




 这篇博客详细介绍了如何在Excel中移动列以及快速选择大量数据。此外,还提供了Python读取和处理Excel数据的代码示例,包括将CSV和xlsx文件转化为npy格式,以及将数据写入txt文件。内容涵盖了数据切分、数据转换和数据保存等多个方面。
这篇博客详细介绍了如何在Excel中移动列以及快速选择大量数据。此外,还提供了Python读取和处理Excel数据的代码示例,包括将CSV和xlsx文件转化为npy格式,以及将数据写入txt文件。内容涵盖了数据切分、数据转换和数据保存等多个方面。
excel如何移动整列
选中这列,将鼠标移到边缘位置,按住shift,拖动到想要的位置就可以了
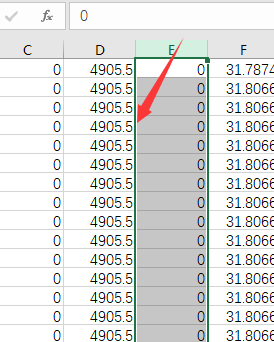
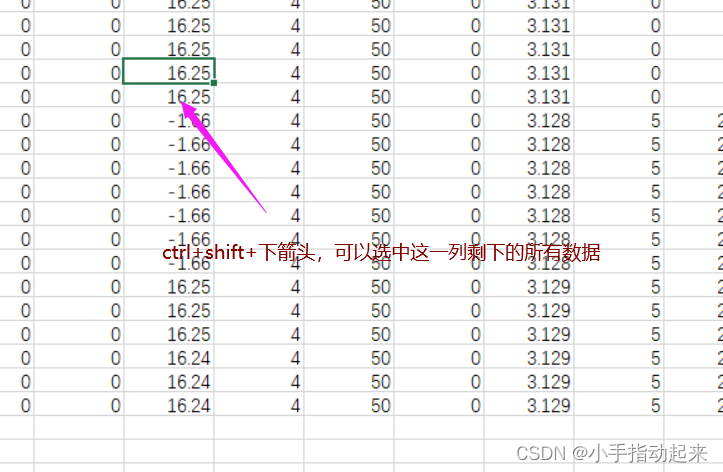
excel快速选中很大一片区域
记住最开始的一个
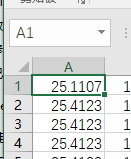
点击想删除的区域最右下角哪一个
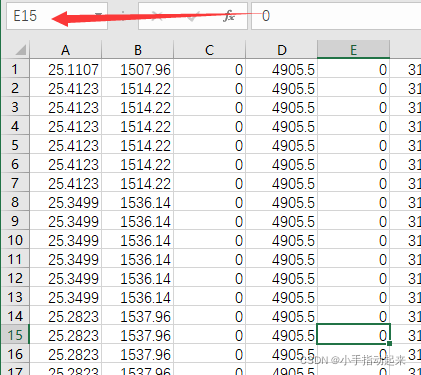
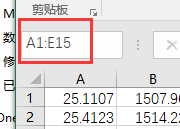
输入开始的那个位置+:再回车就可以选中以这两个点为对角线的所有数据了。
快捷键:选中当前数据上下左右的所有数据
ctrl+shift+←/→/↑/↓ctrl+shift+\larr / \rarr/ \uarr/ \darrctrl+shift+←/→/↑/↓
python读取excel数据代码
import numpy as np
import csv # 读取csv文件
import xlrd #读取xlsx文件
total=[]
label=[]
#读取多行多列的数据
with open('I:\\代码\\数据\\修改的数据\\8-2_27-28_产气.csv','r') as myFile:
lines=csv.reader(myFile)#所有行的数据
for line in lines: #遍历每行的数据
total.append(list(map(float,list(line)))) #转化每行的数据为数据类型为float的list
#读取一列的标签数据
l=list(xlrd.open_workbook("I:\\代码\\数据\\修改的数据\\8-2_27-28_产气_标签.xlsx").sheets()[0].col_values(0))
#读取第1个sheet的第1列的所有数据
label=list(map(int,l)) #转化为数据类型为int的列表
result=[]
result.append(total)
result.append(label)
np.save('./data/8-2_27-28_q.npy',result) #存储为拥有两个列表的列表数据,存储为npy文件
如果报错说找不到I:\\代码\\数据\\修改的数据\\8-2_27-28_产气_标签.xlsx,可能是xlrd的版本太新了,降低版本就可以了,我的版本是1.2.0
python读取csv文件转化为npy
这个新的代码可以从escel文件的第二行开始读取,并且划分为训练集、测试集、验证集。
import numpy as np
import csv # 读取csv文件
import xlrd #读取xlsx文件
import os #读取文件夹下面的文件名
#代码 WETAS Weakly Supervised Time-Series Anomaly Segmentation 输入的数据格式
#npy=([数据],[标签],(总条数,维度))
def get_WTAS_data(str):
total=[]
label=[]
#读取多行多列的数据
with open(str,'r') as myFile:
lines=csv.reader(myFile) #所有行的数据
next(lines) #跳过第一行的注释目录
for line in lines: #遍历每行的数据
total.append(list(map(float,list(line)))) #转化每行的数据为数据类型为float的list
#每行的数据最后一个是标签,将它单独取出来,并且从total中删除
for t in total:
label.append(t[-1])
t.pop(-1) #删除最后一个数
#对数据进行切片,按8:1:1划分训练集,测试集,验证集
l=len(label)+1 #数据的条数
train_len=int(l*0.8)
test_len=int(l*0.1)
vaild_len=l-train_len-test_len
train_data=total[0:train_len]
test_data=total[train_len:l-vaild_len]
vaild_data=total[1-vaild_len:l]
train_label=label[0:train_len]
test_label=label[train_len:l-vaild_len]
vaild_label=label[1-vaild_len:l]
train=[]
test=[]
vaild=[]
train.append(train_data)
train.append(train_label)
train.append((train_len,27))
s='npy\\train\\'+str[5:].replace('.csv','.npy')
np.save(s,train) #存储为npy文件'''
test.append(test_data)
test.append(test_label)
test.append((test_len,27))
s='npy\\test\\'+str[5:].replace('.csv','.npy')
np.save(s,test) #存储为npy文件'''
vaild.append(vaild_data)
vaild.append(vaild_label)
vaild.append((vaild_len,27))
s='npy\\vaild\\'+str[5:].replace('.csv','.npy')
np.save(s,vaild) #存储为npy文件'''
dirs=os.listdir('data')
for dir in dirs:
str='data\\'+dir
get_WTAS_data(str)
将csv数据转化为txt
import numpy as np
import csv # 读取csv文件
import xlrd #读取xlsx文件
import os #读取文件夹下面的文件名
import pandas as pd
#代码Anomaly Detection for Multivariate Time Series through Modeling Temporal Dependence of Stochastic Variables 输入的数据格式
#txt文件,train是数据的前半部分,test是数据的后半部分,test_label是对应的test的标签,
#interpretation_label是每个异常段:导致异常发生的维度,需要手动赋值
def Swarp_csvTo_txt(fstr):
data=[]
label=[]
#读取多行多列的数据
with open(fstr,'r') as myFile:
lines=csv.reader(myFile) #所有行的数据
next(lines) #跳过第一行的注释目录
for line in lines: #遍历每行的数据
data.append(list(map(float,list(line)))) #转化每行的数据为数据类型为float的list
#每行的数据最后一个是标签,将它单独取出来,并且从data中删除
for d in data:
label.append(d[-1])
d.pop(-1) #删除最后一个数
l=l=len(label)+1 #数据的条数
train_len=int(l*0.5)
test_len=l-train_len
train=data[0:train_len]
test=data[train_len:l]
test_label=label[train_len:l]
#写入train.txt
s='txt/train/'+fstr[5:].replace('.csv','.txt')
with open(s,'a+') as f:
for line in train:
out=list(map(float,list(line)))
m=''
for v in out:
m=m+str(v)+","
m=m[0:-2] #删掉最后一个逗号
m=m+'\n'
f.write(m)
#写入test.txt
s='txt/test/'+fstr[5:].replace('.csv','.txt')
with open(s,'a+') as f:
for line in test:
out=list(map(float,list(line)))
m=''
for v in out:
m=m+str(v)+","
m=m[0:-2] #删掉最后一个逗号
m=m+'\n'
f.write(m)
#写入test_label.txt
s='txt/test_label/'+fstr[5:].replace('.csv','.txt')
with open(s,'a+') as f:
for line in test_label:
f.write((str(line)+'\n'))
dirs=os.listdir('data') #读取目录下的所有文件名
for fdir in dirs:
instr='data/'+fdir
Swarp_csvTo_txt(instr)
将csv数据转化为npy
import pandas as pd
import numpy as np
# 先用pandas读入csv
m= pd.read_csv("MY/10.csv");
# 再使用numpy保存为npy
np.save("MY/10.npy", m);
将excel数据转化为npy2
def getMadGan_data(fstr): #读取excel文件的数据返回
total=[]
with open(fstr,'r') as myFile:
lines=csv.reader(myFile) #所有行的数据
next(lines) #跳过第一行的注释目录
for line in lines: #遍历每行的数据
total.append(list(map(float,list(line)))) #转化每行的数据为数据类型为float的list
l=len(total)
m=int(l*0.48)
test_data=total[0:m]
train_data=total[m:l]
return test_data,train_data
#将得到的数据shape=(n,),其中n表示文件个数,转化为shape=(m,n)的
def change(indata):
outdata=[]
for m in indata:
for n in m:
outdata.append(n)
return outdata
dirs=os.listdir('data')
test=[]
train=[]
for dir in dirs:
fstr='data\\'+dir
data=getMadGan_data(fstr)
test.append(data[0])
train.append(data[1])
np.save('MAD_GAN_data\\Mytrain.npy',change(train)) #存储为npy文件'''
np.save('MAD_GAN_data\\Mytest.npy',change(test)) #存储为npy文件'''
excel填充一列一样的数据
点击你想赋值的列,第一个输入你想填充的数字,拖动下方的小圆点,就可以了。

excel文件转txt文件逗号分隔
将excel另存为csv格式文件,然后用记事本打开保存后的.csv文件,再另存为.tx格式即可
交叉验证的数据集csv转化为txt
#代码Multivariate Time-series Anomaly Detection via Graph Attention Network
#交叉验证,5选1做测试集,其他合并作为训练集
import numpy as np
import csv # 读取csv文件
import xlrd #读取xlsx文件
import os #读取文件夹下面的文件名
import pandas as pd
def save_train(situation,fstr):
data=[]
#读取多行多列的数据
with open(fstr,'r') as myFile:
lines=csv.reader(myFile) #所有行的数据
next(lines) #跳过第一行的注释目录
for line in lines: #遍历每行的数据
data.append(list(map(float,list(line)))) #转化每行的数据为数据类型为float的list
#每行的数据最后一个是标签,将它单独取出来,并且从total中删除
for d in data:
label.append(d[-1])
d.pop(-1) #删除最后一个数
#写入train.txt
s=situation+'train/'+fstr[5:].replace('.csv','.txt')
with open(s,'a+') as f:
for line in data:
out=list(map(float,list(line)))
m=''
for v in out:
m=m+str(v)+","
m=m[0:-2] #删掉最后一个逗号
m=m+'\n'
f.write(m)
def get_test_lable(fstr,rdata,rlabel):
data=[]
label=[]
#读取多行多列的数据
with open(fstr,'r') as myFile:
lines=csv.reader(myFile) #所有行的数据
next(lines) #跳过第一行的注释目录
for line in lines: #遍历每行的数据
data.append(list(map(float,list(line)))) #转化每行的数据为数据类型为float的list
#每行的数据最后一个是标签,将它单独取出来,并且从total中删除
for d in data:
label.append(d[-1])
d.pop(-1) #删除最后一个数
for da in data:
rdata.append(da)
for la in label:
rlabel.append(la)
def save_test(situation,rdata,rlabel,fstr):
#写入test.txt
s=situation+'test/'+fstr[5:].replace('.csv','.txt')
with open(s,'a+') as f:
for line in rdata:
#out=list(map(float,list(line)))
m=''
for v in line:
m=m+str(v)+","
m=m[0:-2] #删掉最后一个逗号
m=m+'\n'
f.write(m)
#写入test_label.txt
s=situation+'test_label/'+fstr[5:].replace('.csv','.txt')
with open(s,'a+') as f:
for line in rlabel:
f.write((str(line)+'\n'))
dirs=os.listdir('data')
i=5
while(i>0):
print(i)
data=[]
label=[]
sub=[]
if(i==1):
sub=dirs[1:]
situation='viadata/1/'
train_path='data/'+dirs[0]
save_train(situation,train_path)
if(i==2):
sub=dirs[2:]
sub.append(dirs[0])
situation='viadata/2/'
train_path='data/'+dirs[1]
save_train(situation,train_path)
if(i==3):
sub=dirs[0:2]
sub.append(dirs[3])
sub.append(dirs[4])
situation='viadata/3/'
train_path='data/'+dirs[2]
save_train(situation,train_path)
if(i==4):
sub=dirs[0:3]
sub.append(dirs[-1])
situation='viadata/4/'
train_path='data/'+dirs[3]
save_train(situation,train_path)
if(i==5):
sub=dirs[0:-1]
situation='viadata/5/'
train_path='data/'+dirs[4]
save_train(situation,train_path)
for fdir in sub:
instr='data/'+str(fdir)
get_test_lable(instr,data,label)
save_test(situation,data,label,train_path)
i=i-1


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









