



摘要
在当今快速发展的AI技术领域,构建和部署复杂的AI应用系统已成为开发者面临的重要挑战。一个典型的AI应用系统通常包含数据库、缓存、向量数据库、API服务、Web前端等多个组件,这些组件需要协同工作才能提供完整的功能。本文将详细介绍如何使用Docker Compose部署一个完整的AI应用系统,涵盖PostgreSQL数据库、Redis缓存、Weaviate向量数据库、Nginx代理、插件守护进程等关键组件。通过实际案例,我们将展示如何解决插件加载失败、环境配置错误等常见问题,并提供详细的实践步骤和代码示例。目标读者为中国开发者,特别是AI应用开发者,帮助他们快速掌握复杂AI系统的部署技能。
正文
第一章:系统架构概述
在AI应用开发中,系统架构设计是成功部署的基础。一个典型的AI应用系统需要多个服务协同工作,包括数据存储、缓存管理、向量检索、API服务、前端界面等。合理设计系统架构能够确保各组件之间的高效通信和稳定运行。
1.1 AI应用系统架构
1.2 各组件功能说明
- Nginx反向代理:处理HTTP请求路由、负载均衡、SSL终止等
- API服务:核心业务逻辑处理,提供RESTful API接口
- Web前端:用户界面,提供图形化操作界面
- PostgreSQL数据库:存储结构化数据,如用户信息、配置等
- Redis缓存:提供高速缓存,存储会话数据和临时信息
- Weaviate向量数据库:存储和检索向量数据,支持语义搜索
- 插件守护进程:管理外部插件的加载和执行
- 沙箱环境:提供安全的代码执行环境
- SSRF代理:防止服务器端请求伪造攻击
- Worker服务:处理异步任务和后台作业
- Worker Beat:处理定时任务和周期性作业
第二章:环境准备与工具安装
在开始部署之前,我们需要准备好相应的开发和运行环境。
2.1 系统要求
确保您的系统满足以下要求:
- 操作系统:Linux (Ubuntu/CentOS)、macOS 或 Windows (WSL2)
- 硬件配置:至少4核CPU、8GB内存、20GB可用磁盘空间
- 网络连接:稳定的互联网连接,用于下载Docker镜像
2.2 工具安装
# Ubuntu/Debian系统安装Docker和Docker Compose
sudo apt-get update
sudo apt-get install -y docker.io docker-compose
# CentOS/RHEL系统安装Docker和Docker Compose
sudo yum install -y docker
sudo curl -L "https://github.com/docker/compose/releases/download/v2.20.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
sudo chmod +x /usr/local/bin/docker-compose
# 启动Docker服务
sudo systemctl start docker
sudo systemctl enable docker
# 验证安装
docker --version
docker-compose --version
2.3 用户权限配置
# 将当前用户添加到docker组,避免使用sudo
sudo usermod -aG docker $USER
# 重新登录或执行以下命令使权限生效
newgrp docker
# 验证权限
docker run hello-world
第三章:Docker Compose部署配置
Docker Compose使用docker-compose.yml文件来定义和运行多容器Docker应用。以下是一个完整的AI应用系统部署配置示例:
# docker-compose.yml
version: '3.8'
# 定义网络
networks:
ai_network:
driver: bridge
ipam:
config:
- subnet: 172.22.0.0/16
# 定义卷
volumes:
postgres_data:
driver: local
redis_data:
driver: local
weaviate_data:
driver: local
# 定义服务
services:
# PostgreSQL数据库
db:
image: postgres:15-alpine
container_name: ai_postgres
restart: always
ports:
- "5432:5432"
environment:
POSTGRES_DB: ai_app
POSTGRES_USER: ai_user
POSTGRES_PASSWORD: ai_password123
POSTGRES_INITDB_ARGS: "--auth-host=scram-sha-256"
volumes:
- postgres_data:/var/lib/postgresql/data
- ./init-scripts:/docker-entrypoint-initdb.d
networks:
- ai_network
command: >
postgres
-c shared_buffers=256MB
-c effective_cache_size=1GB
-c maintenance_work_mem=64MB
-c checkpoint_completion_target=0.9
-c wal_buffers=16MB
-c default_statistics_target=100
-c random_page_cost=1.1
-c effective_io_concurrency=200
-c work_mem=16MB
-c min_wal_size=1GB
-c max_wal_size=4GB
healthcheck:
test: ["CMD-SHELL", "pg_isready -U ai_user -d ai_app"]
interval: 10s
timeout: 5s
retries: 5
logging:
driver: "json-file"
options:
max-size: "100m"
max-file: "10"
# Redis缓存
redis:
image: redis:7-alpine
container_name: ai_redis
restart: always
ports:
- "6379:6379"
volumes:
- redis_data:/data
networks:
- ai_network
command: redis-server --appendonly yes
sysctls:
- net.core.somaxconn=511
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 10s
timeout: 5s
retries: 5
logging:
driver: "json-file"
options:
max-size: "50m"
max-file: "5"
# Weaviate向量数据库
weaviate:
image: semitechnologies/weaviate:1.19.0
container_name: ai_weaviate
restart: always
ports:
- "8080:8080"
- "50051:50051"
environment:
QUERY_DEFAULTS_LIMIT: 25
AUTHENTICATION_ANONYMOUS_ACCESS_ENABLED: 'true'
PERSISTENCE_DATA_PATH: '/var/lib/weaviate'
DEFAULT_VECTORIZER_MODULE: 'none'
CLUSTER_HOSTNAME: 'node1'
# 解决setlocale问题
LANG: en_US.UTF-8
LANGUAGE: en_US:en
LC_ALL: en_US.UTF-8
volumes:
- weaviate_data:/var/lib/weaviate
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "100m"
max-file: "10"
# Nginx反向代理
nginx:
image: nginx:alpine
container_name: ai_nginx
restart: always
ports:
- "80:80"
- "443:443"
volumes:
- ./nginx/conf:/etc/nginx/conf.d:ro
- ./nginx/nginx.conf:/etc/nginx/nginx.conf:ro
- ./ssl:/etc/nginx/ssl:ro
- ./logs/nginx:/var/log/nginx
depends_on:
- api
- web
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "50m"
max-file: "5"
# API服务
api:
image: ai-api:latest
build:
context: ./api
dockerfile: Dockerfile
container_name: ai_api
restart: always
ports:
- "5000:5000"
environment:
# 数据库配置
DB_HOST: db
DB_PORT: 5432
DB_NAME: ai_app
DB_USER: ai_user
DB_PASSWORD: ai_password123
# Redis配置
REDIS_HOST: redis
REDIS_PORT: 6379
# Weaviate配置
WEAVIATE_HOST: weaviate
WEAVIATE_PORT: 8080
# 插件配置
PLUGIN_DAEMON_HOST: plugin_daemon
PLUGIN_DAEMON_PORT: 5003
# 沙箱配置
SANDBOX_HOST: sandbox
SANDBOX_PORT: 8194
# SSRF代理配置
SSRF_PROXY_HOST: ssrf_proxy
SSRF_PROXY_PORT: 3128
# 区域设置,解决setlocale问题
LANG: en_US.UTF-8
LANGUAGE: en_US:en
LC_ALL: en_US.UTF-8
# 应用配置
APP_ENV: production
SECRET_KEY: your-secret-key-here
depends_on:
db:
condition: service_healthy
redis:
condition: service_healthy
weaviate:
condition: service_started
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "100m"
max-file: "10"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:5000/health"]
interval: 30s
timeout: 10s
retries: 3
# Web前端
web:
image: ai-web:latest
build:
context: ./web
dockerfile: Dockerfile
container_name: ai_web
restart: always
ports:
- "3000:3000"
environment:
# API地址配置
REACT_APP_API_URL: http://api:5000
# 区域设置,解决setlocale问题
LANG: en_US.UTF-8
LANGUAGE: en_US:en
LC_ALL: en_US.UTF-8
depends_on:
- api
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "50m"
max-file: "5"
# 插件守护进程
plugin_daemon:
image: ai-plugin-daemon:latest
build:
context: ./plugin_daemon
dockerfile: Dockerfile
container_name: ai_plugin_daemon
restart: always
ports:
- "5003:5003"
environment:
# 区域设置,解决setlocale问题
LANG: en_US.UTF-8
LANGUAGE: en_US:en
LC_ALL: en_US.UTF-8
volumes:
- ./plugins:/app/plugins
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "50m"
max-file: "5"
# 安全沙箱
sandbox:
image: ai-sandbox:latest
build:
context: ./sandbox
dockerfile: Dockerfile
container_name: ai_sandbox
restart: always
ports:
- "8194:8194"
environment:
SANDBOX_PORT: 8194
# 区域设置,解决setlocale问题
LANG: en_US.UTF-8
LANGUAGE: en_US:en
LC_ALL: en_US.UTF-8
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "50m"
max-file: "5"
# SSRF代理
ssrf_proxy:
image: ubuntu/squid:latest
container_name: ai_squid
restart: always
ports:
- "3128:3128"
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "50m"
max-file: "5"
# Worker服务
worker:
image: ai-api:latest
container_name: ai_worker
restart: always
environment:
# 数据库配置
DB_HOST: db
DB_PORT: 5432
DB_NAME: ai_app
DB_USER: ai_user
DB_PASSWORD: ai_password123
# Redis配置
REDIS_HOST: redis
REDIS_PORT: 6379
# Weaviate配置
WEAVIATE_HOST: weaviate
WEAVIATE_PORT: 8080
# 插件配置
PLUGIN_DAEMON_HOST: plugin_daemon
PLUGIN_DAEMON_PORT: 5003
# Worker配置
EXECUTOR_TYPE: worker
# 区域设置,解决setlocale问题
LANG: en_US.UTF-8
LANGUAGE: en_US:en
LC_ALL: en_US.UTF-8
depends_on:
db:
condition: service_healthy
redis:
condition: service_healthy
weaviate:
condition: service_started
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "100m"
max-file: "10"
command: celery -A app.celery worker -P gevent -c 10 -Q default,high_priority
# Worker Beat服务
worker_beat:
image: ai-api:latest
container_name: ai_worker_beat
restart: always
environment:
# 数据库配置
DB_HOST: db
DB_PORT: 5432
DB_NAME: ai_app
DB_USER: ai_user
DB_PASSWORD: ai_password123
# Redis配置
REDIS_HOST: redis
REDIS_PORT: 6379
# Worker配置
EXECUTOR_TYPE: worker-beat
# 区域设置,解决setlocale问题
LANG: en_US.UTF-8
LANGUAGE: en_US:en
LC_ALL: en_US.UTF-8
depends_on:
db:
condition: service_healthy
redis:
condition: service_healthy
networks:
- ai_network
logging:
driver: "json-file"
options:
max-size: "50m"
max-file: "5"
command: celery -A app.celery beat
# 配置卷
volumes:
postgres_data:
redis_data:
weaviate_data:
第四章:Nginx配置详解
Nginx作为反向代理服务器,在AI应用系统中起着至关重要的作用。以下是Nginx的配置示例:
# nginx/nginx.conf
user nginx;
worker_processes auto;
error_log /var/log/nginx/error.log;
pid /run/nginx.pid;
events {
worker_connections 1024;
}
http {
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
include /etc/nginx/mime.types;
default_type application/octet-stream;
# 定义上游服务器
upstream api_backend {
server api:5000;
}
upstream web_backend {
server web:3000;
}
# HTTP服务器配置
server {
listen 80;
server_name _;
# API请求转发
location /api/ {
proxy_pass http://api_backend/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# 超时设置
proxy_connect_timeout 30s;
proxy_send_timeout 30s;
proxy_read_timeout 30s;
}
# 静态资源和Web前端
location / {
proxy_pass http://web_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
# WebSocket支持
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
# 健康检查端点
location /health {
access_log off;
return 200 "healthy\n";
add_header Content-Type text/plain;
}
}
# HTTPS服务器配置(如果需要)
# server {
# listen 443 ssl http2;
# server_name your-domain.com;
#
# ssl_certificate /etc/nginx/ssl/cert.pem;
# ssl_certificate_key /etc/nginx/ssl/key.pem;
#
# # 其他SSL配置...
# }
include /etc/nginx/conf.d/*.conf;
}
第五章:常见问题及解决方案
在部署AI应用系统过程中,可能会遇到各种问题。以下是常见问题及其解决方案:
5.1 插件加载失败问题
问题现象:
插件守护进程无法加载插件,出现类似以下错误:
Error while finding module specification for 'main.py' (ModuleNotFoundError: __path__ attribute not found on 'main' while trying to find 'main.py')
解决方案:
- 检查插件目录结构:
# 进入插件容器检查目录结构
docker-compose exec plugin_daemon ls -la /app/plugins/
# 确保插件目录包含以下文件:
# - main.py (插件主文件)
# - plugin.json (插件配置文件)
# - requirements.txt (依赖文件,可选)
- 检查插件配置文件:
{
"name": "example_plugin",
"version": "1.0.0",
"description": "示例插件",
"entrypoint": "main",
"dependencies": []
}
- 验证Python环境:
# 进入插件容器
docker-compose exec plugin_daemon /bin/bash
# 激活虚拟环境(如果使用)
source /app/plugins/example_plugin/.venv/bin/activate
# 检查依赖安装
pip list
# 手动测试插件
cd /app/plugins/example_plugin
python -m main
- 插件守护进程代码示例:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
插件守护进程
负责插件的加载、管理和执行
"""
import os
import sys
import json
import importlib.util
import logging
from typing import Dict, Any, Optional
from flask import Flask, request, jsonify
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
class PluginManager:
"""插件管理器"""
def __init__(self, plugins_dir: str = "/app/plugins"):
"""
初始化插件管理器
Args:
plugins_dir: 插件目录路径
"""
self.plugins_dir = plugins_dir
self.plugins: Dict[str, Any] = {}
self.load_plugins()
def load_plugins(self) -> None:
"""加载所有插件"""
logger.info(f"开始加载插件,插件目录: {self.plugins_dir}")
if not os.path.exists(self.plugins_dir):
logger.warning(f"插件目录不存在: {self.plugins_dir}")
return
# 遍历插件目录
for plugin_name in os.listdir(self.plugins_dir):
plugin_path = os.path.join(self.plugins_dir, plugin_name)
# 检查是否为目录
if not os.path.isdir(plugin_path):
continue
try:
# 加载插件配置
config_path = os.path.join(plugin_path, "plugin.json")
if not os.path.exists(config_path):
logger.warning(f"插件 {plugin_name} 缺少配置文件")
continue
with open(config_path, 'r', encoding='utf-8') as f:
config = json.load(f)
# 加载插件主模块
module_name = config.get('entrypoint', 'main')
module_path = os.path.join(plugin_path, f"{module_name}.py")
if not os.path.exists(module_path):
logger.warning(f"插件 {plugin_name} 主模块不存在: {module_path}")
continue
# 动态加载模块
spec = importlib.util.spec_from_file_location(
f"{plugin_name}_{module_name}", module_path
)
module = importlib.util.module_from_spec(spec)
spec.loader.exec_module(module)
# 获取插件类(假设插件类名为Plugin)
if not hasattr(module, 'Plugin'):
logger.warning(f"插件 {plugin_name} 缺少Plugin类")
continue
plugin_class = getattr(module, 'Plugin')
plugin_instance = plugin_class()
# 保存插件信息
self.plugins[plugin_name] = {
'config': config,
'module': module,
'instance': plugin_instance
}
logger.info(f"成功加载插件: {plugin_name}")
except Exception as e:
logger.error(f"加载插件 {plugin_name} 失败: {e}")
# 继续加载其他插件
def get_plugin(self, plugin_name: str) -> Optional[Dict[str, Any]]:
"""
获取插件实例
Args:
plugin_name: 插件名称
Returns:
插件信息字典或None
"""
return self.plugins.get(plugin_name)
def list_plugins(self) -> Dict[str, Any]:
"""
列出所有插件
Returns:
插件列表
"""
return {
name: {
'name': name,
'description': plugin['config'].get('description', ''),
'version': plugin['config'].get('version', '1.0.0'),
'author': plugin['config'].get('author', 'Unknown')
}
for name, plugin in self.plugins.items()
}
def execute_plugin(self, plugin_name: str, data: Dict[str, Any]) -> Dict[str, Any]:
"""
执行插件
Args:
plugin_name: 插件名称
data: 输入数据
Returns:
执行结果
"""
plugin = self.get_plugin(plugin_name)
if not plugin:
return {
'success': False,
'error': f'插件 {plugin_name} 未找到'
}
try:
# 调用插件的execute方法
result = plugin['instance'].execute(data)
return {
'success': True,
'result': result
}
except Exception as e:
logger.error(f"执行插件 {plugin_name} 失败: {e}")
return {
'success': False,
'error': str(e)
}
# 创建Flask应用
app = Flask(__name__)
# 初始化插件管理器
plugin_manager = PluginManager()
@app.route('/plugins', methods=['GET'])
def list_plugins():
"""获取插件列表"""
try:
plugins = plugin_manager.list_plugins()
return jsonify({
'success': True,
'data': plugins
})
except Exception as e:
logger.error(f"获取插件列表失败: {e}")
return jsonify({
'success': False,
'error': str(e)
}), 500
@app.route('/plugins/<plugin_name>/execute', methods=['POST'])
def execute_plugin(plugin_name: str):
"""执行插件"""
try:
# 获取请求数据
data = request.get_json() or {}
# 执行插件
result = plugin_manager.execute_plugin(plugin_name, data)
if result['success']:
return jsonify(result)
else:
return jsonify(result), 400
except Exception as e:
logger.error(f"执行插件 {plugin_name} 失败: {e}")
return jsonify({
'success': False,
'error': str(e)
}), 500
@app.route('/health', methods=['GET'])
def health_check():
"""健康检查"""
return jsonify({
'status': 'healthy',
'plugins_count': len(plugin_manager.plugins)
})
def main():
"""主函数"""
host = os.environ.get('HOST', '0.0.0.0')
port = int(os.environ.get('PORT', 5003))
logger.info(f"插件守护进程启动,监听 {host}:{port}")
app.run(host=host, port=port, debug=False)
if __name__ == "__main__":
main()
5.2 setlocale警告问题
问题现象:
容器启动时出现以下警告:
bash: warning: setlocale: LC_ALL: cannot change locale (en_US.UTF-8)
perl: warning: Setting locale failed.
解决方案:
- 在Dockerfile中安装区域设置支持:
# plugin_daemon/Dockerfile
FROM python:3.9-slim
# 设置工作目录
WORKDIR /app
# 安装系统依赖和区域设置
RUN apt-get update && \
apt-get install -y locales && \
rm -rf /var/lib/apt/lists/* && \
locale-gen en_US.UTF-8
# 设置环境变量
ENV LANG=en_US.UTF-8
ENV LANGUAGE=en_US:en
ENV LC_ALL=en_US.UTF-8
# 复制依赖文件
COPY requirements.txt .
# 安装Python依赖
RUN pip install --no-cache-dir -r requirements.txt
# 复制应用代码
COPY . .
# 暴露端口
EXPOSE 5003
# 启动应用
CMD ["python", "main.py"]
- 在docker-compose.yml中设置环境变量:
services:
plugin_daemon:
environment:
LANG: en_US.UTF-8
LANGUAGE: en_US:en
LC_ALL: en_US.UTF-8
5.3 数据库连接失败问题
问题现象:
API服务无法连接到数据库,出现连接超时或认证失败错误
解决方案:
- 检查数据库服务状态:
docker-compose ps db
- 测试数据库连接:
docker-compose exec db pg_isready -U ai_user -d ai_app
- 检查数据库配置:
docker-compose exec db psql -U ai_user -d ai_app -c "SELECT version();"
- API服务数据库连接代码示例:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
AI应用API服务
包含数据库连接、缓存、向量搜索等功能
"""
import os
import logging
from typing import Dict, Any, Optional
from flask import Flask, request, jsonify
from flask_cors import CORS
import psycopg2
from psycopg2.extras import RealDictCursor
import redis
import requests
import json
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
class DatabaseManager:
"""数据库管理器"""
def __init__(self):
"""初始化数据库连接"""
self.host = os.environ.get('DB_HOST', 'localhost')
self.port = int(os.environ.get('DB_PORT', 5432))
self.database = os.environ.get('DB_NAME', 'ai_app')
self.user = os.environ.get('DB_USER', 'ai_user')
self.password = os.environ.get('DB_PASSWORD', 'ai_password123')
self.connection = None
self.connect()
def connect(self) -> bool:
"""
建立数据库连接
Returns:
是否连接成功
"""
try:
self.connection = psycopg2.connect(
host=self.host,
port=self.port,
database=self.database,
user=self.user,
password=self.password,
cursor_factory=RealDictCursor
)
logger.info("数据库连接成功")
return True
except Exception as e:
logger.error(f"数据库连接失败: {e}")
return False
def execute_query(self, query: str, params: tuple = None) -> Optional[list]:
"""
执行查询语句
Args:
query: SQL查询语句
params: 查询参数
Returns:
查询结果或None
"""
try:
if not self.connection or self.connection.closed:
if not self.connect():
return None
with self.connection.cursor() as cursor:
cursor.execute(query, params)
if query.strip().upper().startswith('SELECT'):
return cursor.fetchall()
else:
self.connection.commit()
return cursor.rowcount
except Exception as e:
logger.error(f"执行查询失败: {e}")
if self.connection:
self.connection.rollback()
return None
class CacheManager:
"""缓存管理器"""
def __init__(self):
"""初始化Redis连接"""
self.host = os.environ.get('REDIS_HOST', 'localhost')
self.port = int(os.environ.get('REDIS_PORT', 6379))
self.client = None
self.connect()
def connect(self) -> bool:
"""
建立Redis连接
Returns:
是否连接成功
"""
try:
self.client = redis.Redis(
host=self.host,
port=self.port,
decode_responses=True
)
# 测试连接
self.client.ping()
logger.info("Redis连接成功")
return True
except Exception as e:
logger.error(f"Redis连接失败: {e}")
return False
def get(self, key: str) -> Optional[str]:
"""
获取缓存值
Args:
key: 缓存键
Returns:
缓存值或None
"""
try:
if not self.client:
if not self.connect():
return None
return self.client.get(key)
except Exception as e:
logger.error(f"获取缓存失败: {e}")
return None
def set(self, key: str, value: str, expire: int = 3600) -> bool:
"""
设置缓存值
Args:
key: 缓存键
value: 缓存值
expire: 过期时间(秒)
Returns:
是否设置成功
"""
try:
if not self.client:
if not self.connect():
return False
self.client.setex(key, expire, value)
return True
except Exception as e:
logger.error(f"设置缓存失败: {e}")
return False
class VectorSearchManager:
"""向量搜索管理器"""
def __init__(self):
"""初始化Weaviate连接"""
self.host = os.environ.get('WEAVIATE_HOST', 'localhost')
self.port = int(os.environ.get('WEAVIATE_PORT', 8080))
self.base_url = f"http://{self.host}:{self.port}"
def search(self, query_text: str, class_name: str = "Document") -> Optional[Dict]:
"""
执行向量搜索
Args:
query_text: 查询文本
class_name: Weaviate类名
Returns:
搜索结果或None
"""
try:
# 构建GraphQL查询
graphql_query = {
"query": f"""
{{
Get {{
{class_name}(
nearText: {{
concepts: ["{query_text}"]
}}
limit: 5
) {{
content
title
_additional {{
certainty
}}
}}
}}
}}
"""
}
# 发送查询请求
response = requests.post(
f"{self.base_url}/v1/graphql",
json=graphql_query,
headers={"Content-Type": "application/json"}
)
if response.status_code == 200:
return response.json()
else:
logger.error(f"向量搜索失败: {response.status_code} - {response.text}")
return None
except Exception as e:
logger.error(f"向量搜索异常: {e}")
return None
# 创建Flask应用
app = Flask(__name__)
CORS(app)
# 初始化管理器
db_manager = DatabaseManager()
cache_manager = CacheManager()
vector_manager = VectorSearchManager()
@app.route('/')
def index():
"""首页"""
return jsonify({
'message': 'AI应用API服务已启动',
'status': 'running'
})
@app.route('/health')
def health_check():
"""健康检查"""
# 检查数据库连接
db_status = db_manager.connection and not db_manager.connection.closed
# 检查Redis连接
redis_status = False
try:
if cache_manager.client:
cache_manager.client.ping()
redis_status = True
except:
pass
return jsonify({
'status': 'healthy' if (db_status and redis_status) else 'unhealthy',
'database': 'connected' if db_status else 'disconnected',
'redis': 'connected' if redis_status else 'disconnected'
})
@app.route('/search', methods=['POST'])
def search():
"""执行搜索"""
try:
# 获取请求数据
data = request.get_json()
query_text = data.get('query')
if not query_text:
return jsonify({
'success': False,
'error': '缺少查询参数'
}), 400
# 首先检查缓存
cache_key = f"search:{query_text}"
cached_result = cache_manager.get(cache_key)
if cached_result:
logger.info(f"从缓存获取搜索结果: {query_text}")
return jsonify({
'success': True,
'data': json.loads(cached_result),
'from_cache': True
})
# 执行向量搜索
result = vector_manager.search(query_text)
if result and 'data' in result and 'Get' in result['data']:
# 缓存结果
cache_manager.set(cache_key, json.dumps(result), expire=300) # 缓存5分钟
return jsonify({
'success': True,
'data': result,
'from_cache': False
})
else:
return jsonify({
'success': False,
'error': '未找到相关结果'
}), 404
except Exception as e:
logger.error(f"搜索接口异常: {e}")
return jsonify({
'success': False,
'error': '服务器内部错误'
}), 500
@app.route('/documents', methods=['GET'])
def list_documents():
"""列出文档"""
try:
# 从数据库获取文档列表
query = "SELECT id, title, created_at FROM documents ORDER BY created_at DESC LIMIT 100"
results = db_manager.execute_query(query)
if results is not None:
return jsonify({
'success': True,
'data': results
})
else:
return jsonify({
'success': False,
'error': '数据库查询失败'
}), 500
except Exception as e:
logger.error(f"获取文档列表异常: {e}")
return jsonify({
'success': False,
'error': '服务器内部错误'
}), 500
def main():
"""主函数"""
host = os.environ.get('HOST', '0.0.0.0')
port = int(os.environ.get('PORT', 5000))
logger.info(f"AI应用API服务启动中,监听 {host}:{port}")
app.run(host=host, port=port, debug=False)
if __name__ == "__main__":
main()
第六章:实践案例 - 智能客服系统
6.1 应用场景描述
假设我们正在开发一个智能客服系统,用户可以通过Web前端提交问题,系统通过API服务调用Weaviate向量数据库进行语义搜索,并返回最相关的答案。
6.2 系统目录结构
ai-customer-service/
├── docker-compose.yml # Docker Compose配置文件
├── nginx/ # Nginx配置
│ ├── nginx.conf # Nginx主配置文件
│ └── conf/ # 其他配置文件
├── api/ # API服务
│ ├── Dockerfile # API服务Dockerfile
│ ├── requirements.txt # Python依赖
│ ├── main.py # API服务主程序
│ └── app.py # Flask应用
├── web/ # Web前端
│ ├── Dockerfile # Web服务Dockerfile
│ ├── package.json # Node.js依赖
│ └── src/ # 前端源码
├── plugin_daemon/ # 插件守护进程
│ ├── Dockerfile # 插件服务Dockerfile
│ ├── requirements.txt # Python依赖
│ └── main.py # 插件守护进程主程序
├── plugins/ # 插件目录
│ └── faq_search/ # FAQ搜索插件
│ ├── plugin.json # 插件配置
│ ├── main.py # 插件主程序
│ └── requirements.txt # 插件依赖
├── init-scripts/ # 数据库初始化脚本
│ └── init.sql # 初始化SQL脚本
└── logs/ # 日志目录
├── nginx/ # Nginx日志
└── app/ # 应用日志
6.3 FAQ搜索插件实现
# plugins/faq_search/main.py
# -*- coding: utf-8 -*-
"""
FAQ搜索插件
用于在FAQ数据库中搜索相关问题的答案
"""
import logging
import sqlite3
import os
from typing import Dict, Any, List
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
class Plugin:
"""FAQ搜索插件类"""
def __init__(self):
"""初始化插件"""
self.name = "faq_search"
self.version = "1.0.0"
self.description = "FAQ搜索插件"
# 初始化数据库连接
self.db_path = os.environ.get('FAQ_DB_PATH', '/app/plugins/faq_search/faq.db')
self.init_database()
logger.info(f"FAQ搜索插件初始化完成,版本: {self.version}")
def init_database(self) -> None:
"""初始化数据库"""
try:
# 创建数据库连接
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
# 创建FAQ表
cursor.execute('''
CREATE TABLE IF NOT EXISTS faq (
id INTEGER PRIMARY KEY AUTOINCREMENT,
question TEXT NOT NULL,
answer TEXT NOT NULL,
category TEXT,
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)
''')
# 插入示例数据
sample_faqs = [
("如何重置密码?", "您可以在登录页面点击'忘记密码'链接,按照提示操作即可重置密码。", "账户管理"),
("如何联系客服?", "您可以通过以下方式联系客服:1. 在线客服聊天;2. 拨打客服热线:400-123-4567;3. 发送邮件至 support@example.com", "客户服务"),
("退款政策是什么?", "我们提供7天无理由退款服务。请确保商品未使用且包装完整,联系客服申请退款。", "售后服务"),
("如何修改个人信息?", "登录后进入'个人中心'->'个人信息'页面,可以修改您的个人信息。", "账户管理"),
("支持哪些支付方式?", "我们支持支付宝、微信支付、银联卡支付等多种支付方式。", "支付问题")
]
cursor.executemany(
"INSERT OR IGNORE INTO faq (question, answer, category) VALUES (?, ?, ?)",
sample_faqs
)
conn.commit()
conn.close()
logger.info("FAQ数据库初始化完成")
except Exception as e:
logger.error(f"初始化数据库失败: {e}")
def search_faq(self, query: str) -> List[Dict[str, Any]]:
"""
搜索FAQ
Args:
query: 查询关键词
Returns:
匹配的FAQ列表
"""
try:
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
# 简单的关键词匹配搜索
search_query = f"%{query}%"
cursor.execute('''
SELECT id, question, answer, category, created_at
FROM faq
WHERE question LIKE ? OR answer LIKE ?
ORDER BY id
LIMIT 5
''', (search_query, search_query))
results = []
for row in cursor.fetchall():
results.append({
'id': row[0],
'question': row[1],
'answer': row[2],
'category': row[3],
'created_at': row[4]
})
conn.close()
return results
except Exception as e:
logger.error(f"搜索FAQ失败: {e}")
return []
def execute(self, data: Dict[str, Any]) -> Dict[str, Any]:
"""
执行插件功能
Args:
data: 输入数据,应包含query字段
Returns:
执行结果
"""
try:
# 检查必需参数
if 'query' not in data:
return {
'success': False,
'error': '缺少query参数'
}
query = data['query']
if not query or not isinstance(query, str):
return {
'success': False,
'error': 'query参数无效'
}
# 执行搜索
results = self.search_faq(query)
return {
'success': True,
'query': query,
'results': results,
'count': len(results)
}
except Exception as e:
logger.error(f"执行插件失败: {e}")
return {
'success': False,
'error': str(e)
}
# 插件配置文件 (plugin.json)
"""
{
"name": "faq_search",
"version": "1.0.0",
"description": "FAQ搜索插件",
"entrypoint": "main",
"author": "AI Team",
"dependencies": []
}
"""
第七章:性能优化与最佳实践
7.1 资源配置优化
# 为关键服务配置资源限制
services:
api:
deploy:
resources:
limits:
cpus: '2.0'
memory: 2G
reservations:
cpus: '1.0'
memory: 1G
db:
deploy:
resources:
limits:
cpus: '2.0'
memory: 2G
reservations:
cpus: '1.0'
memory: 1G
weaviate:
deploy:
resources:
limits:
cpus: '1.0'
memory: 1G
reservations:
cpus: '0.5'
memory: 512M
7.2 数据库优化
-- init-scripts/init.sql
-- 创建索引优化查询性能
CREATE INDEX IF NOT EXISTS idx_documents_title ON documents(title);
CREATE INDEX IF NOT EXISTS idx_documents_category ON documents(category);
CREATE INDEX IF NOT EXISTS idx_faq_question ON faq(question);
CREATE INDEX IF NOT EXISTS idx_faq_category ON faq(category);
7.3 缓存策略
# 实现多级缓存策略
class CacheManager:
"""多级缓存管理器"""
def __init__(self):
# 本地内存缓存(LRU)
self.local_cache = {}
self.local_cache_max_size = 1000
# Redis缓存
self.redis_client = None
self.connect_redis()
def get_multi_level(self, key: str) -> Optional[Any]:
"""
多级缓存获取
Args:
key: 缓存键
Returns:
缓存值或None
"""
# 1. 先查本地缓存
if key in self.local_cache:
return self.local_cache[key]
# 2. 再查Redis缓存
try:
if self.redis_client:
value = self.redis_client.get(key)
if value:
# 放入本地缓存
self._set_local_cache(key, value)
return value
except Exception as e:
logger.error(f"Redis缓存获取失败: {e}")
return None
def set_multi_level(self, key: str, value: Any, expire: int = 3600) -> None:
"""
多级缓存设置
Args:
key: 缓存键
value: 缓存值
expire: 过期时间(秒)
"""
# 1. 设置本地缓存
self._set_local_cache(key, value)
# 2. 设置Redis缓存
try:
if self.redis_client:
self.redis_client.setex(key, expire, value)
except Exception as e:
logger.error(f"Redis缓存设置失败: {e}")
def _set_local_cache(self, key: str, value: Any) -> None:
"""设置本地缓存"""
if len(self.local_cache) >= self.local_cache_max_size:
# 简单的LRU实现:删除第一个元素
first_key = next(iter(self.local_cache))
del self.local_cache[first_key]
self.local_cache[key] = value
第八章:监控与日志管理
8.1 健康检查端点
@app.route('/health')
def health_check():
"""健康检查"""
health_status = {
'status': 'healthy',
'timestamp': datetime.now().isoformat(),
'services': {}
}
# 检查数据库
try:
db_status = db_manager.connection and not db_manager.connection.closed
health_status['services']['database'] = 'healthy' if db_status else 'unhealthy'
except Exception as e:
health_status['services']['database'] = f'unhealthy: {str(e)}'
# 检查Redis
try:
if cache_manager.client:
cache_manager.client.ping()
health_status['services']['redis'] = 'healthy'
else:
health_status['services']['redis'] = 'unhealthy: client not initialized'
except Exception as e:
health_status['services']['redis'] = f'unhealthy: {str(e)}'
# 检查Weaviate
try:
response = requests.get(f"{vector_manager.base_url}/v1/meta", timeout=5)
health_status['services']['weaviate'] = 'healthy' if response.status_code == 200 else 'unhealthy'
except Exception as e:
health_status['services']['weaviate'] = f'unhealthy: {str(e)}'
# 检查插件守护进程
try:
plugin_url = f"http://{os.environ.get('PLUGIN_DAEMON_HOST', 'plugin_daemon')}:{os.environ.get('PLUGIN_DAEMON_PORT', 5003)}/health"
response = requests.get(plugin_url, timeout=5)
health_status['services']['plugin_daemon'] = 'healthy' if response.status_code == 200 else 'unhealthy'
except Exception as e:
health_status['services']['plugin_daemon'] = f'unhealthy: {str(e)}'
# 总体状态
overall_healthy = all('healthy' in status for status in health_status['services'].values())
health_status['status'] = 'healthy' if overall_healthy else 'unhealthy'
return jsonify(health_status)
8.2 日志分析工具
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
AI应用系统日志分析工具
用于分析和监控各服务的日志
"""
import subprocess
import re
import json
import time
from typing import Dict, List, Optional
from datetime import datetime
import logging
# 配置日志
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
class AISystemLogAnalyzer:
"""AI系统日志分析器"""
def __init__(self, project_name: str = "ai-system"):
"""
初始化日志分析器
Args:
project_name: Docker Compose项目名称
"""
self.project_name = project_name
self.services = [
'api', 'web', 'db', 'redis', 'weaviate',
'plugin_daemon', 'sandbox', 'ssrf_proxy',
'worker', 'worker_beat', 'nginx'
]
self.error_patterns = [
r'ERROR',
r'error',
r'exception',
r'Exception',
r'failed',
r'Failed',
r'warning',
r'Warning'
]
def get_service_logs(self, service_name: str, lines: int = 100) -> Optional[str]:
"""
获取指定服务的日志
Args:
service_name: 服务名称
lines: 获取日志行数
Returns:
日志内容或None
"""
try:
# 构建命令
cmd = [
"docker-compose",
"logs",
"--tail",
str(lines),
service_name
]
# 执行命令
result = subprocess.run(
cmd,
capture_output=True,
text=True,
timeout=30
)
if result.returncode == 0:
return result.stdout
else:
logger.error(f"获取{service_name}日志失败: {result.stderr}")
return None
except subprocess.TimeoutExpired:
logger.error(f"获取{service_name}日志超时")
return None
except Exception as e:
logger.error(f"获取{service_name}日志异常: {e}")
return None
def analyze_service_logs(self, service_name: str) -> Dict:
"""
分析指定服务的日志
Args:
service_name: 服务名称
Returns:
分析结果
"""
# 获取日志
logs = self.get_service_logs(service_name)
if not logs:
return {
'service': service_name,
'success': False,
'error': '无法获取日志'
}
# 分析日志
lines = logs.split('\n')
error_count = 0
warning_count = 0
errors = []
for line in lines:
# 检查错误模式
for pattern in self.error_patterns:
if re.search(pattern, line):
if 'error' in pattern.lower() or 'Error' in pattern or 'failed' in pattern.lower() or 'Failed' in pattern:
error_count += 1
errors.append(line.strip())
elif 'warning' in pattern.lower() or 'Warning' in pattern:
warning_count += 1
return {
'service': service_name,
'success': True,
'total_lines': len(lines),
'error_count': error_count,
'warning_count': warning_count,
'errors': errors[-10:] if errors else [], # 只保留最近10个错误
'analyzed_at': datetime.now().isoformat()
}
def analyze_all_services(self) -> List[Dict]:
"""
分析所有服务的日志
Returns:
所有服务的分析结果
"""
results = []
for service in self.services:
logger.info(f"正在分析{service}服务日志...")
result = self.analyze_service_logs(service)
results.append(result)
time.sleep(1) # 避免过于频繁的请求
return results
def get_system_status(self) -> Dict:
"""
获取系统状态
Returns:
系统状态信息
"""
try:
# 执行docker-compose ps命令
result = subprocess.run(
["docker-compose", "ps"],
capture_output=True,
text=True,
timeout=10
)
if result.returncode == 0:
lines = result.stdout.strip().split('\n')
services_status = []
# 解析服务状态
for line in lines[1:]: # 跳过标题行
if line.strip():
parts = line.split()
if len(parts) >= 4:
service_info = {
'name': parts[0],
'status': ' '.join(parts[3:]) # 状态信息可能包含空格
}
services_status.append(service_info)
return {
'success': True,
'services': services_status,
'checked_at': datetime.now().isoformat()
}
else:
return {
'success': False,
'error': result.stderr
}
except Exception as e:
logger.error(f"获取系统状态失败: {e}")
return {
'success': False,
'error': str(e)
}
def generate_report(self) -> Dict:
"""
生成完整的日志分析报告
Returns:
分析报告
"""
logger.info("开始生成AI系统日志分析报告...")
# 获取系统状态
system_status = self.get_system_status()
# 分析所有服务日志
analysis_results = self.analyze_all_services()
# 统计信息
total_errors = sum(result.get('error_count', 0) for result in analysis_results)
total_warnings = sum(result.get('warning_count', 0) for result in analysis_results)
report = {
'report_generated_at': datetime.now().isoformat(),
'project_name': self.project_name,
'system_status': system_status,
'log_analysis': analysis_results,
'summary': {
'total_services': len(self.services),
'total_errors': total_errors,
'total_warnings': total_warnings,
'error_rate': round(total_errors / len(self.services), 2) if self.services else 0
}
}
logger.info("日志分析报告生成完成")
return report
def main():
"""主函数"""
# 创建分析器实例
analyzer = AISystemLogAnalyzer()
# 生成报告
report = analyzer.generate_report()
# 输出报告
print(json.dumps(report, indent=2, ensure_ascii=False))
# 检查是否有严重问题
total_errors = report['summary']['total_errors']
if total_errors > 0:
print(f"\n⚠️ 发现 {total_errors} 个错误,请检查相关服务日志")
else:
print("\n✅ 所有服务日志正常")
if __name__ == "__main__":
main()
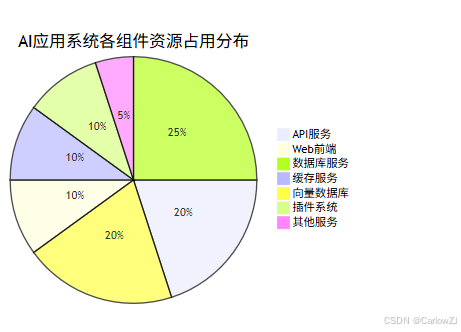
第九章:项目实施计划
第十章:数据分布与性能分析
总结
本文全面介绍了AI应用系统的Docker Compose部署方法,并针对部署过程中可能遇到的常见问题提供了详细的解决方案。通过系统的学习和实践,我们可以总结出以下关键要点:
核心要点回顾
- 系统架构设计:合理的架构设计是成功部署的基础,需要充分考虑各组件之间的关系和依赖
- 配置文件编写:正确编写docker-compose.yml文件,确保各服务正确配置和连接
- 环境变量管理:合理使用环境变量,特别是解决setlocale等常见问题
- 依赖关系处理:使用健康检查确保服务依赖关系正确处理
- 日志管理监控:建立完善的日志管理和监控机制
- 问题排查技巧:掌握常见问题的排查方法和解决方案
最佳实践建议
- 分层部署:建议按照数据层→服务层→接入层的顺序逐步部署
- 资源配置:根据实际需求合理配置各服务的资源限制和保留资源
- 健康检查:为关键服务配置健康检查,确保服务稳定运行
- 日志轮转:配置日志轮转策略,避免日志文件过大
- 安全配置:使用强密码,避免使用默认配置
- 备份策略:定期备份数据库等重要数据
- 监控告警:建立完善的监控和告警机制
未来展望
随着AI技术的不断发展,AI应用系统也将持续演进:
- 更多AI能力集成:支持更多类型的AI模型和服务
- 云原生集成:更好地与Kubernetes等云原生技术集成
- 边缘计算支持:支持在边缘设备上部署AI应用
- 自动化运维:实现更智能的自动化部署和运维管理
- 安全增强:加强安全防护机制,确保系统安全
通过本文的学习和实践,开发者可以快速掌握复杂AI应用系统的部署技能,为构建强大的AI应用奠定坚实基础。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











