






QwQ-32B有哪些值得关注的技术亮点
在大模型领域,如何在性能与资源消耗之间找到平衡一直是业界关注的焦点。最近,新开源的推理模型 QwQ-32B 凭借对消费级显卡的友好支持,为开发者提供了轻量化且强大的解决方案。这一特性不仅降低了硬件门槛,还展现了其在优化和效率上的独特优势。
在正式讲解QwQ-32B 技术实现上的亮点之前,我们先来简单自己部署一下QwQ-32B 方案来亲身感受一下部署操作有多么简单。
基于 MaaS 调用 QwQ-32B API
基于MaaS调用QwQ-32B API,可以理解为基于阿里云百炼服务平台调用 QwQ-32B API,那么在开始调用 QwQ-32B API 之前,我们同样需要先获取 API-KEY。
API-KEY
在阿里云百炼平台选择左侧菜单【API-Key】,点击【创建我的API-KEY】,在弹出的弹框页面选择主账号空间,输入描述后点击【确定】完成API-KEY的创建
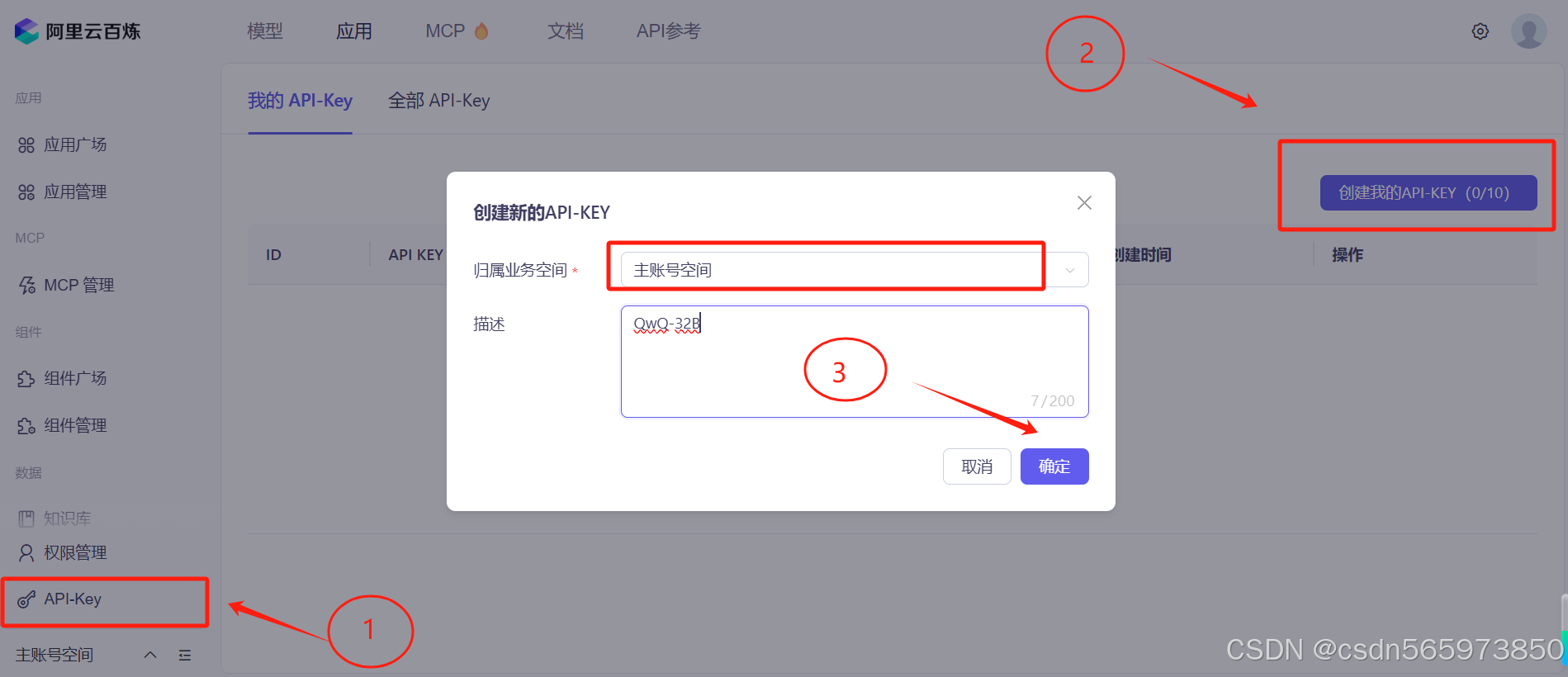
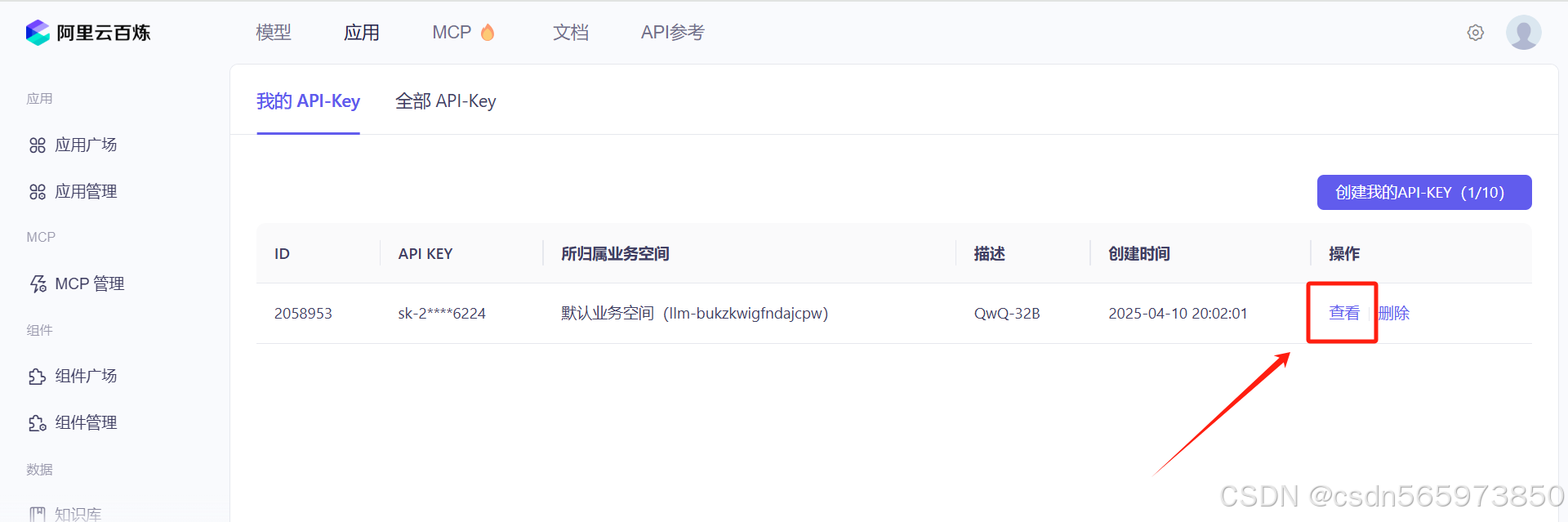
创建完成之后,在我的API-KEY列表页面点击右侧的【查看】按钮,然后点击【复制】按钮复制API-KEY备用
Chatbox客户端调用
在使用Chatbox 客户端调用之前,首先需要下载安装 Chatbox, 访问 Chatbox 下载地址下载并安装客户端,我的电脑是Windows 系统,这里我选择下载 Windows 版本的
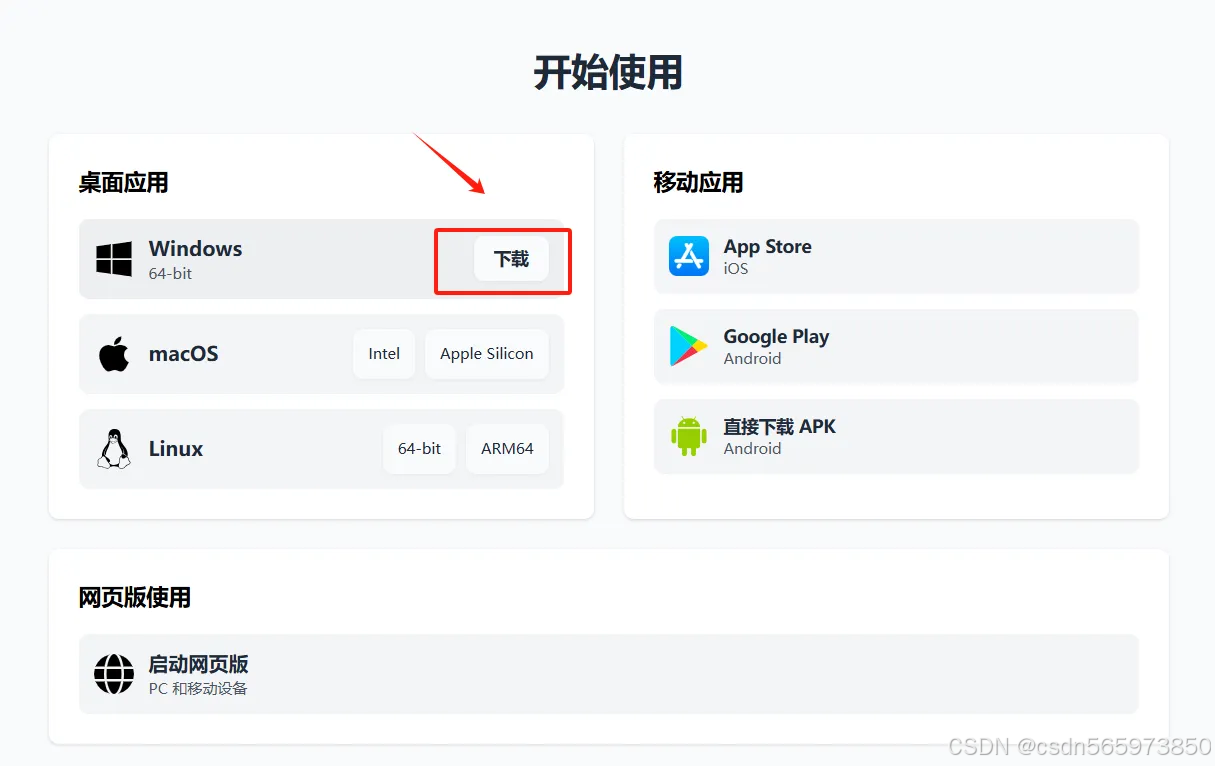
下载完成后双击安装,整个安装过程比较简单,按照默认的操作点击【下一步】即可,如果需要更换安装路径的,在选择安装路径操作页面更换自己想要安装的路径,安装完成后双击打开 Chatbox 客户端,选择【使用自己的API Key 或本地模型】
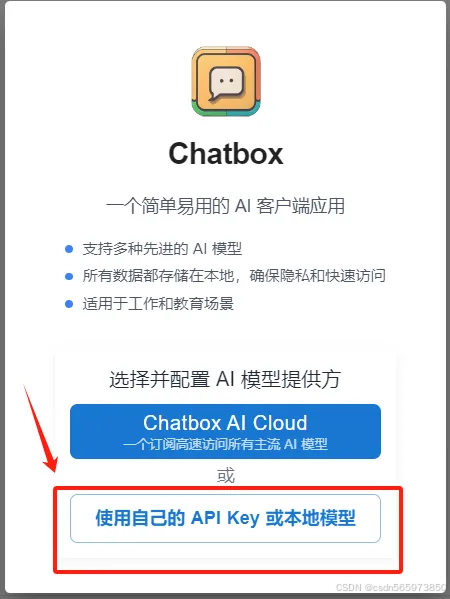
继续在【选择并配置 AI 模型提供方】的弹框页面下拉选择【添加自定义提供方】
在弹出的页面按照部署文档中的说明进行配置,
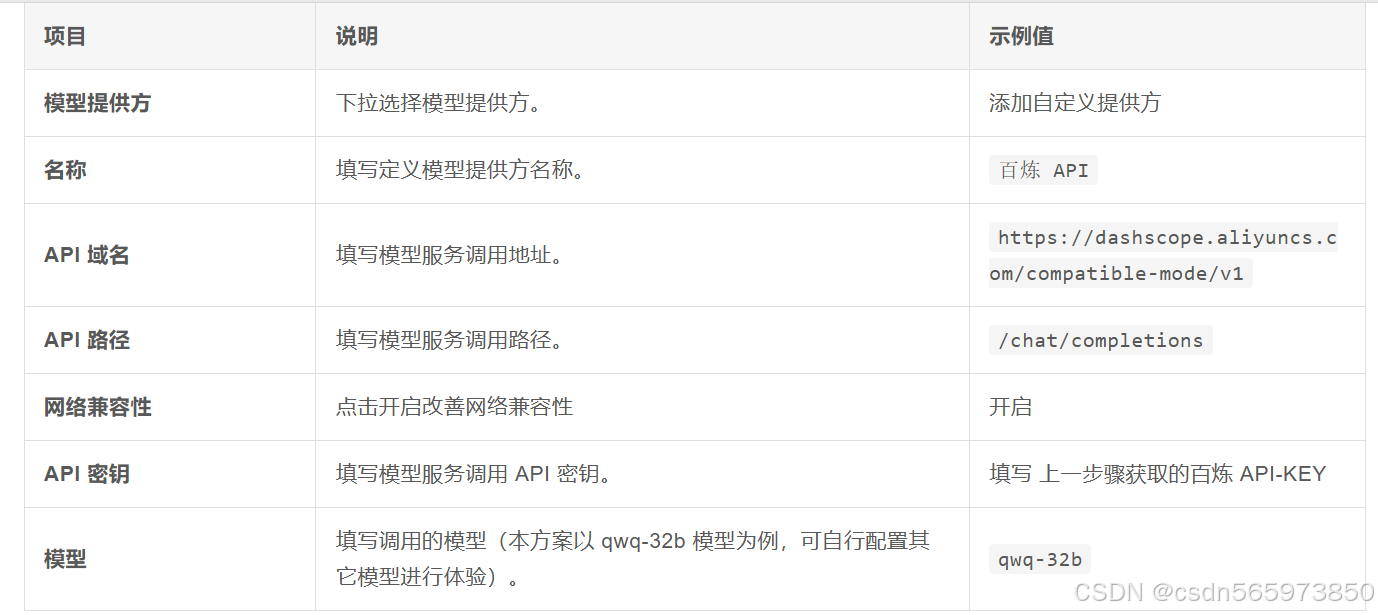
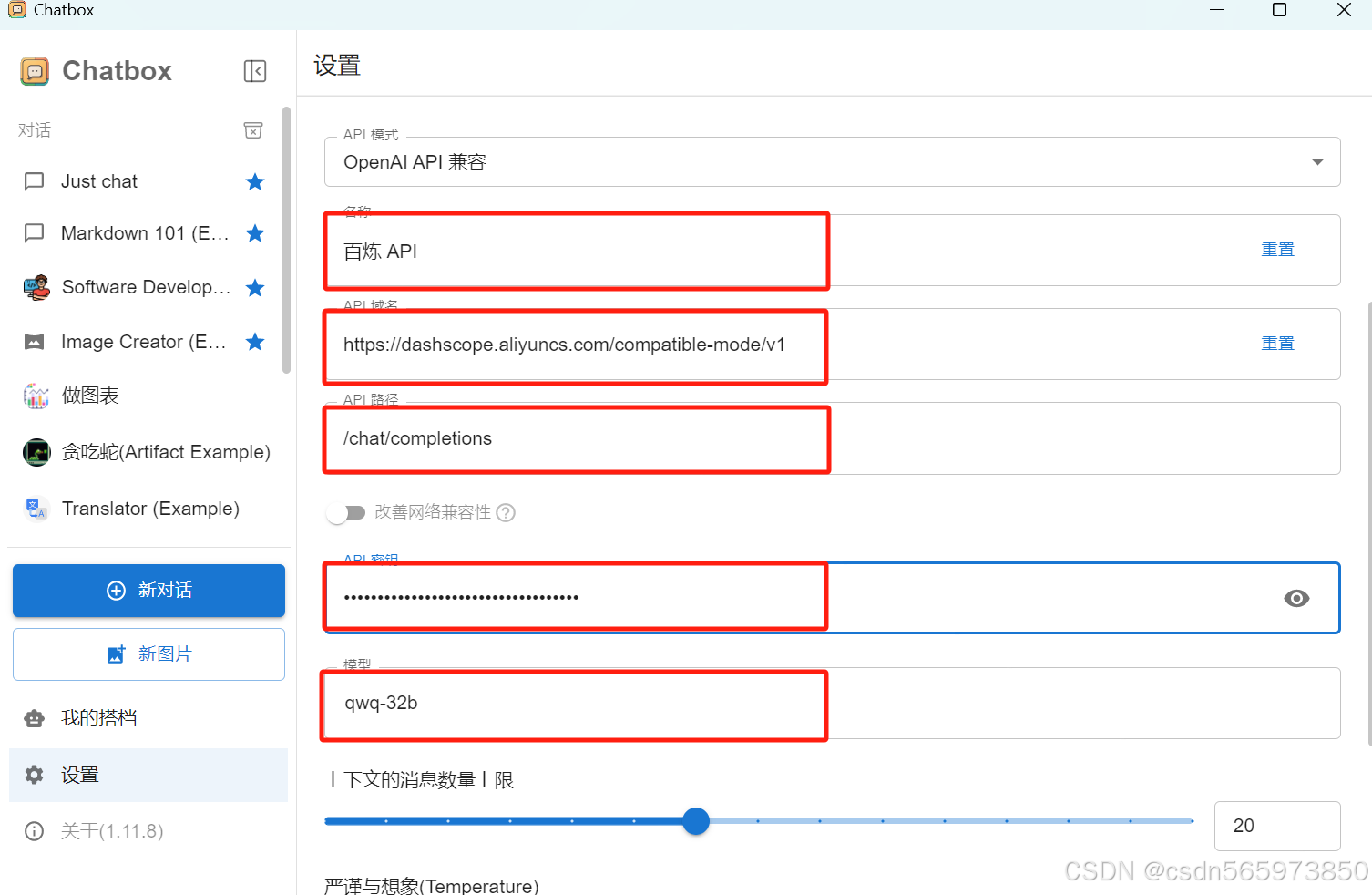
其中,【名称】、【API域名】、【API密钥】、【模型】需要手动填写,其他默认选择即可,配置完成后的效果图如图所示,点击【保存】
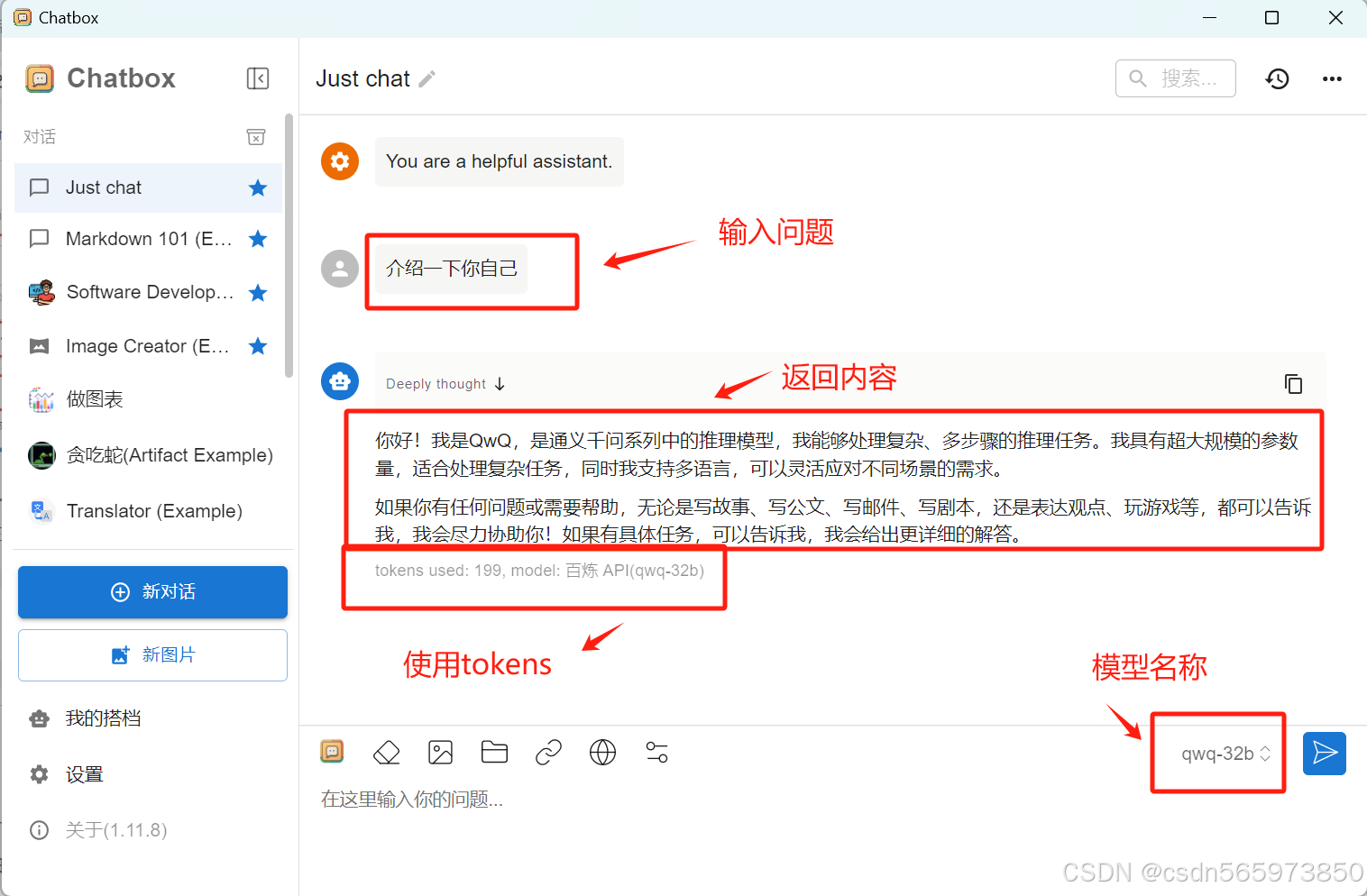
保存完成后,在Chatbox 输入问题,然后就可以在Chatbox 对话页面看到具体的返回内容以及使用tokens 模型名称等内容
回答问题
那么既然到这里了,我们就可以让 QwQ-32B 来尝试回答一下我们话题的问题,输入问题【QwQ-32B 在技术实现上有哪些值得关注的亮点】之后,可以看到我们关注的问题
以下是关于 QwQ-32B有哪些值得关注的技术亮点 的恢复
QwQ-32B 在技术实现上融合了多项前沿技术,其核心亮点主要体现在以下几个方面:
1. 超大规模参数与高效训练优化
超大规模参数量:QwQ-32B 拥有 320 亿参数量,属于超大规模模型,能够捕捉复杂的语言模式和多步骤推理能力。
混合并行训练:通过 Tensor Parallelism + Pipeline Parallelism 结合的方式,高效利用计算资源,支持在 GPU/TPU 集群上进行分布式训练。
混合精度训练:采用 FP16 或 BF16 精度计算,结合动态损失缩放(Dynamic Loss Scaling),在保证精度的同时显著降低显存占用和计算成本。
2. 多模态与多语言处理
多语言支持:通过跨语言预训练(Cross-lingual Pretraining),支持多种语言(如中文、英文、德语、法语等),并具备跨语言迁移能力。
代码理解与生成:针对代码场景优化,支持多种编程语言(如 Python、Java、JavaScript 等),能够编写、调试和解释代码,适用于开发场景。
多模态扩展性:虽然 QwQ-32B 主要面向文本,但其架构设计兼容多模态任务(如图文理解),通过扩展视觉编码器即可实现多模态推理。
3. 复杂推理与任务适应性
深度上下文理解:通过长序列建模(支持超长上下文长度)和注意力机制优化(如局部注意力、稀疏注意力),提升对复杂任务的推理能力。
指令微调(Instruction Tuning):基于大量人工标注的指令数据集进行微调,使其能够理解并执行多样化任务(如写作、编程、逻辑推理等)。
动态计算路径:在推理时根据输入内容动态调整计算资源分配,提升对复杂任务的响应效率。
4. 安全性与伦理控制
对话安全机制:内置内容过滤和安全校验模块,通过强化学习(RLHF,Reinforcement Learning from Human Feedback)优化,确保生成内容符合伦理规范。
对抗攻击防御:针对模型可能存在的漏洞(如对抗样本攻击),通过数据增强和模型鲁棒性训练提升防御能力。
5. 轻量化与推理效率优化
模型压缩技术:通过 知识蒸馏(Knowledge Distillation) 或 模型剪枝(Pruning),可将模型压缩为更小的版本(如 Qwen-Max、Qwen-Plus 等),平衡性能与资源消耗。
高效推理引擎:基于 CUDA 内核优化 和 模型并行策略,在推理时进一步降低延迟,支持实时交互场景。
6. 灵活的部署与应用
开源生态支持:提供完整的模型工具链(如推理框架、数据处理工具),支持在云计算、边缘计算等多种场景部署。
API 与 SDK:通过阿里云等平台提供 API 接口,开发者可快速集成模型能力,支持个性化定制。
总结
QwQ-32B 的核心优势在于其 超大规模参数量、多语言与多模态兼容性、复杂推理能力,以及 高效训练与部署技术。这些技术亮点使其在自然语言处理、代码生成、逻辑推理等场景中表现出色,同时兼顾了实际应用中的资源效率和安全性需求。
技术亮点
对于大模型来说,如何在性能与资源消耗之间找到一种平衡,是技术人一直努力的点。
在性能方面,QwQ-32B 模型具有强大的推理能力,其参数量约为 DeepSeek-R1 满血版的 1/21 且推理成本是后者的1/10,在数学、代码等核心指标(AIME 24/25、LiveCodeBench)达到 DeepSeek-R1 满血版水平。
在资源消耗方面,QwQ-32B 模型,支持2-bit至8-bit量化,最小仅需13GB显存(Q4量化版本仅8GB),单张RTX 3090 Ti即可实现30+ token/s的生成速度,而同类千亿模型需数十倍资源。仅320亿参数,通过动态稀疏注意力机制和分组查询注意力(GQA)等技术优化,性能媲美6710亿参数的模型,同时降低显存需求,支持消费级GPU(如RTX 4090)、苹果M系列芯片(如M4 Max)及云端部署,提供从本地到云端的全栈适配方案。


















 1255
1255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











