




点击上方"brucepk",选择"置顶公众号"
第一时间关注 Python 技术干货!
阅读文本大概需要 3 分钟。
经常有读者微信私聊我,问我有没有博客之类的,因为在手机上看公众号技术文章没有电脑上方便。确实,手机上看截图需要点击放大才能看得更清楚,代码也需要左右滑动才能看到全部。我的文章大部分都是首发于公众号,有时博客也会同步一份的。
其实在电脑网页上也是可以查看公众号和公众号文章的。搜狗微信搜索是搜狗在 2014 年推出的一款针对微信公众平台而设立的。我试着在搜狗微信上搜索了下我的公众号,发现通过公众号名称「brucepk」搜不到,可能是之前改过名称和公众号图片导致的吧。但是可以通过公众号的微信号搜索到,但是这样搜索出来的文章也只能展示最近发表的前 10 篇文章。

在搜狗微信上,我们也可以通过关键字去搜索公众号文章。每个关键字会查出 100 篇文章,每页显示 10 篇文章,分 10 页显示。
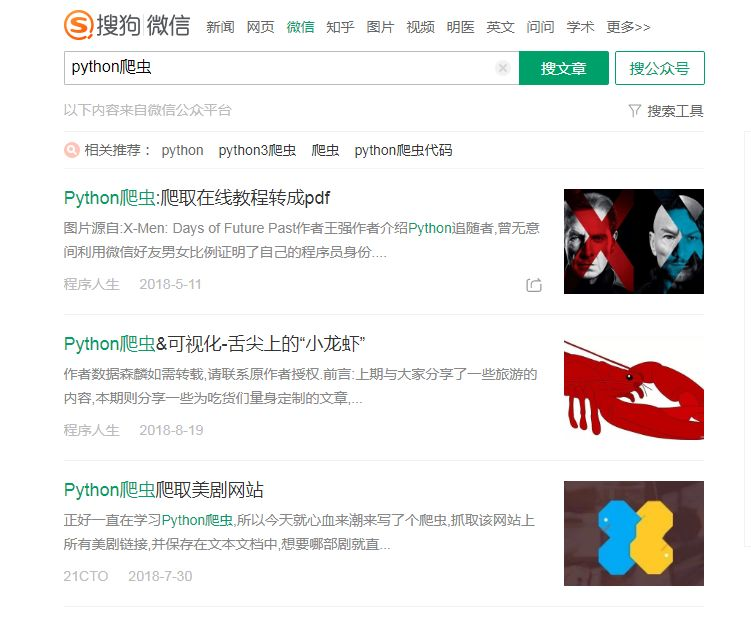
今天这篇文章我用 Python 爬虫爬取用关键字搜索出来的 100 篇文章并以 csv 文件的形式保存在本地。这篇文章代码比较简单,大佬不用往下看了,写此文的目的是为了大家在网页上更方便地阅读
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2941
2941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









