




前言
前文提到了数组和动态数组,其实除了数组这样底层是连续内存空间的结构,线性表还存在一种非连续的内存空间的结构,那便是链表,标准的定义:
链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成。每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
简单地解释一下,首先,毋庸置疑的是,链表是一种数据结构,其次它在物理地址上表现为非连续与非顺序的,与数组完全不同的,最后,链表由结点组成,所谓的结点就是对数据和其他结点地址的封装。
所以,根据定义,我们可以想象一下,最简单的结点应该是这个样子:
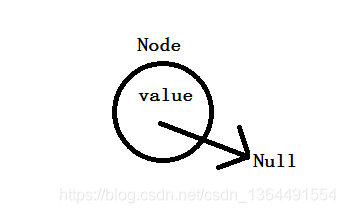
而链表就是多个这样的结点连接起来,比如这样:
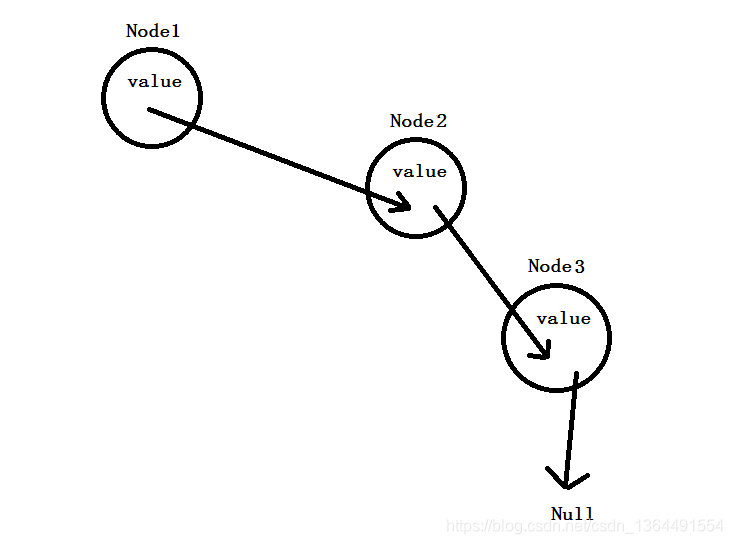
单向链表
其实,链表关键在于对引用或指针的理解,我们先实现一个单向链表。
Node
以java为例,上图中的value,其实就是数据域,在此,引入泛型支持;而上图中的指针,在java中便是引用,它代表的就是下一个Node,这里,我们用内部类来表示Node:
/**
* @program: thinking-in-all
* @description:
* @author: Lucifinil
* @create: 2019-12-27
**/
public class OneWayLinkedList<T> {
private class Node {
T value;
Node next;
Node(T value, Node next) {
this.value = value;
this.next = next;
}
Node(T value) {
this(value, null);
}
Node() {
this(null, null);
}
}
}
属性
对于链表来说,光有Node是不够的,我们需要的是,把多个Node给它联系起来,形成一个我们想要的数据结构,那么用什么来表示它们的联系呢?
其实,从上图可以看到,最好的表示方式,便是使用起始节点,这个节点包含了下一个节点的地址,而下一个节点又包含下下个节点的地址…这个起始节点,我们一般称他为链表的头(head):
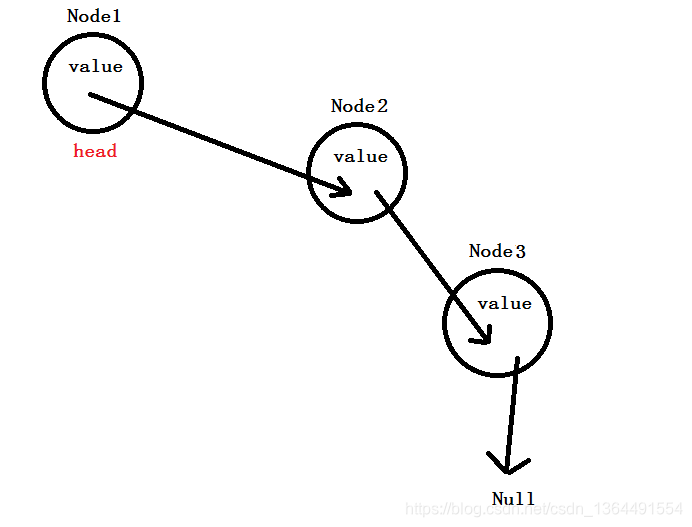
这是单向链表的实现方式之一,这种实现方式在添加第一个元素创建头结点,删除最后一个元素时删除头结点。
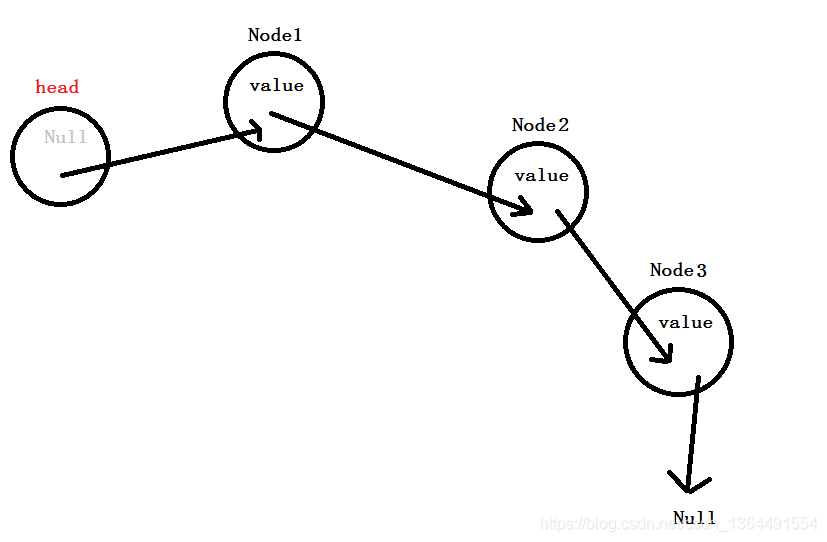
这是单向链表的另一种实现方式,使用虚拟头结点,该节点不存值,但始终存在(即head不为null,其成员为null),这种方式的好处便是,添加第一个元素和删除最后一个元素时和其他元素的增删一致,更容易理解。
这里,我们采用第二种,实现方式,两者实现的本质思想都是一致的:
定义虚拟头结点与链表元素大小:
//虚拟头结点
private Node dummyHead;
//链表元素数量
private int size;
辅助函数
//获取链表元素数量
public int size() {
return size;
}
//获取链表是否为空链表
public boolean isEmpty() {
return size == 0;
}
添加元素
这里,用一个存储Integer类型的链表来举例:
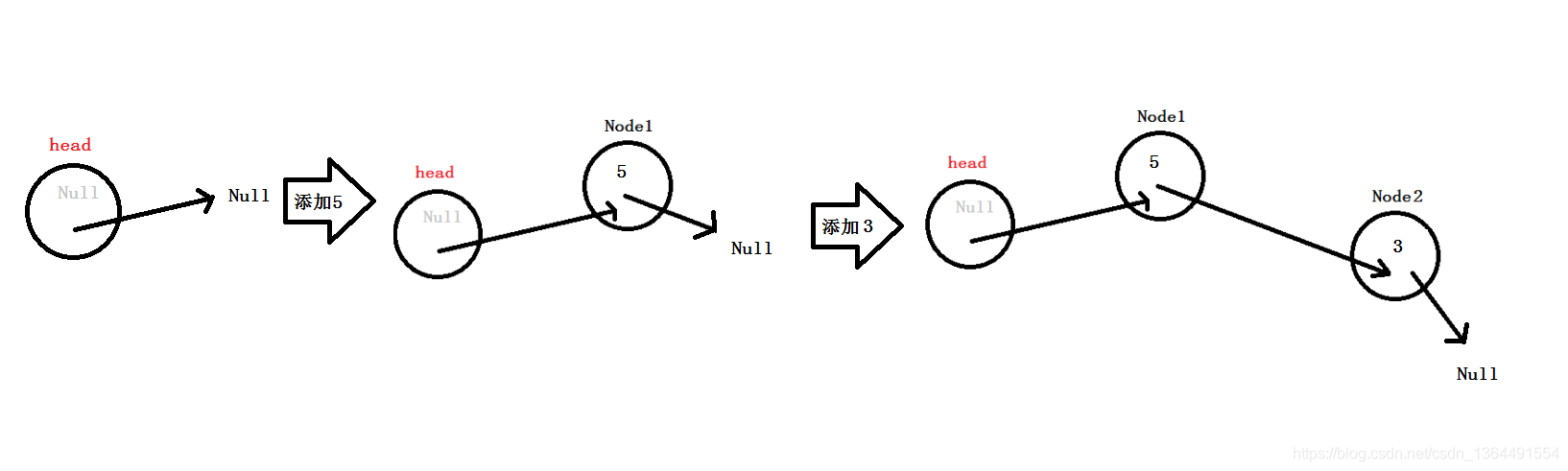
从上图,我们可以看到链表的灵活性,在末端添加元素,只需要让最后的结点指向新增结点。
这里用代码实现,可以表示为:
//给头结点添加value为5的新结点
dummyHead.next = new Node(5);
//给Node1添加value为3的新结点
Node1.next = new Node(3);
//以此类推
那么如果,要在链表中间添加结点呢?
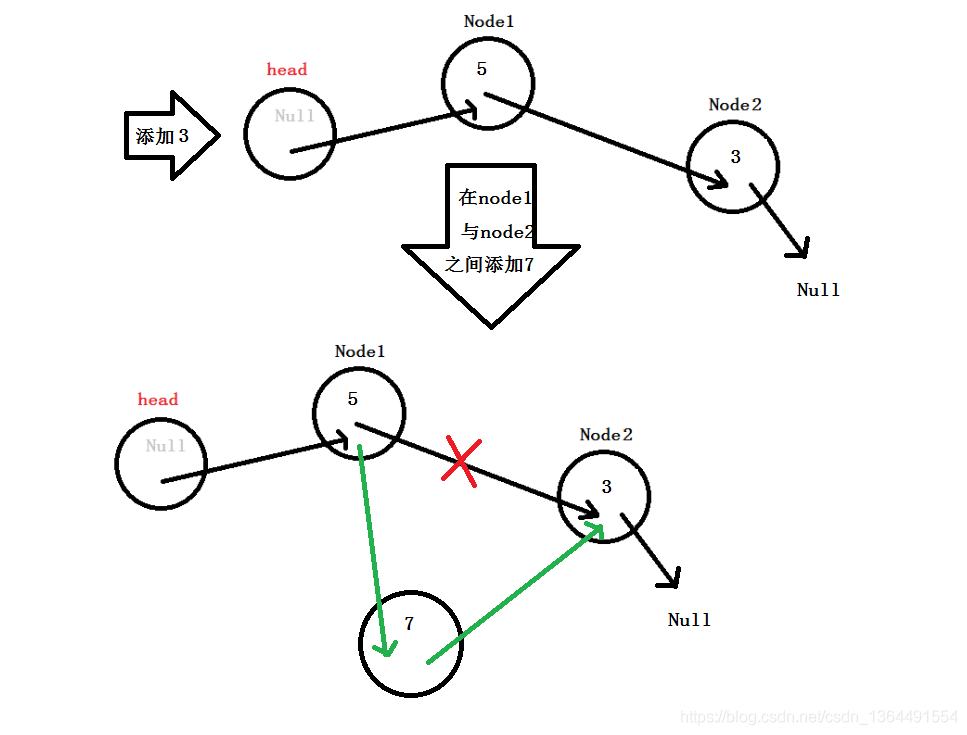
从这里,我们便看到了链表与数组相比最大的不同,当然这也是链表这种动态数据的优势所在,在链表中间添加结点,之需要使其前驱node1的地址指向新增结点node3,而新增结点node3的地址指向后继结点node2!
这里用代码实现,可以表示为:
Node node = new Node(7);
node.next = Node1.next;
Node1.next = node;
为什么比上面尾部添加更加复杂呢?其实,尾部添加是同样的思想:
//给头结点添加value为5的新结点
Node node = new Node(5);
node.next = dummyHead.next;
dummyHead.next=node;
只不过,此时的dummyHead.next为Null罢了。
我们可以看到,两种添加都需要的是新结点的前驱元素(比如Node1和dummyHead),我们将之称为当前元素的前驱元素(precursor),所以只要我们能寻找到前驱元素,便能成功添加新的元素!从前文,我们知道,每一个结点里都存了下一个结点的地址,所以遍历寻址是链表常常使用的操作:
//链表的虚拟头部,最开始的前驱结点
Node prev = dummyHead;
//注意prev的取值范围
Node prev = dummyHead;
//注意prev的取值范围
for (int i = 0; i < index; i++) {
prev = prev.next;
}
由此,我们可以得到链表添加元素的操作:
public void add(int index, T e) {
if (index < 0 || index > size) {
throw new IllegalArgumentException("Add failed.Illegal index.");
}
Node prev = dummyHead;
for (int i = 0; i < index; i++) {
prev = prev.next;
}
Node node = new Node(e);
node.next = prev.next;
prev.next = node;
size++;
}
删除元素
既然,已经有了上文的铺垫,我相信小伙伴们很快能想到删除的操作!
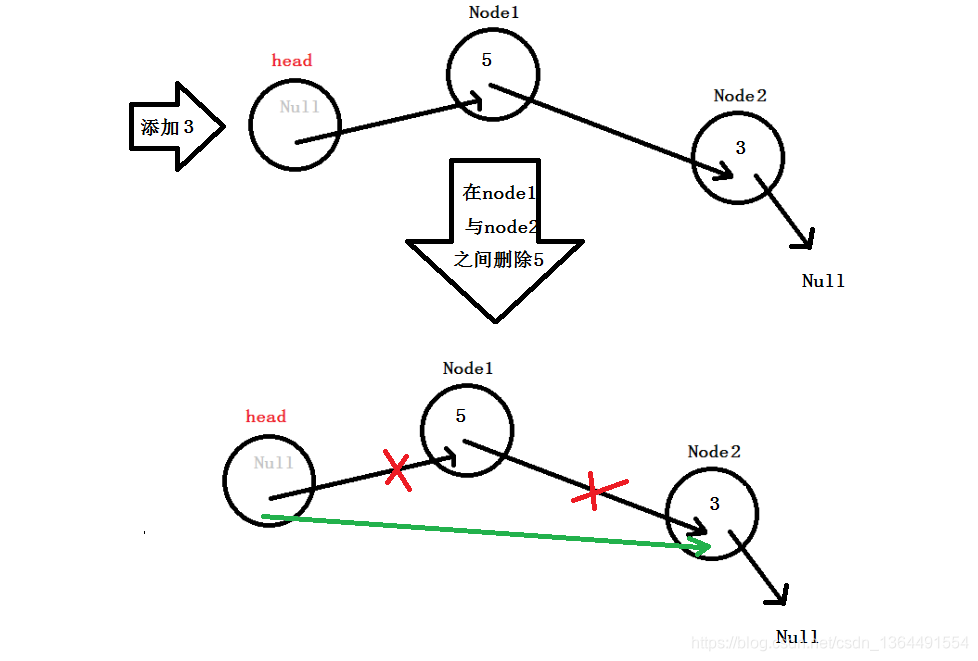
用代码实现;
public T remove(int index) {
if (isEmpty()) {
throw new IllegalArgumentException("Remove failed.Linklist is empty.");
}
if (index < 0 || index >= size) {
throw new IllegalArgumentException("Remove failed.Illegal index.");
}
Node prev = dummyHead;
for (int i = 0; i < index; i++) {
prev = prev.next;
}
Node oldNode = prev.next;
prev.next = oldNode.next;
oldNode.next = null;
size--;
return oldNode.value;
}
可能有的小伙伴要问了,为什么add是void而remove就要将删除的元素返回呢?这里我遵循的是java中List接口的add和remove的定义方式!
查改元素
相对于数组的随机访问,链表在查与改方面是比较弱势的,有得必有失嘛!毕竟,到现在还没有出现那种增删查改都是O(1)的数据结构,如果真的有的话,其他数据结构也已经没有存在的必要了!
修改元素:
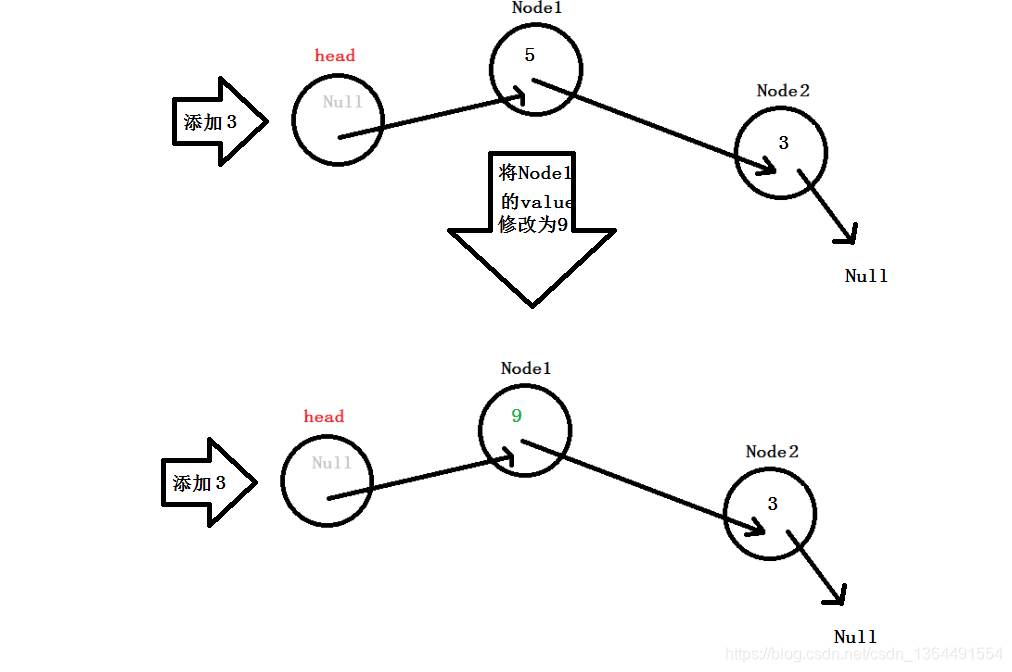
可以看到,只要能找到Node1这个节点,我们便马上能够修改元素,查询同理,前文,我们已经提到了寻找元素的方式,那便是通过头结点遍历寻找!
所以,修改代码实现为:
public void set(int index, T e) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("Set failed.Illegal index.");
}
Node cur = dummyHead.next;
for (int i = 0; i < index; i++) {
cur = cur.next;
}
cur.value = e;
}
查询代码实现为:
public T get(int index) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("Get failed.Illegal index.");
}
Node cur = dummyHead.next;
for (int i = 0; i < index; i++) {
cur = cur.next;
}
return cur.value;
}
时间复杂度分析
看到这里,我相信你已经对链表有了初步的认识,有的人常说,链表适合增删,时间复杂度为O(1),但是,从我们上面的推测过程,我们可以清楚的看到这句话的不足之处,链表增删时间复杂度为O(1)的前提是,你已经找到了想要增删结点的前驱或者后继!事实上,我们不能直接获得,因为链表的物理存储是分散的,是不连续的,不支持随机访问,我们要获得目标结点只能通过已知的参照物(单向链表的头部)来进行寻找。
所以其实链表的增删查改时间复杂度其实都是O(n),那有没有O(1)的时间复杂度呢?
答案是有,在头部进行增删改查的时间复杂度都是O(1)!所以,使用链表,我们尽量使用其头部来进行操作!
我们可以增加几个直接对头部操作的方法来完善我们的链表:
//在链表头部添加元素
public void addFirst(T e) {
add(0, e);
}
//删除链表的头部元素
public T removeFirst() {
return remove(0);
}
//得到链表的头部元素
public T getFirst() {
return get(0);
}
//修改链表的头部元素
public void setFirst(T e) {
set(0, e);
}
对于头部的操作什么时候用的比较多?
其实这是天生的栈结构!
完整代码
/**
* @program: thinking-in-all
* @description:
* @author: Lucifinil
* @create: 2019-12-27
**/
public class OneWayLinkedList<T> {
private class Node {
T value;
Node next;
Node(T value, Node next) {
this.value = value;
this.next = next;
}
Node(T value) {
this(value, null);
}
Node() {
this(null, null);
}
@Override
public String toString() {
return value.toString();
}
}
//虚拟头结点
private Node dummyHead;
//链表元素数量
private int size;
public OneWayLinkedList() {
dummyHead = new Node();
size = 0;
}
//判断链表中是否包含元素e
public boolean contains(T e) {
Node cur = dummyHead.next;
while (cur != null) {
if (cur.equals(e)) {
return true;
}
cur = cur.next;
}
return false;
}
//获取链表元素数量
public int size() {
return size;
}
//获取链表是否为空链表
public boolean isEmpty() {
return size == 0;
}
public void add(int index, T e) {
if (index < 0 || index > size) {
throw new IllegalArgumentException("Add failed.Illegal index.");
}
Node prev = dummyHead;
for (int i = 0; i < index; i++) {
prev = prev.next;
}
Node node = new Node(e);
node.next = prev.next;
prev.next = node;
size++;
}
public T remove(int index) {
if (isEmpty()) {
throw new IllegalArgumentException("Remove failed.Linklist is empty.");
}
if (index < 0 || index >= size) {
throw new IllegalArgumentException("Remove failed.Illegal index.");
}
Node prev = dummyHead;
for (int i = 0; i < index; i++) {
prev = prev.next;
}
Node oldNode = prev.next;
prev.next = oldNode.next;
oldNode.next = null;
size--;
return oldNode.value;
}
public void set(int index, T e) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("Set failed.Illegal index.");
}
Node cur = dummyHead.next;
for (int i = 0; i < index; i++) {
cur = cur.next;
}
cur.value = e;
}
public T get(int index) {
if (index < 0 || index >= size) {
throw new IllegalArgumentException("Get failed.Illegal index.");
}
Node cur = dummyHead.next;
for (int i = 0; i < index; i++) {
cur = cur.next;
}
return cur.value;
}
//在链表头部添加元素
public void addFirst(T e) {
add(0, e);
}
//删除链表的头部元素
public T removeFirst() {
return remove(0);
}
//得到链表的头部元素
public T getFirst() {
return get(0);
}
//修改链表的头部元素
public void setFirst(T e) {
set(0, e);
}
@Override
public String toString() {
StringBuilder res = new StringBuilder();
res.append("head [ ");
Node cur = dummyHead.next;
for (int i = 0; i < size; i++) {
res.append(cur.toString()).append(" -> ");
cur = cur.next;
}
res.append("NULL ]");
return res.toString();
}
}
总结
其实,本篇的链表只是链表中最简单的单向链表,作为一个应用广泛的数据结构它当然不止于此!
后续还会介绍双向链表,循环链表!
我是路西菲尔,如有错误,敬请指正,期待与你一同成长!
转载请注明出处,来自路西菲尔的博客https://blog.youkuaiyun.com/csdn_1364491554/article/details/103730341!

















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









