




大家好,在深度学习领域,神经网络几乎能处理各种任务,但通常需要依赖于海量数据来达到最佳效果。然而,对于像面部识别和签名验证这类任务,我们不可能总是有大量的数据可用。由此产生了一种新型的神经网络架构,称为孪生网络。
孪生神经网络能够基于少量数据实现精准预测,本文将介绍孪生神经网络的基本概念,以及如何用PyTorch来搭建一个签名验证系统。
1.孪生神经网络概述
孪生神经网络由两个或若干个结构和参数完全相同的子网络构成,这些子网络在更新参数时同步进行。
这种网络通过分析输入样本的特征向量来评估它们的相似度,这一特性让其在众多应用领域中发挥着重要作用。
传统神经网络一般被训练用于识别多个不同的类别。当数据集中需要添加或移除类别时,这些网络通常需要经过调整和重新训练,这个过程不仅耗时,而且通常需要大量的数据支持。
而孪生网络专注于学习样本之间的相似性,能够轻松识别图像是否相似。这种能力使孪生网络在处理新类别数据时,无需重新训练即可进行有效的分类,提供了一种灵活且高效的解决方案。
1.1 优劣势
优势:
-
对类别失衡的适应能力更强:通过一次性学习,孪生网络仅需少量样本即可有效识别图像类别,具有良好的鲁棒性和适应性。
-
与顶级分类器的协同效应:由于其独特的学习机制,与传统分类方法相比,孪生网络与最佳分类器(如GBM和随机森林)的结合能够带来更佳的性能表现。
-
学习语义相似性:孪生网络专注于深层特征的嵌入学习,将相同类别或概念的样本聚集在一起,从而能够捕捉和学习它们之间的语义相似性。
劣势:
-
训练耗时较长:孪生网络采用成对学习机制,需要综合考虑所有可用信息,因此其训练过程比逐点学习的分类网络更为耗时。
-
缺乏概率输出:孪生网络的训练过程专注于成对比较,它不提供预测结果的概率值,而是直接输出各类别之间的相对距离。
1.2 孪生网络中使用的损失函数
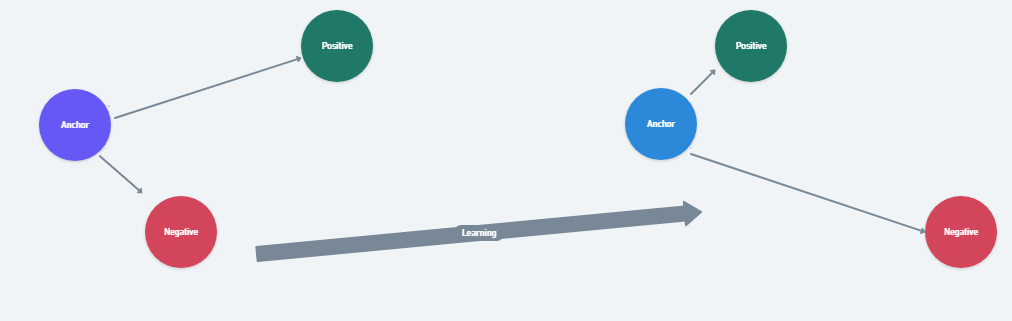
在孪生网络的训练过程中,由于采用的是成对学习方式,传统的交叉熵损失函数不再适用。目前,主要有两种损失函数用于训练这类网络:
1)三元组损失
三元组是一种特殊的损失函数,它通过比较基线(锚点)输入与正样本(真实输入)和负样本(虚假输入)之间的差异来工作。其目标是最小化锚点与正样本之间的距离,同时最大化锚点与负样本之间的距离,从而确保网络能够准确区分不同类别的样本。
![]()
在上述方程中,α是控制间隔的参数,用于调整相似样本对与不相似样本对之间的距离差异;f(A)、f(P)、f(N)分别代表锚点、正样本和负样本的特征嵌入。
训练时,将由锚点图像、负样本图像和正样本图像组成的三元组作为单一样本输入到模型中。这样做的目的是确保锚点与正样本图像之间的距离小于锚点与负样本图像之间的距离。
2)对比损失
对比损失是当前非常流行的损失函数,它基于距离而非传统的错误预测来计算损失。该损失函数主要应用于特征嵌入的学习,目标是优化样本点在欧几里得空间(Euclidean space)的分布:对于相似的样本点,我们希望它们之间的距离尽可能地小,以便能够准确捕捉它们之间的相似性;对于不相似的样本点,则希望它们之间的距离足够大,以便于区分差异。
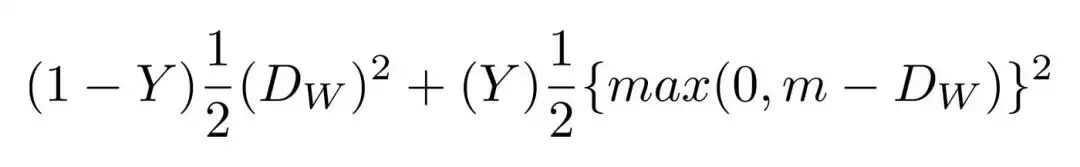
定义Dw是欧几里得距离(Euclidean distance):
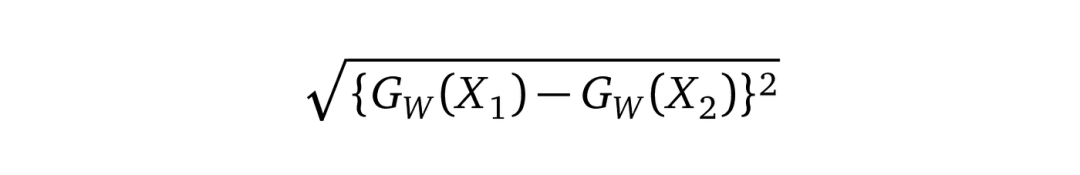
Gw是网络对一张图像的输出结果。
2.孪生网络在签名验证领域的应用
孪生网络具有优秀的相似性比较能力,常被应用于需要验证身份的系统中,例如面部识别和签名验证。
接下来,将在PyTorch框架下构建一个基于孪生神经网络的签名验证系统,实现高精度的身份验证功能。

2.1 数据集和数据集预处理
使用ICDAR 2011数据集进行签名验证,该数据集收录了荷兰用户的签名样本,包括真实和伪造的签名。数据集分为训练和测试部分,每个部分都有用户的真实与伪造签名文件夹。数据集的标签信息以CSV文件的形式提供。

ICDAR 数据集中的签名
在把这些原始数据输入神经网络之前,需要将图像转换为张量,并整合CSV中的标签。这可以通过PyTorch的自定义数据集类实现,以下是代码示例。
#数据预处理和加载
class SiameseDataset():
def __init__(self,training_csv=None,training_dir=None,transform=None):
# used to prepare the labels and images path
self.train_df=pd.read_csv(training_csv)
self.train_df.columns =["image1","image2","label"]
self.train_dir = training_dir
self.transform 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 6029
6029

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











