



 本文详细解析了Kafka消费端的初始化过程、订阅主题、拉取消息机制,包括分区分配、负载均衡策略以及消费者线程安全问题,重点介绍了拉取模式和不同分区分配策略的应用。
本文详细解析了Kafka消费端的初始化过程、订阅主题、拉取消息机制,包括分区分配、负载均衡策略以及消费者线程安全问题,重点介绍了拉取模式和不同分区分配策略的应用。
消费端消费流程
1)Consumer初始化
KafkaConsumer的构造方法中初始化了许多组件,重要组件如下:
- metadata:ConsumerMetadata对象,负责存储Kafka集群的元数据信息。
- client:ConsumerNetworkClient对象,上层的网络客户端,内部封装了一个NetworkClient对象,NetworkClient对象负责底层网络数据的读写。
- assignors:消费者分区分配器列表,当前消费者如果被选举为消费者组的Leader,将使用该分配器进行分区分配。
- coordinator:ConsumerCoordinator对象,消费者协调器组件,负责与服务端消费者组协调器交互。
- fetcher:Fetcher对象,实际拉取服务端消息的组件。
其他组件:
- 消费者拦截器链(可选)。
- 消费者解码器。
- 消费者数据统计器。
2)Consumer订阅主题
消费者拉取消息前,消费者需要先声明自己订阅的主题,通过KafkaConsumer#subscribe()方法实现。该方法中主要涉及一些属性的设置,大致分为以下几步:
- 1)考虑到多次订阅主题不一致的情况,调用Fetcher#clearBufferedDataForUnassignedTopics()方法移除已经接收但不在本次订阅的Topic列表中的数据。
- 2)调用SubscriptionState#subscribe()方法重置订阅的Topic列表。
- 3)调用Metadata#requestUpdateForNewTopics()方法将更新元数据的标识为needPartialUpdate设置为true,后续消费者将会发送更新元数据请求。
3)Consumer拉取消息
消费者声明订阅的主题后,调用KafkaConsumer#poll()方法进入消息拉取流程,此处为消息消费的入口,关键步骤如下:
- 1)确定消费者组中的协调器(Coordinator)并与其建立Socket连接。确定Coordinator的算法如下:
- 计算Math.abs(groupID.hashCode) % offsets.topic.num.partitions参数值(默认为50) ,假设计算得到的结果为10。
- 寻找__consumer_offsets中分区10的Leader副本所在的Broker ,该Broker即为该消费者组的Coordinator。
- 2)消费者加入消费者组。消费者组中所有消费者向Coordinator发送JoinGroup请求。Coordinator收到消费者组中所有消费者发送的JoinGroup请求后,从中选择一个消费者作为消费者组的Leader,并将所有成员信息以及他们订阅的Topic信息发送给Leader。注意:Leader是消费者组中的一个消费者实例,而Coordinator是集群的一个Broker。是Leader(不是Coordinator)负责为整个消费者组成员制定分区分配方案。
- 3)根据分区分配策略为消费者组指定分配方案。消费者加入消费者组后,由消费者组中的Leader开始制定分区分配方案,根据设定的分区分配策略,决定哪个消费者消费哪些Topic中的哪些分区,一旦分配完成,Leader会将分配方案封装成SyncGroup请求发送给Coordinator。注意:消费者组中所有消费者都会向Coordinator发送SyncGroup请求,不过只有Leader发送的请求中包含分配方案。Coordinator收到分配方案后将属于每个Consumer的分配方案单独抽取出来做作为SyncGroup请求的Response返回给各个Consumer。
- 4)消费者根据分配的分区拉取消息进行消费。先从队列缓存中获取消息记录,存在则直接返回;否则通过消费者网络通信客户端(ConsumerNetworkClient)从Broker拉取消息存入队列缓存,再返回。
- 5)消费者与协调器保持心跳连接。消费者会启动一个心跳线程与Coordinator保持连接,如果协调器返回消费者组状态变化,则进行重新加入消费者组的重平衡动作。注意:如果是消费者协调器失连,则调用AbstractCoordinator#lookupCoordinator()尝试重新连接。
整体流程如图所示:
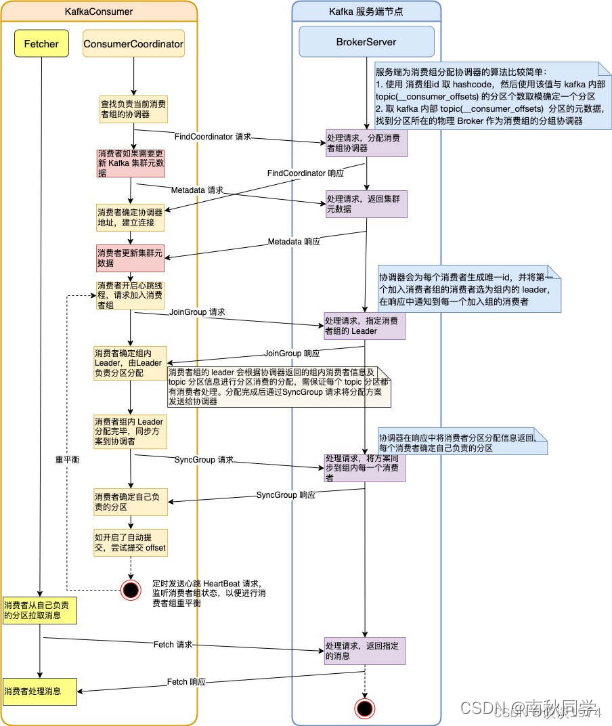
消费者消费方式
当生产者将消息发送到Kafka集群后,会转发给消费者进行消费。消息的消费模型有两种:推送模式(push)和拉取模式(pull)。
推送模式
消息的推送模式需要记录消费者的消费状态。当把一条消息推送给消费者后,需要维护消息的状态(如:标记这条消息已经被消费),这种方式无法很好地保证消息被处理。如果要保证消息被处理,发送完消息后,需要将其状态设置为已发送。收到消费者的确认收到消息后,才将其状态更新为已消费,这就需要记录所有消息的消费状态。显然这种方式不可取。这种方式还存在一个明显的缺点,就是消息被标记为已消费后,其他消费者就不能再进行消费了。
另外,推送模式消息发送速率由Broker决定,肯能由于消费端处理消息不及时,造成网络拥塞。
拉取模式
由于推送模式存在一定的缺点,因此Kafka采用消费拉取的模式来消费消息。由每个消费者维护自己的消费状态,并且每个消费者互相独立地顺序拉取每个分区的消息。消费者通过偏移量的信息来控制从Kafka中消费的消息。
由消费者通过偏移量进行消费控制的优点在于,消费者可以按照任意的顺序消费消息。如:消费者可以通过重置偏移量信息,重新处理之前已经消费过的消息;或者直接跳转到某一个偏移量位置,并开始消费。
如果消费者已经将消息进行了消费,Kafka并不会立即将消息删除,而是会将所有消息进行保存(即:持久化保存到Kafka的消息日志中)。无论消息有没有被消费,用户可以通过设置保留时间来清理过期的消息数据。
推送模式与拉取模式的区别
在推送模式下,由于消息的发送速率由Broker决定,Broker的目标是尽可能以最快的速度传递消息。因此,很难适应消费速率不同的消费者,从而造成消费者来不及处理消息。消费者来不及处理消息就可能造成消息的阻塞,从而降低系统的处理能力。
在拉取模式下,用户可以根据消费者的处理能力调整消息消费的速率,但在这种模式下也存在一定的缺点。如果消息的生产者没有产生消息,就可能造成消费者陷入循环中,一直等待数据到达。为了避免这种情况出现,消费者在拉取消息时会传入一个时长参数(timeout),如果当前没有可拉取的消息,消费端会等待一段时间(timeout)后再进行拉取。
Kafka消费端采用拉取模式(长轮询机制)从Broker中读取数据。
消费者负载均衡机制(重平衡)
重平衡本质上是一组协议,它规定了一个消费者组是如何达成一致来分配订阅Topic的所有分区的。比如:消费者组A有3个消费者实例,它要消费一个拥有6个分区的Topic,每个消费者消费Topic中的2个分区,这就是重平衡。
重平衡是相对于消费者组而言的,每个消费者组会从集群的Broker中选出一个作为组协调者(Group Coordinator)。Group Coordinator负责对整个消费者组的状态进行管理,当有触发Rebalance的条件发生时,促使生成新的分区分配方案。
重平衡触发条件
重平衡触发条件:
- 1)消费者组的成员发生变更。如:有新的消费者加入消费者组、有消费者离开消费者组、有消费者发生奔溃等。
- 2)消费者组订阅的Topic分区数发生变更。
- 3)消费者组订阅的Topic数量发生变更,这种情况主要发生在基于正则表达式订阅Topic时,当有新匹配的Topic创建时则会触发Rebalance。
其实无论哪种触发条件,根本原因是Topic中分区或者消费者实例发生了变更。
重平衡协议
重平衡本质上是一组协议,消费者组和协调器使用这组协议共同完成消费者组的重平衡。Kafka新版本提供了以下5种请求来处理重平衡:
- JoinGroup请求:消费者请求加入组。
- SyncGroup请求:消费者组的Leader将分配方案同步更新到组内所有成员中。
- Heartbeat请求:消费者定期向协调器汇报心跳,表明自己依然存活。
- LeaveGroup请求:消费者主动通知协调器自己将要离开消费者组。
- DescribeGroup请求:查看组的所有信息,包括成员信息、协议信息、分配方案以及订阅信息等。该请求主要供管理员使用,协调器不使用该请求实现Rebalance。
重平衡过程中, 协调器要处理消费者发过来的JoinGroup和SyncGroup请求 ,当消费者主动离组时会发送LeaveGroup请求给协调器。
重平衡完成后,组内所有消费者都需要定期地向协调器发送心跳(Heartbeat)请求,而每个 消费者也是根据心跳请求的响应信息中是否包含REBALANCE_IN_PROGRESS判断当前消费者组开启了新一轮重平衡。
重平衡流程
消费者组在执行Rebalance之前必须先确认Coordinator在哪个Broker上,并创建与该Broker通信的Socket连接。
确定Coordinator的算法与确定Offset被提交到__consumer_offsets目标分区的算法相同:
- 计算Math.abs(groupID.hashCode) % offsets.topic.num.partitions参数值(默认为50) ,假设计算得到的结果为10。
- 寻找__consumer_offsets中分区10的Leader副本所在的Broker ,该Broker即为该消费者组的Coordinator。
成功连接Coordinator之后,便可以执行重平衡操作,重平衡主要分为两步:加入组和同步更新分配方案。
- 加入组:消费者组中所有消费者向Coordinator发送JoinGroup请求。Coordinator收到消费者组中所有消费者发送的JoinGroup请求后,从中选择一个消费者作为消费者组的Leader,并将所有成员信息以及他们订阅的Topic信息发送给Leader。注意:Leader是消费者组中的一个消费者实例,而Coordinator是集群的一个Broker。是Leader(不是Coordinator)负责为整个消费者组成员制定分区分配方案。
- 同步更新分配方案:消费者加入消费者组后,由消费者组中的Leader开始制定分区分配方案,根据设定的分区分配策略,决定哪个消费者消费哪些Topic中的哪些分区,一旦分配完成,Leader会将分配方案封装成SyncGroup请求发送给Coordinator。注意:消费者组中所有消费者都会向Coordinator发送SyncGroup请求,不过只有Leader发送的请求中包含分配方案。Coordinator收到分配方案后将属于每个Consumer的分配方案单独抽取出来做作为SyncGroup请求的Response返回给各个Consumer。
消费者分区分配策略
一个消费者组中存在多个消费者,一个Topic中存在多个分区,所以必然会涉及
到分区分配的问题,即:确定Topic中哪个分区由消费者组中的哪个消费者进行消费。
分区分配策略有:
- Range(默认)
- RoundRobin
- Sticky
参数:
- partition.assignment.strategy:配置分区分配策略,默认为:Range。Kafka可以同时使用多个分区分配策略。
Range(范围,默认分区分配策略,按主题划分)
Range是Kafka默认的消费者分区分配策略,它针对的是Topic维度,先对同一Topic中的分区按照序号进行排序,再对消费者组中消费者按照字母顺序进行排序,保证每个消费者按照顺序消费Topic的部分分区。
例如:一个Topic有七个分区:P0、P1……P6,消费者组中有C0、C1、C2三个消费者,分配策略为:
- C0消费P0、P1、P2。
- C1消费P3、P4。
- C2消费P5、P6。
这种分配策略容易产生数据倾斜。
RoundRobin(轮询,按组划分)
RoundRoin分区分配策略是先将多个Topic中的所有分区经过hash后进行整体排序,然后以轮询的方式分配给消费者组中的消费者。如果消费者组中的所有消费者订阅了相同的主题,可以考虑这种分配策略。
Sticky(粘性)
Sticky是从Kafka0.11.x版本开始引入的分配策略,该分配策略可以理解为分配结果带有“粘性的”。即:在执行一次新的分配之前,考虑上一次分配的结果,尽量少的调整分配的变动,可以节省大量的开销。
首先会将同一Topic中的分区尽量均衡的分配给消费者,当同一消费组中的某个消费者异常退出进行重平衡时,尽量使原来分配的分区保持不变。
Sticky分区分配策略的目标有两点:
- 1)分区的分配尽量的均衡。
- 2)每一次重分配的结果尽量与上一次分配结果保持一致。
当以上两个目标发生冲突时,优先保证第一个目标。第一个目标是每个分配算法都尽量尝试去完成的,而第二个目标才真正体现出Sticky的特性。
示例:
有4个Topic:T0、T1、T2、T3,每个Topic有2个分区。
有3个Consumer:C0、C1、C2,所有Consumer都订阅了这4个分区。
如图所示:
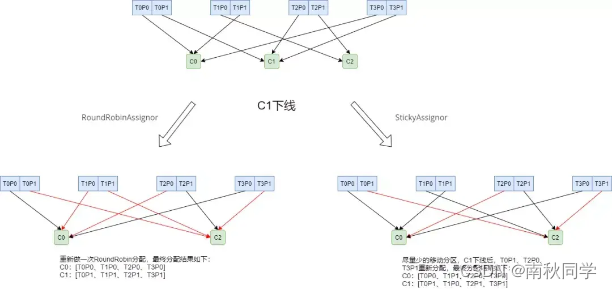
图中,红色箭头代表的是有变动的分区分配,可以看出,Sticky分配策略变动较小。
消费者线程安全问题
KafkaConsumer是非线程安全的。因为Kafka消费者使用内部状态(消费者的位置、消费者的偏移量、消费者的订阅主题和分区等)来跟踪消费进度和偏移量。如果多个线程同时访问同一个Kafka消费者实例,就会导致这些状态信息的不一致,从而导致消费进度出现错误。
KafkaConsumer非线程安全不意味着在消费消息时只能以单线程的方式执行,如果生产者发送消息的速度大于消费者处理消息的速度,就会有消息因此得不到及时处理而造成消费延迟。因此,可以采用多线程的方式来提高消费者的消费能力。
方案一:线程封闭
线程封闭指的是为每个线程实例化一个Consumer对象。使用该方式实现,一般所有的消费线程都属于同一个消费者组,一个消费线程可以消费一个或多个分区中的消息,因此并发数也受限于分区的实际个数(如果消费线程数大于分区数,就会有部分消费线程一直处于空闲状态)。
线程封闭方式的优点是每个线程可以按顺序消费各个分区中的消息;缺点是每个消费线程都要维护一个独立的TCP连接,造成额外的系统开销。
方案二:多线程处理消息
消费者吞吐量的瓶颈在处理消息的效率上,为了每个消费者维护一个单独线程会造成额外的系统开销,可以使用Reactor模型。即:消费者线程专门用来接收消息,接收到消息后采用多线程的方式(线程池)来处理消息。
这种方式解决了系统开销问题,缺点是无法对于消息按顺序进行处理,需要做额外的开发来保障。此外,如果需要手动提交,该种方式的实现也更加困难,存在数据丢失的风险。

















 431
431

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









