



摘要
在现代软件开发中,Git作为最流行的分布式版本控制系统,已成为团队协作开发的核心工具。特别是在AI应用开发领域,多人协作、频繁迭代和复杂代码管理使得Git的冲突解决能力显得尤为重要。本文将深入探讨如何使用Git解决代码冲突并高效管理代码更改,涵盖Git基础操作、冲突类型识别、解决步骤详解以及实际开发中的最佳实践。通过丰富的实践案例和图表展示,帮助中国开发者特别是AI应用开发者快速掌握Git的高级用法,提高团队协作效率和代码管理质量。
正文
第一章:Git基础与核心概念
1.1 Git简介
Git是由Linux之父Linus Torvalds开发的分布式版本控制系统,自2005年发布以来,已成为软件开发领域事实上的标准。Git具有以下核心特点:
- 分布式架构:每个开发者都拥有完整的代码仓库副本
- 高效性:快速的分支和合并操作
- 数据完整性:使用SHA-1哈希确保数据完整性和一致性
- 非线性开发:支持复杂的分支和合并工作流
1.2 核心概念解析
在深入学习Git冲突解决之前,我们需要理解几个核心概念:
1.3 基本操作详解
掌握Git的基本操作是解决冲突的前提。以下是常用的Git命令及其用途:
# 初始化本地仓库
git init
# 克隆远程仓库
git clone https://github.com/username/repository.git
# 查看仓库状态
git status
# 添加文件到暂存区
git add filename.txt
git add . # 添加所有更改
# 提交更改到本地仓库
git commit -m "提交信息"
# 查看提交历史
git log
git log --oneline # 简洁显示
# 查看差异
git diff # 工作区与暂存区的差异
git diff --cached # 暂存区与版本库的差异
1.4 分支管理基础
分支是Git的核心特性之一,合理的分支管理策略能够有效减少冲突:
# 查看所有分支
git branch -a
# 创建新分支
git branch feature/new-function
# 切换分支
git checkout feature/new-function
# 创建并切换到新分支
git checkout -b feature/new-function
# 合并分支
git checkout main
git merge feature/new-function
# 删除分支
git branch -d feature/new-function
第二章:Git冲突类型详解
2.1 冲突产生的根本原因
Git冲突本质上是由于多个开发者对同一文件的相同部分进行了不同的修改,Git无法自动判断应该保留哪种修改而产生的。具体原因包括:
- 并行开发:多个开发者同时修改同一文件的相同部分
- 分支合并:不同分支上的相同文件被修改后尝试合并
- 远程同步:本地修改与远程仓库的更新存在冲突
2.2 常见冲突类型
2.2.1 文件内容冲突
这是最常见的冲突类型,发生在多个开发者修改了同一文件的相同行:
# 冲突前的代码 (common.py)
def calculate_score(user_input):
"""
计算用户输入的得分
"""
# 原始实现
score = len(user_input) * 2
return score
# 开发者A的修改
def calculate_score(user_input):
"""
计算用户输入的得分
增加了权重计算
"""
# 开发者A的实现
base_score = len(user_input) * 2
weight = 1.5 if len(user_input) > 10 else 1.0
score = base_score * weight
return score
# 开发者B的修改
def calculate_score(user_input):
"""
计算用户输入的得分
增加了字符类型判断
"""
# 开发者B的实现
score = len(user_input) * 2
# 根据字符类型调整得分
if any(c.isdigit() for c in user_input):
score += 10
return score
当两个修改合并时就会产生冲突。
2.2.2 文件路径冲突
这类冲突涉及文件的重命名、删除或移动操作:
# 开发者A重命名文件
git mv old_module.py new_module.py
# 开发者B修改了原文件
# old_module.py 被修改
# 合并时会产生路径冲突
2.2.3 分支冲突
不同分支上的更改在合并时可能产生冲突:
第三章:冲突解决详细步骤
3.1 识别冲突
当Git无法自动合并更改时,会标记文件为冲突状态:
# 尝试合并分支时出现冲突
git merge feature/ai-model-update
# 输出:
# Auto-merging src/ai_model.py
# CONFLICT (content): Merge conflict in src/ai_model.py
# Automatic merge failed; fix conflicts and then commit the result.
查看冲突状态:
git status
# 输出:
# On branch main
# You have unmerged paths.
# (fix conflicts and run "git commit")
# (use "git merge --abort" to abort the merge)
#
# Unmerged paths:
# (use "git add/rm <file>..." as appropriate to mark resolution)
#
# both modified: src/ai_model.py
3.2 冲突标记解析
Git会在冲突文件中插入特殊标记来标识冲突区域:
# src/ai_model.py 中的冲突标记示例
<<<<<<< HEAD
def process_data(data):
"""
处理输入数据 - 来自main分支的版本
"""
# 数据清洗
cleaned_data = [x for x in data if x is not None]
# 特征提取
features = extract_features(cleaned_data)
return features
=======
def process_data(data):
"""
处理输入数据 - 来自feature分支的版本
"""
# 数据验证
if not data:
raise ValueError("输入数据不能为空")
# 数据标准化
normalized_data = normalize_data(data)
# 特征工程
features = engineer_features(normalized_data)
return features
>>>>>>> feature/ai-model-update
标记说明:
<<<<<<< HEAD:当前分支(通常是目标分支)的更改=======:分隔符,区分两个版本的更改>>>>>>> feature/ai-model-update:合并分支的更改
3.3 手动解决冲突
解决冲突需要根据业务需求选择合适的解决方案:
# 解决后的代码
def process_data(data):
"""
处理输入数据 - 合并后的版本
"""
# 数据验证
if not data:
raise ValueError("输入数据不能为空")
# 数据清洗
cleaned_data = [x for x in data if x is not None]
# 数据标准化
normalized_data = normalize_data(cleaned_data)
# 特征工程
features = engineer_features(normalized_data)
return features
3.4 使用工具辅助解决冲突
Git提供了多种工具来辅助解决冲突:
# 使用默认的合并工具
git mergetool
# 指定特定的合并工具
git mergetool --tool=vimdiff
git mergetool --tool=vscode
# 手动编辑冲突文件后标记解决
git add src/ai_model.py
# 完成合并提交
git commit
第四章:AI应用开发中的实践案例
4.1 案例一:机器学习模型参数调优冲突
在AI项目中,多个数据科学家可能同时调整模型参数,导致冲突:
# model_config.py - 冲突前版本
MODEL_CONFIG = {
'learning_rate': 0.001,
'batch_size': 32,
'epochs': 100,
'optimizer': 'adam'
}
# 数据科学家A的修改 - 提高学习率以加快收敛
<<<<<<< HEAD
MODEL_CONFIG = {
'learning_rate': 0.01, # 调整学习率
'batch_size': 32,
'epochs': 100,
'optimizer': 'adam'
}
=======
# 数据科学家B的修改 - 增加批次大小以提高训练效率
MODEL_CONFIG = {
'learning_rate': 0.001,
'batch_size': 64, # 增加批次大小
'epochs': 100,
'optimizer': 'adam'
}
>>>>>>> feature/batch-size-optimization
解决冲突的方案:
# model_config.py - 解决冲突后的版本
MODEL_CONFIG = {
'learning_rate': 0.01, # 采用A的调整,加快收敛速度
'batch_size': 64, # 采用B的调整,提高训练效率
'epochs': 100,
'optimizer': 'adam'
}
对应的AI模型训练代码:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
AI模型训练脚本
包含冲突解决后的参数配置使用
"""
import os
import json
import logging
from typing import Dict, Any, List
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, classification_report
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
# 加载模型配置
try:
from model_config import MODEL_CONFIG
logger.info("模型配置加载成功")
except ImportError:
MODEL_CONFIG = {
'learning_rate': 0.001,
'batch_size': 32,
'epochs': 100,
'optimizer': 'adam'
}
logger.warning("使用默认模型配置")
class AIModelTrainer:
"""AI模型训练器"""
def __init__(self, config: Dict[str, Any] = None):
"""
初始化模型训练器
Args:
config: 模型配置参数
"""
self.config = config or MODEL_CONFIG
self.model = None
self.is_trained = False
logger.info(f"AI模型训练器初始化完成,配置: {self.config}")
def load_data(self, data_path: str) -> tuple:
"""
加载训练数据
Args:
data_path: 数据文件路径
Returns:
训练数据和标签
"""
try:
# 模拟数据加载
logger.info(f"正在加载数据: {data_path}")
# 生成模拟数据(实际项目中应从文件加载)
np.random.seed(42)
X = np.random.rand(1000, 10) # 1000个样本,10个特征
y = np.random.randint(0, 2, 1000) # 二分类标签
logger.info(f"数据加载完成,样本数: {len(X)}, 特征数: {X.shape[1]}")
return X, y
except Exception as e:
logger.error(f"数据加载失败: {e}")
raise
def preprocess_data(self, X: np.ndarray, y: np.ndarray) -> tuple:
"""
数据预处理
Args:
X: 特征数据
y: 标签数据
Returns:
预处理后的数据
"""
try:
logger.info("开始数据预处理")
# 数据分割
X_train, X_test, y_train, y_test = train_test_split(
X, y,
test_size=0.2,
random_state=42,
stratify=y # 保持类别分布
)
logger.info(f"数据预处理完成,训练集: {X_train.shape}, 测试集: {X_test.shape}")
return X_train, X_test, y_train, y_test
except Exception as e:
logger.error(f"数据预处理失败: {e}")
raise
def train_model(self, X_train: np.ndarray, y_train: np.ndarray) -> None:
"""
训练模型
Args:
X_train: 训练特征数据
y_train: 训练标签数据
"""
try:
logger.info("开始模型训练")
# 创建模型实例
self.model = RandomForestClassifier(
n_estimators=100,
random_state=42,
n_jobs=-1 # 使用所有CPU核心
)
# 训练模型
self.model.fit(X_train, y_train)
self.is_trained = True
logger.info("模型训练完成")
except Exception as e:
logger.error(f"模型训练失败: {e}")
raise
def evaluate_model(self, X_test: np.ndarray, y_test: np.ndarray) -> Dict[str, Any]:
"""
评估模型性能
Args:
X_test: 测试特征数据
y_test: 测试标签数据
Returns:
评估结果
"""
try:
if not self.is_trained or self.model is None:
raise ValueError("模型尚未训练")
logger.info("开始模型评估")
# 预测
y_pred = self.model.predict(X_test)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
# 生成分类报告
report = classification_report(y_test, y_pred, output_dict=True)
# 组织评估结果
evaluation_result = {
'accuracy': accuracy,
'classification_report': report,
'samples_count': len(y_test)
}
logger.info(f"模型评估完成,准确率: {accuracy:.4f}")
return evaluation_result
except Exception as e:
logger.error(f"模型评估失败: {e}")
raise
def save_model(self, model_path: str) -> None:
"""
保存模型
Args:
model_path: 模型保存路径
"""
try:
if not self.is_trained or self.model is None:
raise ValueError("模型尚未训练")
# 这里简化处理,实际项目中可能需要使用joblib或pickle
model_info = {
'config': self.config,
'is_trained': self.is_trained,
'feature_importance': self.model.feature_importances_.tolist()
}
with open(model_path, 'w', encoding='utf-8') as f:
json.dump(model_info, f, ensure_ascii=False, indent=2)
logger.info(f"模型信息已保存到: {model_path}")
except Exception as e:
logger.error(f"模型保存失败: {e}")
raise
def main():
"""主函数"""
try:
# 创建训练器实例
trainer = AIModelTrainer()
# 加载数据
X, y = trainer.load_data("data/training_data.csv")
# 数据预处理
X_train, X_test, y_train, y_test = trainer.preprocess_data(X, y)
# 训练模型
trainer.train_model(X_train, y_train)
# 评估模型
evaluation_result = trainer.evaluate_model(X_test, y_test)
print(f"模型准确率: {evaluation_result['accuracy']:.4f}")
# 保存模型
trainer.save_model("models/ai_model.json")
logger.info("AI模型训练流程完成")
except Exception as e:
logger.error(f"AI模型训练流程失败: {e}")
raise
if __name__ == "__main__":
main()
4.2 案例二:Docker Compose配置文件冲突
在AI应用部署中,团队成员可能同时修改Docker Compose配置文件:
# docker-compose.yml - 冲突前版本
version: '3.8'
services:
api:
image: ai-app:latest
ports:
- "5000:5000"
environment:
- DB_HOST=db
- DB_PORT=5432
# 开发者A的修改 - 增加GPU支持
<<<<<<< HEAD
version: '3.8'
services:
api:
image: ai-app:latest
ports:
- "5000:5000"
environment:
- DB_HOST=db
- DB_PORT=5432
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
=======
# 开发者B的修改 - 增加环境变量
version: '3.8'
services:
api:
image: ai-app:latest
ports:
- "5000:5000"
environment:
- DB_HOST=db
- DB_PORT=5432
- REDIS_HOST=redis
- REDIS_PORT=6379
>>>>>>> feature/redis-integration
解决冲突后的完整配置:
# docker-compose.yml - 解决冲突后的版本
version: '3.8'
networks:
ai_network:
driver: bridge
volumes:
postgres_data:
redis_data:
services:
# 数据库服务
db:
image: postgres:13-alpine
environment:
POSTGRES_DB: ai_app
POSTGRES_USER: ai_user
POSTGRES_PASSWORD: ai_password
volumes:
- postgres_data:/var/lib/postgresql/data
networks:
- ai_network
healthcheck:
test: ["CMD-SHELL", "pg_isready -U ai_user"]
interval: 10s
timeout: 5s
retries: 5
# 缓存服务
redis:
image: redis:6-alpine
volumes:
- redis_data:/data
networks:
- ai_network
command: redis-server --appendonly yes
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 10s
timeout: 5s
retries: 5
# API服务
api:
image: ai-app:latest
ports:
- "5000:5000"
environment:
- DB_HOST=db
- DB_PORT=5432
- REDIS_HOST=redis
- REDIS_PORT=6379
depends_on:
db:
condition: service_healthy
redis:
condition: service_healthy
networks:
- ai_network
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:5000/health"]
interval: 30s
timeout: 10s
retries: 3
# Web前端服务
web:
image: ai-web:latest
ports:
- "3000:3000"
environment:
- API_URL=http://api:5000
depends_on:
- api
networks:
- ai_network
volumes:
postgres_data:
redis_data:
第五章:Git工作流与冲突预防
5.1 分支策略选择
选择合适的分支策略能够有效减少冲突:
5.2 冲突预防最佳实践
# 1. 定期同步主分支更改
git checkout main
git pull origin main
git checkout feature/your-feature
git rebase main # 或者使用 git merge main
# 2. 频繁提交小的更改
git add .
git commit -m "实现用户认证功能的第一部分"
# 3. 使用有意义的提交信息
git commit -m "feat: 添加用户登录验证功能"
# 4. 在推送前检查冲突
git fetch origin
git diff origin/main
# 5. 使用.gitignore避免不必要的冲突
echo "*.log" >> .gitignore
echo "__pycache__/" >> .gitignore
echo "*.pyc" >> .gitignore
5.3 代码审查流程
建立代码审查机制能够提前发现潜在冲突:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
代码审查辅助工具
帮助识别潜在的冲突和问题
"""
import subprocess
import json
import re
from typing import List, Dict, Any
import logging
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class CodeReviewHelper:
"""代码审查辅助工具"""
def __init__(self):
"""初始化审查工具"""
self.conflict_patterns = [
r'<<<<<<< HEAD',
r'=======',
r'>>>>>>>',
r'<<<<<<<.*\n.*=======\n.*>>>>>>>' # 多行冲突标记
]
self.problem_patterns = {
'hardcoded_secrets': r'[\'"](sk-[a-zA-Z0-9]{48})[\'"]',
'print_statements': r'\bprint\s*\(',
'todo_comments': r'#\s*(TODO|FIXME|HACK)',
'large_functions': r'def\s+\w+\s*\([^)]*\):\s*\n(?:\s+.*\n){50,}' # 超过50行的函数
}
def check_for_conflicts(self, file_path: str = None) -> List[str]:
"""
检查文件中的冲突标记
Args:
file_path: 文件路径,如果为None则检查所有文件
Returns:
包含冲突标记的文件列表
"""
try:
if file_path:
# 检查特定文件
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
conflicts = []
for pattern in self.conflict_patterns:
if re.search(pattern, content):
conflicts.append(file_path)
break
return conflicts
else:
# 检查所有文件
result = subprocess.run(
['git', 'diff', '--check'],
capture_output=True,
text=True
)
if result.returncode == 0:
return []
else:
# 解析冲突文件
conflicts = []
for line in result.stdout.split('\n'):
if '<<<<<<<' in line or '=======' in line or '>>>>>>>' in line:
# 提取文件名
match = re.search(r'^(.*?):', line)
if match:
conflicts.append(match.group(1))
return list(set(conflicts))
except Exception as e:
logger.error(f"检查冲突时出错: {e}")
return []
def check_for_problems(self, file_path: str = None) -> Dict[str, List[str]]:
"""
检查代码中的潜在问题
Args:
file_path: 文件路径,如果为None则检查所有文件
Returns:
问题列表字典
"""
try:
files_to_check = []
if file_path:
files_to_check = [file_path]
else:
# 获取所有Python文件
result = subprocess.run(
['git', 'ls-files', '*.py'],
capture_output=True,
text=True
)
files_to_check = result.stdout.strip().split('\n')
problems = {key: [] for key in self.problem_patterns.keys()}
for file_path in files_to_check:
if not file_path:
continue
try:
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
for problem_type, pattern in self.problem_patterns.items():
matches = re.findall(pattern, content, re.MULTILINE)
if matches:
problems[problem_type].append({
'file': file_path,
'matches': matches
})
except Exception as e:
logger.warning(f"检查文件 {file_path} 时出错: {e}")
return problems
except Exception as e:
logger.error(f"检查问题时出错: {e}")
return {}
def generate_review_report(self) -> Dict[str, Any]:
"""
生成代码审查报告
Returns:
审查报告
"""
logger.info("开始生成代码审查报告")
# 检查冲突
conflicts = self.check_for_conflicts()
# 检查问题
problems = self.check_for_problems()
# 统计信息
total_problems = sum(len(files) for files in problems.values())
report = {
'conflicts': conflicts,
'problems': problems,
'summary': {
'conflict_files': len(conflicts),
'total_problems': total_problems,
'problem_types': {
problem_type: len(files)
for problem_type, files in problems.items()
}
}
}
logger.info("代码审查报告生成完成")
return report
def main():
"""主函数"""
try:
# 创建审查工具实例
reviewer = CodeReviewHelper()
# 生成审查报告
report = reviewer.generate_review_report()
# 输出报告
print("代码审查报告")
print("=" * 50)
print(f"冲突文件数: {report['summary']['conflict_files']}")
print(f"问题总数: {report['summary']['total_problems']}")
if report['conflicts']:
print("\n冲突文件:")
for conflict_file in report['conflicts']:
print(f" - {conflict_file}")
print("\n问题详情:")
for problem_type, files in report['problems'].items():
if files:
print(f" {problem_type}:")
for file_info in files:
print(f" - {file_info['file']}: {len(file_info['matches'])} 处")
# 如果有严重问题,返回非零退出码
if report['summary']['conflict_files'] > 0 or report['summary']['total_problems'] > 0:
print("\n⚠️ 发现问题,请在提交前解决")
return 1
else:
print("\n✅ 代码审查通过")
return 0
except Exception as e:
logger.error(f"代码审查失败: {e}")
return 1
if __name__ == "__main__":
exit(main())
第六章:高级冲突解决技巧
6.1 使用Git rerere功能
Git的rerere(reuse recorded resolution)功能可以自动重用之前的冲突解决方案:
# 启用rerere功能
git config --global rerere.enabled true
# 查看rerere缓存
ls .git/rr-cache/
# 清除rerere缓存
git rerere clear
6.2 三方合并策略
在复杂冲突情况下,可以使用不同的合并策略:
# 使用ours策略(保留当前分支的更改)
git merge -s ours feature/other-feature
# 使用theirs策略(保留合并分支的更改)
git merge -s recursive -X theirs feature/other-feature
# 使用ignore-space-change忽略空白字符差异
git merge -X ignore-space-change feature/other-feature
6.3 冲突解决工具推荐
# 配置合并工具
git config --global merge.tool vscode
git config --global mergetool.vscode.cmd 'code --wait $MERGED'
# 或者使用其他工具
git config --global merge.tool meld
git config --global merge.tool vimdiff
第七章:团队协作最佳实践
7.1 Git工作流规范
# 团队Git工作流规范
## 分支命名规范
- feature/*: 功能开发分支
- bugfix/*: 缺陷修复分支
- hotfix/*: 紧急修复分支
- release/*: 发布准备分支
## 提交信息规范
- feat: 新功能 (feature)
- fix: 修复缺陷 (bug fix)
- docs: 文档更新 (documentation)
- style: 代码格式调整 (white-space, formatting, etc)
- refactor: 代码重构 (refactoring)
- test: 测试相关 (when adding missing tests)
- chore: 构建过程或辅助工具的变动 (maintain)
## 示例
- feat: 添加用户登录功能
- fix: 修复数据处理中的空值异常
- docs: 更新API文档
7.2 代码审查检查清单
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
代码审查检查清单工具
帮助团队进行标准化的代码审查
"""
import json
from typing import Dict, List
from datetime import datetime
class CodeReviewChecklist:
"""代码审查检查清单"""
def __init__(self):
"""初始化检查清单"""
self.checklist = {
"功能实现": [
"代码逻辑是否正确实现需求",
"边界条件是否处理完整",
"异常情况是否有适当处理",
"性能是否满足要求"
],
"代码质量": [
"代码是否符合PEP8规范",
"变量命名是否清晰有意义",
"函数是否职责单一",
"是否有重复代码需要重构"
],
"测试覆盖": [
"是否添加了单元测试",
"测试用例是否覆盖主要场景",
"测试数据是否合理",
"测试结果是否通过"
],
"安全性": [
"是否有硬编码的敏感信息",
"输入验证是否充分",
"是否有潜在的安全漏洞",
"权限控制是否正确"
],
"文档说明": [
"函数和类是否有适当注释",
"复杂逻辑是否有说明",
"README是否需要更新",
"API文档是否同步更新"
]
}
def generate_checklist_template(self) -> Dict[str, List[Dict[str, bool]]]:
"""
生成检查清单模板
Returns:
检查清单模板
"""
template = {}
for category, items in self.checklist.items():
template[category] = [
{
"item": item,
"checked": False,
"comment": ""
}
for item in items
]
return template
def save_review_record(self,
pr_number: str,
reviewer: str,
checklist_result: Dict,
comments: str = "") -> None:
"""
保存审查记录
Args:
pr_number: PR编号
reviewer: 审查者
checklist_result: 检查清单结果
comments: 审查评论
"""
record = {
"pr_number": pr_number,
"reviewer": reviewer,
"timestamp": datetime.now().isoformat(),
"checklist": checklist_result,
"comments": comments
}
# 在实际应用中,这里可以保存到数据库或文件
filename = f"review_records/pr_{pr_number}_review_{reviewer}.json"
with open(filename, 'w', encoding='utf-8') as f:
json.dump(record, f, ensure_ascii=False, indent=2)
print(f"审查记录已保存到: {filename}")
def main():
"""主函数示例"""
# 创建检查清单实例
checklist = CodeReviewChecklist()
# 生成检查清单模板
template = checklist.generate_checklist_template()
# 打印检查清单
print("代码审查检查清单")
print("=" * 50)
for category, items in template.items():
print(f"\n{category}:")
for i, item in enumerate(items, 1):
print(f" {i}. [ ] {item['item']}")
# 示例:保存审查记录
sample_result = template.copy()
# 在实际使用中,这里会被用户填写的审查结果替换
checklist.save_review_record(
pr_number="PR-123",
reviewer="张三",
checklist_result=sample_result,
comments="代码整体质量良好,建议添加更多边界测试用例"
)
if __name__ == "__main__":
main()
第八章:常见问题与解决方案
8.1 如何避免冲突
# 1. 定期同步远程更改
git fetch origin
git rebase origin/main
# 2. 频繁提交小的更改
git add .
git commit -m "完成用户认证模块的第一部分"
# 3. 使用功能分支
git checkout -b feature/user-authentication
# 4. 在推送前检查潜在冲突
git fetch origin
git diff origin/main
8.2 如何恢复暂存的更改
# 1. 暂存当前更改
git stash
# 2. 切换分支处理其他任务
git checkout main
git pull origin main
# 3. 切回原分支并恢复更改
git checkout feature/your-feature
git stash pop
# 4. 查看暂存列表
git stash list
# 5. 应用特定的暂存
git stash apply stash@{1}
8.3 如何撤销错误的合并
# 1. 查看合并提交
git log --oneline -10
# 2. 如果刚合并,可以使用--abort
git merge --abort
# 3. 如果已经提交,可以回退到合并前的状态
git reset --hard HEAD~1
# 4. 或者使用reflog找到合并前的状态
git reflog
git reset --hard HEAD@{2}
第九章:项目实施计划
第十章:冲突类型分布分析
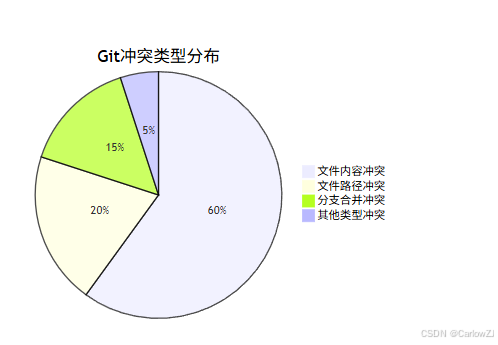
总结
通过本文的深入学习和实践,我们全面掌握了Git冲突解决与代码管理的核心技能。以下是对关键要点的回顾和总结:
核心要点回顾
-
Git基础理解:深入理解了Git的工作区、暂存区和版本库的概念,以及分支管理的核心机制
-
冲突类型识别:能够准确识别文件内容冲突、文件路径冲突和分支合并冲突等常见冲突类型
-
解决步骤掌握:熟练掌握了从冲突识别、手动解决到提交完成的完整解决流程
-
工具运用能力:学会了使用各种Git工具和命令来辅助冲突解决和代码管理
-
实践案例应用:通过AI应用开发和Docker配置等实际案例,提升了在真实项目中解决冲突的能力
-
预防机制建立:掌握了通过合理的工作流和团队协作来预防冲突的最佳实践
实践建议
-
建立规范流程:团队应建立标准化的Git工作流和代码审查机制
-
定期培训提升:定期组织Git技能培训,提升团队整体水平
-
工具辅助支持:合理使用Git工具和IDE插件提高工作效率
-
文档持续更新:维护团队的Git使用规范文档,确保知识传承
-
经验总结分享:定期总结冲突解决经验,形成团队知识库
未来展望
随着AI技术的快速发展和团队协作模式的不断演进,Git冲突解决和代码管理也将面临新的挑战:
-
大规模协作:随着团队规模扩大,需要更精细化的分支管理策略
-
自动化集成:CI/CD流程的深入集成将要求更智能的冲突检测和解决机制
-
AI辅助工具:未来可能出现基于AI的智能冲突解决辅助工具
-
云端协作:云端开发环境的普及将带来新的协作模式和挑战
通过持续学习和实践,我们能够更好地应对这些挑战,提升团队的协作效率和代码质量。
参考资料
扩展阅读
- 《Pro Git》 - Scott Chacon和Ben Straub著,最权威的Git学习资料
- 《Git团队协作》 - Emma Jane Hogbin Westby著,专注于团队协作场景
- 《GitHub实践》 - Chris Dawson著,GitHub平台使用指南
- 《重构:改善既有代码的设计》 - Martin Fowler著,代码质量提升经典著作
- 《持续交付》 - Jez Humble和David Farley著,现代软件交付实践指南
希望本文能够帮助中国开发者特别是AI应用开发者更好地掌握Git冲突解决技能,提升团队协作效率和代码管理质量。在实际项目中,建议结合团队具体情况,灵活运用文中介绍的方法和技巧。




















 852
852

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











