






摘要
本文深入探讨GraphRAG(Graph-based Retrieval Augmented Generation)技术的最新发展与应用实践。从2024年2月到12月,GraphRAG经历了从基础版本到1.0版本的完整演进,在检索质量、性能优化、用户体验等方面都取得了显著突破。文章将详细介绍GraphRAG的核心技术原理、架构演进、关键特性以及实践应用,为开发者提供全面的技术参考。
目录
1. 技术演进概述
1.1 发展历程
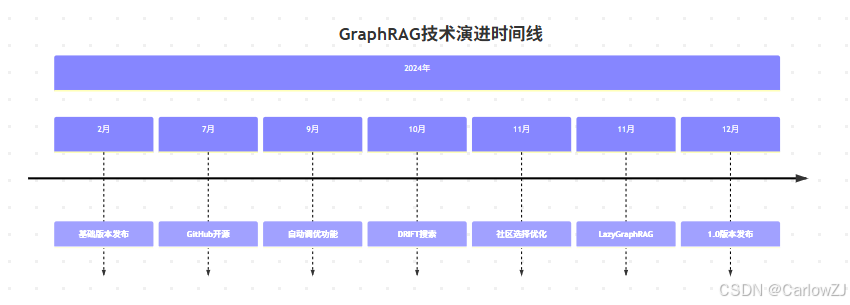
timeline
title GraphRAG技术演进时间线
section 2024年
2月 : 基础版本发布
7月 : GitHub开源
9月 : 自动调优功能
10月 : DRIFT搜索
11月 : 社区选择优化
11月 : LazyGraphRAG
12月 : 1.0版本发布
1.2 核心特性
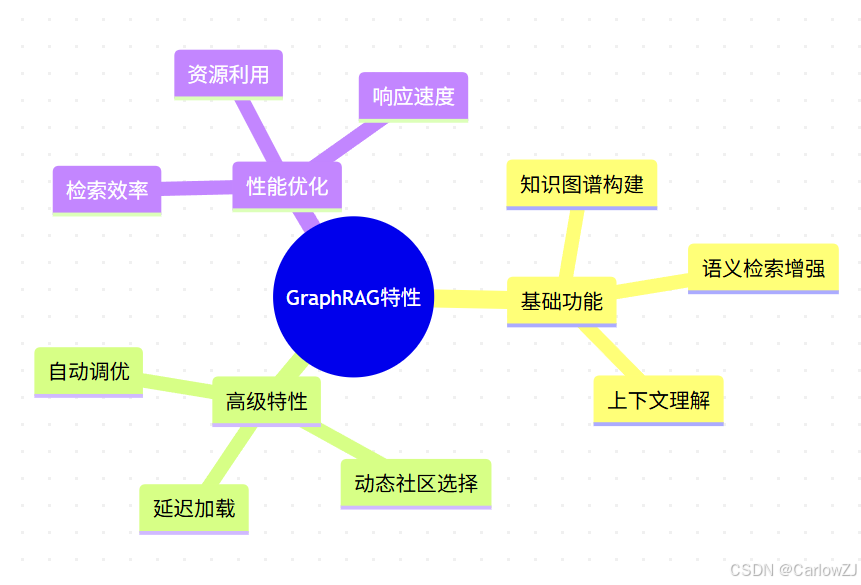
mindmap
root((GraphRAG特性))
基础功能
知识图谱构建
语义检索增强
上下文理解
高级特性
自动调优
动态社区选择
延迟加载
性能优化
检索效率
资源利用
响应速度
2. 核心架构设计
2.1 系统架构
2.2 数据流
3. 关键技术特性
3.1 自动调优
# 自动调优实现
def auto_tuning():
"""
自动调优功能实现
"""
class AutoTuner:
def __init__(self):
self.parameters = {
"community_threshold": 0.5,
"retrieval_depth": 3,
"context_window": 512
}
def optimize(self, performance_metrics):
"""
优化参数配置
"""
# 基于性能指标调整参数
for metric in performance_metrics:
self._adjust_parameters(metric)
def _adjust_parameters(self, metric):
"""
参数调整逻辑
"""
# 实现参数自动调整
pass
3.2 动态社区选择
# 社区选择实现
def community_selection():
"""
动态社区选择实现
"""
class CommunitySelector:
def __init__(self):
self.communities = {}
self.threshold = 0.5
def select_communities(self, query):
"""
选择相关社区
"""
# 计算查询与社区的相似度
similarities = self._calculate_similarities(query)
# 选择相关社区
selected = self._filter_communities(similarities)
return selected
def _calculate_similarities(self, query):
"""
计算相似度
"""
# 实现相似度计算
pass
4. 性能优化方案
4.1 优化策略
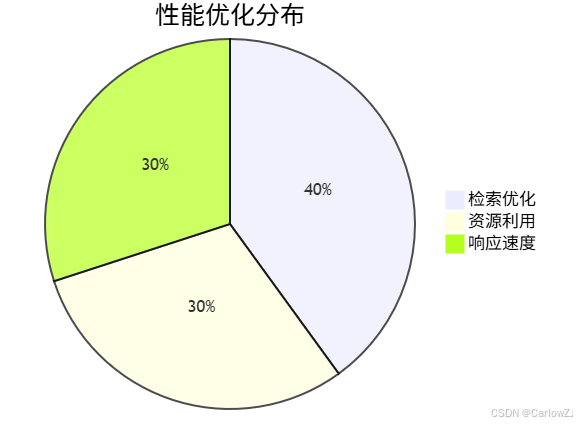
4.2 实现方案
# 性能优化实现
def performance_optimization():
"""
性能优化实现
"""
class PerformanceOptimizer:
def __init__(self):
self.cache = {}
self.metrics = {}
def optimize_retrieval(self):
"""
优化检索性能
"""
# 实现检索优化
pass
def optimize_resources(self):
"""
优化资源利用
"""
# 实现资源优化
pass
def optimize_response(self):
"""
优化响应速度
"""
# 实现响应优化
pass
5. 实践应用指南
5.1 实施计划
5.2 应用示例
# 应用示例
def application_example():
"""
应用示例实现
"""
class GraphRAGApplication:
def __init__(self):
self.graph = None
self.llm = None
def setup(self):
"""
系统设置
"""
# 初始化系统
self._init_graph()
self._init_llm()
def process_query(self, query):
"""
处理查询
"""
# 实现查询处理
pass
def _init_graph(self):
"""
初始化图谱
"""
# 实现图谱初始化
pass
def _init_llm(self):
"""
初始化语言模型
"""
# 实现模型初始化
pass
6. 最佳实践建议
6.1 实施建议
-
系统配置
- 合理设置参数
- 优化资源分配
- 监控系统性能
-
数据管理
- 定期更新数据
- 维护数据质量
- 优化存储结构
-
性能优化
- 使用缓存机制
- 优化检索策略
- 控制资源消耗
6.2 常见问题
-
检索质量
- 问题:检索结果不准确
- 解决:调整相似度阈值
- 建议:使用动态调整
-
性能问题
- 问题:响应速度慢
- 解决:优化检索策略
- 建议:使用缓存机制
-
资源消耗
- 问题:资源占用高
- 解决:优化存储结构
- 建议:使用延迟加载
7. 未来发展趋势
7.1 技术方向
7.2 发展重点
-
智能增强
- 自适应学习
- 智能调优
- 动态优化
-
性能提升
- 分布式处理
- 实时优化
- 资源管理
-
应用扩展
- 多场景支持
- 集成扩展
- 生态建设
8. 总结与展望
8.1 关键要点
-
技术优势
- 智能检索
- 性能优化
- 灵活扩展
-
应用价值
- 提升效率
- 降低成本
- 增强体验
-
发展方向
- 智能增强
- 性能优化
- 生态建设
8.2 未来展望
-
技术演进
- 智能增强
- 性能优化
- 生态建设
-
应用发展
- 场景扩展
- 集成深化
- 价值提升
参考资料
- GraphRAG: Unlocking LLM discovery on narrative private data
- GraphRAG: New tool for complex data discovery now on GitHub
- GraphRAG auto-tuning provides rapid adaptation to new domains
- Moving to GraphRAG 1.0 – Streamlining ergonomics for developers and users



















 367
367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











