



 本文详细解析了KafkaBroker如何处理客户端请求,包括元数据请求、生产者请求(如acks参数)、消费者请求(如长轮询)以及Fetch请求的流程,涉及网络线程、IO线程池和数据同步策略。
本文详细解析了KafkaBroker如何处理客户端请求,包括元数据请求、生产者请求(如acks参数)、消费者请求(如长轮询)以及Fetch请求的流程,涉及网络线程、IO线程池和数据同步策略。
Broker请求处理
Broker的主要工作是处理客户端、Partition副本和控制器发送给Partition Leader的请求。Kafka提供了一个二进制协议(基于TCP),指定了请求消息的格式以及Broker如何对请求作出响应。
如图所示:
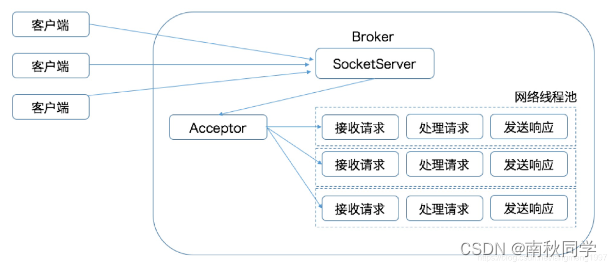
图中,Kafka的Broker端有个SocketServer组件,类似于Reactor模式中的Dispatcher,它也有对应的Acceptor线程和一个工作线程池(即:网络线程池)。Kafka提供了Broker端参数num.network.threads,用于调整该网络线程池的线程数。其默认值是3,表示每台Broker启动时会创建3个网络线程,专门用于处理客户端发送的请求。
Acceptor线程采用轮询的方式将待处理请求公平地发到所有网络线程中。这种轮询策略编写简单,同时也避免了请求处理的倾斜。
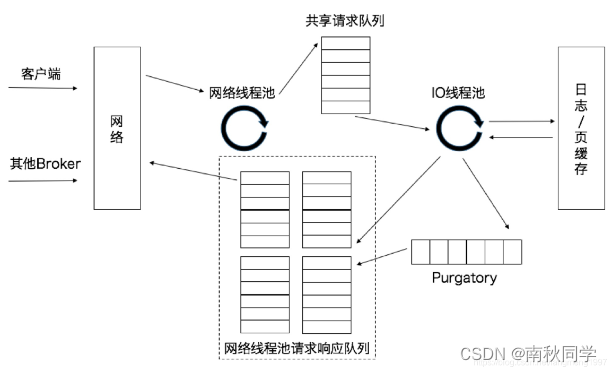
客户端请求被Broker端的Acceptor线程分发到任意一个网络线程中进行处理,当网络线程接收到请求后,Kafka又做了一层异步线程池的处理,如图所示:
其中:
- 当网络线程拿到请求后,将请求放入到一个共享请求队列中。Broker端有一个IO线程池,负责从共享请求队列中取出请求,执行真正的处理。如果是Producer请求,则将消息写入到底层的磁盘日志中;如果是Fetch请求,则从磁盘或页缓存中读取消息。
- IO线程池处中的线程才是执行请求逻辑的线程。Broker端参数num.io.threads控制了IO线程池中的线程数,默认值为8,表示每台Broker启动后自动创建8个IO线程处理请求。如果机器上的CPU资源非常充裕,可以调大该参数,以便允许更多的并发请求同时被处理。当IO线程处理完请求后,会先将生成的响应信息发送到网络线程池的响应队列中,再由对应的网络线程将响应信息返回给客户端。
- purgatory(炼狱缓冲区):当acks被设为all时,会将生产者请求放置在purgatory缓冲区中等待其他的副本写入完成。
Broker请求处理类型
Broker处理的请求类型主要有:元数据请求、生产者请求、消费者请求。
元数据(Metadata)请求
生产者请求和Fetch请求都是由每个分区的的Leader副本来处理。如果生产者将请求发到了Follower副本上,会返回一个类似“我不是Leader”的错误响应,将请求发送Leader副本通过客户端向Broker获取元数据信息来保证。
客户端发送的元数据请求中包含了若干个Topic的名称,客户端可以向任意Broker发送元数据请求,Broker会返回客户端Topic分区对应元数据信息(如:分区Leader副本,分区Follower副本等),同时,客户端会缓存这些元数据信息,缓存过期时间由参数metadata.max.age.ms进行设置,默认为5分钟。缓存过期后,客户端会重新发送元数据请求更新元信息。
如图所示:
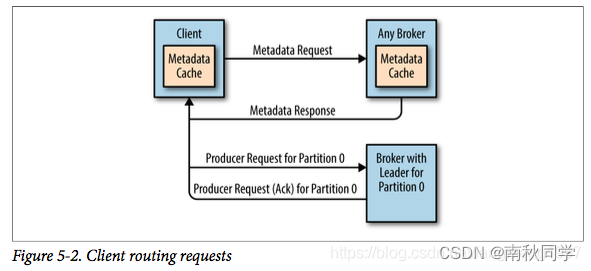
注意:客户端访问Kafka时,不需要指定全部的Broker,只需连接上集群中任意一个Broker,客户端就可以获取到所有需要访问的Broker信息,该Broker也称Bootstrap-Server。
生产者请求
生产者请求中会包含一个可配置参数acks,acks参数根据ISR中Follower与Leader的数据同步情况响应生产者消息发送结果。参数值:
- acks=0:表示无需等待Leader将消息写入磁盘,直接响应消息发送结果。
- acks=1 :表示需要等待Leader将消息写入磁盘,再响应消息发送结果。
- acks=-1(all):表示需要等到ISR中所有副本(含:Leader和Follower)将消息写入磁盘,再响应消息发送结果。
Broker收到生产消息后进行校验:
- 客户端是否有向Topic写入数据的权限。
- 请求中的acks参数取值是否合法(即:acks参数值必须为0、1、-1)。
- 如果请求中的acks参数值设置为all,检查是否有足够的副本数来确保消息安全写入(由参数min.insync.replicas设置,如果副本数小于该参数设定的值,则主副本拒绝写入消息)。
消费者请求
消费端拉取(长轮询机制)请求处理流程:
- 1)消费端拉取请求先到达指定Topic分区的Leader副本上,客户端通过获取元数据信息来确保请求路由的正确性。
- 2)Leader副本在收到请求后,会先检查请求是否有效。
- 3)如果请求的偏移量存在,Broker将按照客户端指定的数量上限从分区中读取消息,再将读取到的消息返回给客户端。
客户端可以指定拉取消息的最大数据量,防止数据量过大造成客户端内存溢出。同时,客户端也可以指定拉取消息的最小数据量,当消息数据量没有达到最小数据量时,拉取请求会进入阻塞,直到有足够数量的消息才返回。指定拉取消息的最小数据量可以减少网络开销。同时,客户端还可以指定拉取请求的最大阻塞时长,达到最大阻塞时长后,即使没有足够数据的消息也会返回。
Fetch请求
Fetch请求主要用于Follower从Leader同步Topic分区消息。
Fetch请求处理采用了零拷贝技术,即:消息直接从日志文件写到网络,不经过任何缓冲区,减少了数据拷贝和缓存区管理的开销,性能极高。
Fetch请求可以指定两个参数:
- fetch.max.bytes:单次消息拉取返回的最大字节数量,默认为50M,如果一个分区的第一批消息大小大于该值也会返回。
- fetch.min.bytes:单次消息拉取返回的最小字节数量,默认为1字节。
以上两个参数存在关联参数:
- max.partition.fetch.bytes:单次拉取每一个分区的最大字节数,默认为1M。
- fetch.max.wait.ms:不满足fetch.min.bytes设定的值时,Fetch请求最大的等待时长,默认值为500m。
注意:如果Fetch请求中指定的offset只存在于Leader副本中,还没有同步到ISR中的其他Follower副本中,Leader不会返回消息而是返回一个空响应。这样做的原因是防止因Leader异常宕机而导致消息丢失(因为消息未同步到Follower,Leader宕机后重新选举出的新Leader不存在未同步的消息)。

















 577
577

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









