






摘要
本文系统介绍Claude大模型的增强推理、分步思考与多Agent协作机制,涵盖元提示(Metaprompt)设计、任务拆解与多智能体协作等核心技术。通过实战案例与可视化图表,帮助中国AI开发者掌握高效构建复杂推理与协作型AI系统的最佳实践。
目录
增强推理与分步思考原理
- 增强推理:通过链式思考(Chain-of-Thought)、分步推理等方式,让大模型具备更强的逻辑推理与复杂任务拆解能力。
- 分步思考:将复杂问题拆解为多个子任务,逐步分析与解决。
- 应用场景:复杂问答、数学推理、流程决策、自动化分析等。
重点:分步思考与推理链设计是提升AI系统可靠性与可解释性的关键。
Claude元提示(Metaprompt)设计与应用
- 元提示(Metaprompt):为AI生成高质量Prompt的“提示模板”,解决“空白页”难题。
- 设计要点:
- 明确任务目标与输入输出格式
- 提供多轮示例与边界约束
- 支持变量与上下文注入
- 代码示例:
import anthropic
client = anthropic.Client(api_key="你的API_KEY")
metaprompt = '''
你是一名AI提示词专家。请根据用户任务,生成高质量的Prompt模板。
示例:
<Task>文本摘要</Task>
<Prompt>请对以下内容进行简明摘要:{content}</Prompt>
...(可扩展多任务示例)...
'''
response = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=256,
messages=[{"role": "user", "content": metaprompt + "\n<Task>情感分析</Task>"}]
)
print(response.content)
多Agent协作与任务拆解实战
- 多Agent协作:通过主控Agent(Orchestrator)与子Agent(Worker)分工协作,提升复杂任务处理能力。
- 典型模式:
- 并行分工(Breadth-first):多个子Agent独立处理子任务
- 深度协作(Depth-first):多Agent多角度深入分析同一问题
- 代码示例:
# 伪代码:主控Agent分配任务,子Agent并行处理
subtasks = ["分析A方案优缺点", "分析B方案优缺点", "分析C方案优缺点"]
results = []
for task in subtasks:
prompt = f"请详细分析:{task}"
response = client.messages.create(
model="claude-3-opus-20240229",
max_tokens=256,
messages=[{"role": "user", "content": prompt}]
)
results.append(response.content)
# 汇总结果
total_report = "\n".join(results)
print(total_report)
架构图、流程图与思维导图
图1:增强推理与多Agent协作系统架构图
图2:多Agent协作与分步推理业务流程图
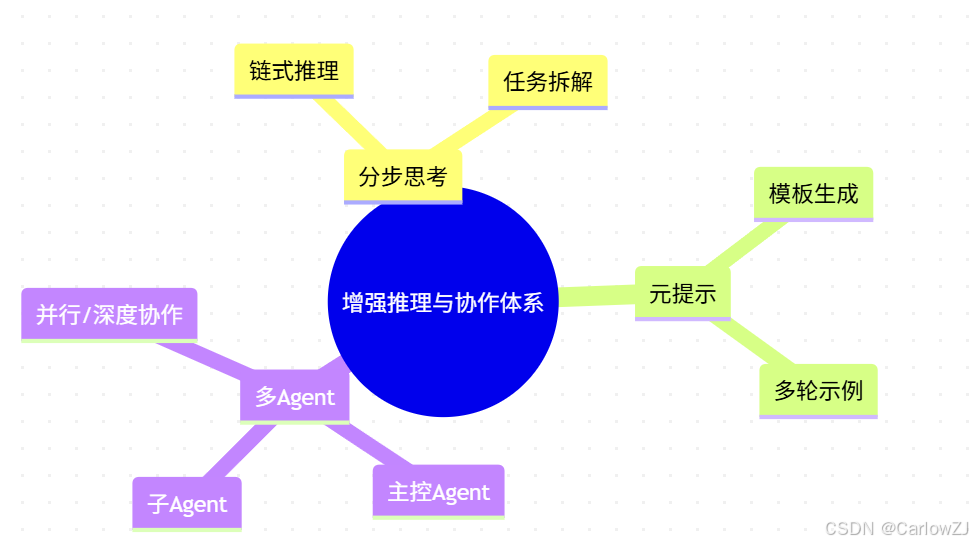
图3:增强推理与多Agent协作知识体系思维导图
注意事项与最佳实践
- 分步推理需明确每步目标,防止遗漏
- 元提示模板应覆盖多场景,便于复用
- 多Agent协作需合理分工,防止重复与冲突
- 结果汇总需二次推理与一致性校验
- 复杂任务建议引入人工审核与兜底机制
常见问题与扩展阅读
常见问题:
- 多Agent协作时如何防止信息丢失?
- 建议每步结果显式传递与记录。
- 元提示如何适配不同任务?
- 设计变量与多轮示例,支持灵活扩展。
- 分步推理如何保证准确性?
- 每步输出需有明确标准与校验。
扩展阅读:
总结与参考资料
本文系统梳理了Claude增强推理、分步思考与多Agent协作的核心原理、元提示设计与实战案例。建议开发者结合自身业务场景,灵活选用推理链、元提示与多Agent协作方案,持续关注官方文档与社区动态,提升AI系统复杂推理与协作能力。
参考资料:




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











