




大家好,概率和统计知识是数据科学和机器学习的核心,我们需要统计和概率知识来有效地收集、审查、分析数据。
现实世界中有几个现象实例被认为是统计性质的(即天气数据、销售数据、财务数据等)。这意味着在某些情况下,我们已经能够开发出方法来帮助我们通过可以描述数据特征的数学函数来模拟自然。
了解数据的分布有助于更好地模拟周围的世界,它可以帮助我们确定各种结果的可能性,或估计事件的可变性,这使得概率分布在数据科学和机器学习中非常有价值。
1.均匀分布
最直接的分布是均匀分布。均匀分布是一种概率分布,其中所有结果的可能性均等。例如,如果掷一个公平的骰子,落在任何数字上的概率是1/6,这是一个离散的均匀分布。
但是并不是所有的均匀分布都是离散的,它们也可以是连续的,并能在指定范围内取任何实际值。a 和 b 之间连续均匀分布的概率密度函数 (PDF) 如下:
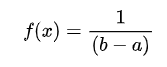
在 Python 中对它们进行编码:
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
# for continuous
a = 0
b = 50
size = 5000
X_continuous = np.linspace(a, b, size)
continuous_uniform = stats.uniform(loc=a, scale=b)
continuous_uniform_pdf = continuous_uniform.pdf(X_continuous)
# for discrete
X_discrete = np.arange(1, 7)
discrete_uniform = stats.randint(1, 7)
discrete_uniform_pmf = discrete_uniform.pmf(X_discrete)
# plot both tables
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(15,5))
# discrete plot
ax[0].bar(X_discrete, discrete_uniform_pmf)
ax[0].set_xlabel("X")
ax[0].set_ylabel("Probability")
ax[0].set_title("Discrete Uniform Distribution")
# continuous plot
ax[1].plot(X_continuous, continuous_uniform_pdf)
ax[1].set_xlabel("X")
ax[1].set_ylabel("Probability")
ax[1].set_title("Continuous Uniform Distrib 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 4735
4735

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











