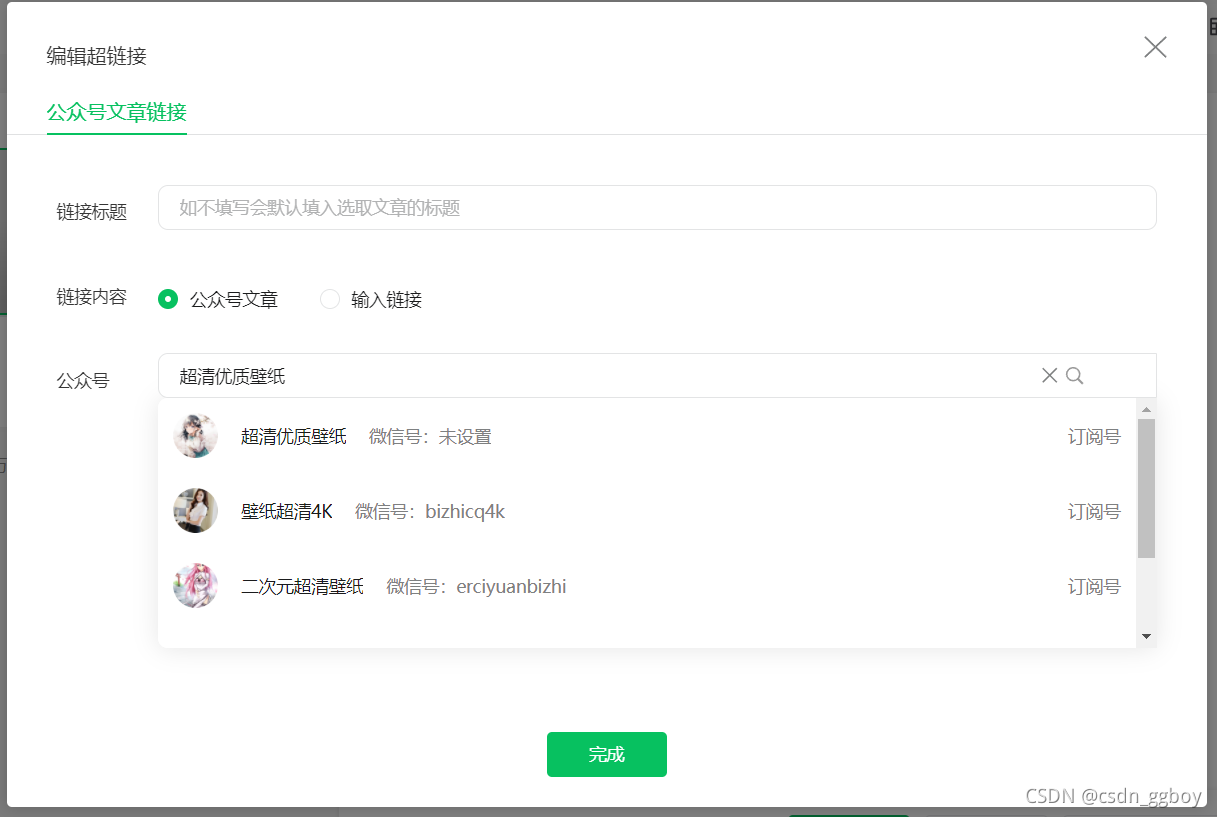
这样就找到了微信号
打开检查模式,选择Network, 选择你要爬取的公众号,发现Network中刷新出了一个开头为“appmsg”开头的内容,这就是我们要分析的目标。
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
import json
import requests
import time
import random
import yaml
with open("wechat.yaml", "r") as file:
file_data = file.read()
config = yaml.safe_load(file_data)
headers = {
"Cookie": config['cookie'],
"User-Agent": config['user_agent']
}
# https://mp.weixin.qq.com/cgi-bin/appmsg?action=list_ex&begin=0&count=5&fakeid=Mzg4ODU4MzYwNw==&type=9&query=&token=518606061&lang=zh_CN&f=json&ajax=1
# 请求参数
url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = "0"
params = {
"action": "list_ex",
"begin": begin,
"count": "5",
"fakeid": config['fakeid'],
"type": "9",
"token": config['token'],
"lang": "zh_CN",
"f": "json",
"ajax": "1"
}
# 存放结果
app_msg_list = []
# 在不知道公众号有多少文章的情况下,使用while语句
# 也方便重新运行时设置页数
with open("app_msg_list.csv", "w", encoding='utf-8') as file:
file.write("文章标识符aid,标题title,链接url,时间time\n")
i = 0
while True:
begin = i * 5
params["begin"] = str(begin)
# 随机暂停几秒,避免过快的请求导致过快的被查到
time.sleep(random.randint(1, 10))
resp = requests.get(url, headers=headers, params=params, verify=False)
print(resp.text)
# 微信流量控制, 退出
if resp.json()['base_resp']['ret'] == 200013:
print("frequencey control, stop at {}".format(str(begin)))
time.sleep(3600)
continue
# 如果返回的内容中为空则结束
if len(resp.json()['app_msg_list']) == 0:
print("all ariticle parsed")
break
msg = resp.json()
if "app_msg_list" in msg:
for item in msg["app_msg_list"]:
info = '"{}","{}","{}","{}"'.format(str(item["aid"]), item['title'], item['link'], str(item['create_time']))
with open("app_msg_list.csv", "a", encoding='utf-8') as f:
f.write(info + '\n')
print(f"第{i}页爬取成功\n")
print("\n".join(info.split(",")))
print("\n\n---------------------------------------------------------------------------------\n")
# 翻页
i += 1
爬取图片
找到网址就可以爬取文章中的所有图片了。
import requests
from bs4 import BeautifulSoup
import re
import os
import csv
import socket
import time
t_default = 30
socket.setdefaulttimeout(20)
def countFile(dir):
if not os.path.isdir(dir):
return 0
tmp = 0
for item in os.listdir(dir):
if os.path.isfile(os.path.join(dir, item)):
tmp += 1
else:
tmp += countFile(os.path.join(dir, item))
return tmp
def getHTMLText(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return ""
def getimgURL(html):
soup = BeautifulSoup(html , "html.parser")
adlist=[]
for i in soup.find_all("img"):
try:
ad= re.findall(r'.*src="(.*?)?" .*',str(i))
if ad :
adlist.append(ad)
except:
continue
return adlist
def download(adlist,root):
#注意更改文件目录
file_len = countFile(root)
#root="./out/"
for i in range(len(adlist)):
path=root+str(i + file_len + 1)+"."+"png"
print(path)
if not os.path.exists(root):
os.mkdir(root)
if not os.path.exists(path):
r=requests.get(adlist[i][0])
with open(path,'wb') as f:
f.write(r.content)
f.close()
r.close()
time.sleep(1)
print("Next!")
def img_pachong(title,url):
html = getHTMLText(url)
list = getimgURL(html)
path = "./out/"
if "真人" in title:
path = path + "真人/"
elif ("动漫" or "二次元") in title :#非常重要的括号
path = path + "动漫/"
else:
path = path + "其他/"
print(path)
#path = "./out/%s/" % title
download(list,path)
filename = "app_msg_list.csv"
with open(filename,encoding="utf-8") as f:
render = csv.reader(f)
header_row = next(render)
for row in render:
id = row[0]
title = row[1]
urls = row[2]
img_pachong(title, urls)


















 1860
1860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









