



摘要
Apache Kafka 是一个分布式流处理平台,广泛应用于日志收集、消息队列、事件源驱动架构等场景。本文将从 Kafka 的基本概念入手,逐步深入到其核心组件的使用方法、应用场景、以及在实际开发中可能遇到的注意事项。通过代码示例和详细的架构图、流程图,帮助读者快速上手 Kafka 开发。同时,文章也会分享一些在使用 Kafka 过程中可能遇到的困难和挑战,以及如何应对这些问题。
一、Kafka 概述
(一)什么是 Kafka
Apache Kafka 是一个分布式流处理平台,最初由 LinkedIn 开发,后来成为 Apache 基金会的顶级项目。它具有高吞吐量、低延迟、可扩展性强等特点,适用于处理大规模数据流。
(二)Kafka 的核心概念
-
Topic(主题):消息的分类,生产者将消息发送到特定的 Topic,消费者从 Topic 中读取消息。
-
Partition(分区):为了提高可扩展性,一个 Topic 可以被划分为多个 Partition,每个 Partition 是一个有序的队列。
-
Broker(代理):Kafka 集群中的一个节点,负责存储消息和提供消息服务。
-
Producer(生产者):向 Kafka 发送消息的应用程序。
-
Consumer(消费者):从 Kafka 读取消息的应用程序。
-
Consumer Group(消费者组):一组消费者,它们共同消费一个 Topic 的消息。
(三)Kafka 的优势
-
高吞吐量:能够处理大量消息,适用于高并发场景。
-
低延迟:消息从生产者发送到消费者的时间非常短。
-
可扩展性:可以通过增加 Broker 节点来扩展集群。
-
容错性:支持数据的持久化和副本机制,确保消息不会丢失。
二、Kafka 核心组件详解
(一)Producer:生产者
生产者是向 Kafka 发送消息的应用程序。它可以通过 Kafka 提供的客户端库发送消息到指定的 Topic。
1. 代码示例
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("acks", "all");
props.put("retries", 0);
props.put("batch.size", 16384);
props.put("linger.ms", 1);
props.put("buffer.memory", 33554432);
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<>("my-topic", "key", "value"));
producer.close();
(二)Consumer:消费者
消费者是从 Kafka 读取消息的应用程序。它可以通过 Kafka 提供的客户端库订阅一个或多个 Topic,并从 Topic 中读取消息。
1. 代码示例
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "test");
props.put("enable.auto.commit", "true");
props.put("auto.commit.interval.ms", "1000");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
Consumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("my-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
}
(三)Broker:代理
Broker 是 Kafka 集群中的一个节点,负责存储消息和提供消息服务。一个 Kafka 集群可以包含多个 Broker。
(四)Partition:分区
Partition 是 Kafka 中的一个重要概念。一个 Topic 可以被划分为多个 Partition,每个 Partition 是一个有序的队列。Partition 的引入使得 Kafka 能够支持高吞吐量和高并发。
(五)Consumer Group:消费者组
消费者组是一组消费者,它们共同消费一个 Topic 的消息。每个消费者组中的消费者会分配到不同的 Partition,从而实现负载均衡。
三、Kafka 架构图与流程图
(一)架构图
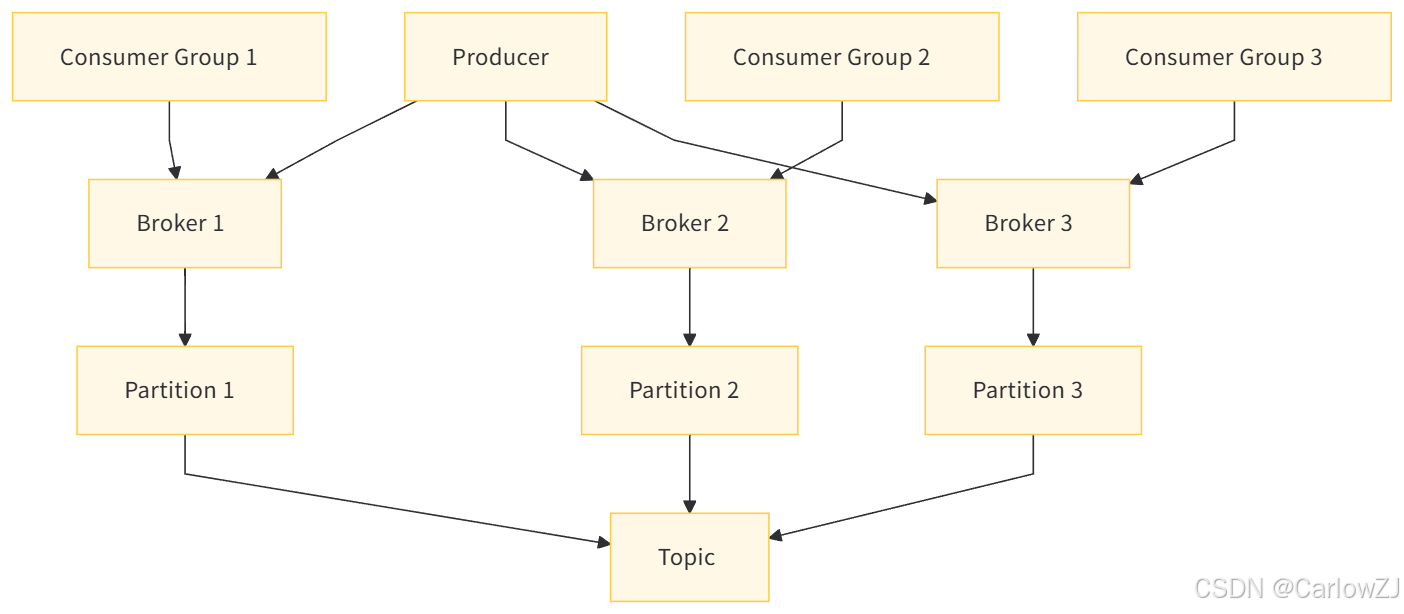
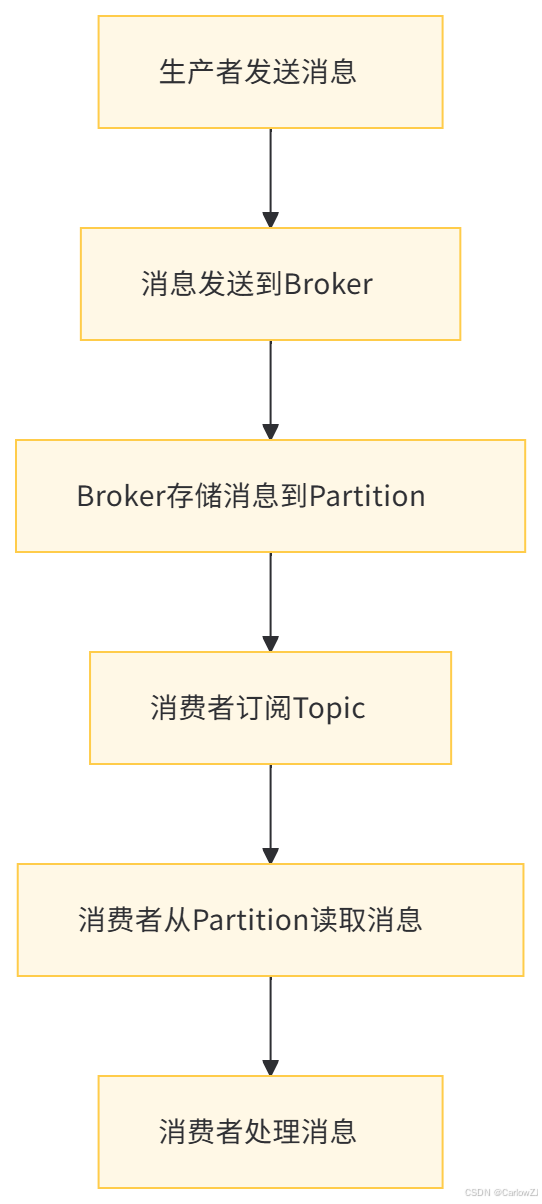
(二)流程图
四、Kafka 应用场景
(一)日志收集
Kafka 可以作为日志收集系统的核心组件,将不同来源的日志数据收集到 Kafka 中,然后进行后续的处理和分析。
(二)消息队列
Kafka 可以替代传统的消息队列系统,如 RabbitMQ、ActiveMQ 等。它具有更高的吞吐量和更好的性能。
(三)事件源驱动架构
Kafka 可以用于实现事件源驱动架构,将系统的状态变化以事件的形式存储到 Kafka 中,然后通过消费者处理这些事件。
(四)流处理
Kafka 可以与流处理框架(如 Apache Flink、Apache Spark Streaming)结合,实现对实时数据流的处理和分析。
五、Kafka 开发中的注意事项
(一)性能优化
-
合理设置 Partition 数量:Partition 数量过多或过少都会影响性能。
-
优化 Producer 和 Consumer 的配置:例如设置合理的
batch.size、linger.ms、fetch.size等参数。 -
使用批量发送:减少网络请求的次数,提高吞吐量。
(二)数据一致性
-
确保消息的顺序性:在同一个 Partition 中,消息是有序的,但跨 Partition 的消息顺序无法保证。
-
使用幂等性 Producer:避免消息重复发送导致的数据不一致。
(三)容错性
-
设置合理的副本数量:副本数量越多,容错性越好,但会增加存储成本。
-
监控 Broker 的状态:及时发现和处理 Broker 的故障。
(四)安全性
-
启用 SSL/TLS 加密:确保数据在传输过程中的安全性。
-
使用 SASL 认证:限制对 Kafka 集群的访问。
六、Kafka 数据流图
(一)数据流图
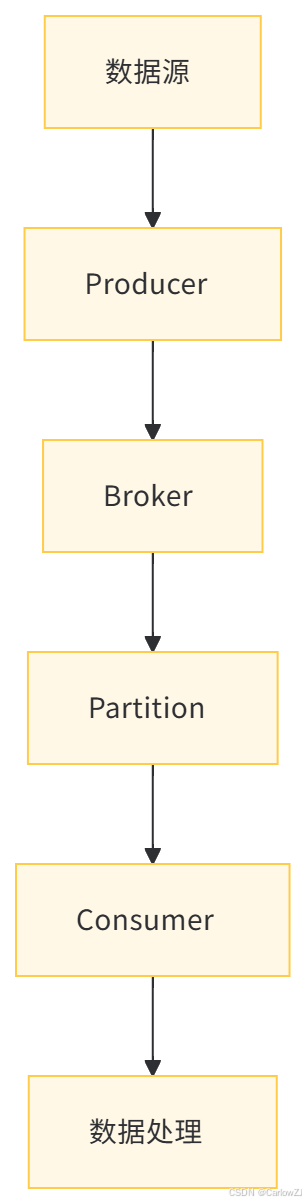
七、总结
Kafka 是一个强大的分布式流处理平台,适用于多种应用场景。通过本文的介绍,读者可以对 Kafka 的基本概念、核心组件、应用场景以及开发中的注意事项有一个全面的了解。虽然 Kafka 在实际使用中可能会遇到一些挑战,但只要合理规划和优化,它将为数据处理和消息传递带来极大的便利。



















 1355
1355

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











