



摘要
无监督微调是一种强大的技术,它结合了无监督学习的灵活性和微调的高效性,广泛应用于自然语言处理、计算机视觉等领域。本文将从无监督微调的基本概念出发,逐步深入到其实现细节、应用场景和优化技巧。通过详细的代码示例和架构图,读者将能够快速掌握无监督微调的核心思想,并将其应用于实际项目中。本文还总结了无监督微调的常见问题和注意事项,帮助读者避免常见的陷阱。
一、无监督微调的概念
(一)无监督学习与微调的结合
-
无监督学习:无监督学习是一种机器学习方法,它不依赖于标注数据,而是通过数据的内在结构来学习特征表示。常见的无监督学习方法包括聚类(如K-Means)、降维(如PCA)和自编码器等。
-
微调(Fine-tuning):微调是一种迁移学习技术,通常用于在预训练模型的基础上,针对特定任务进行优化。通过在少量标注数据上继续训练模型,可以使其更好地适应特定任务的需求。
-
无监督微调:无监督微调结合了无监督学习和微调的优点。它利用无监督学习来提取数据的通用特征表示,然后通过微调将这些特征应用于特定任务。这种方法在标注数据稀缺的情况下尤为有效。
(二)无监督微调的优势
-
减少标注数据的需求:标注数据的获取往往成本高昂且耗时。无监督微调可以利用大量未标注数据来学习通用特征,从而减少对标注数据的依赖。
-
提高模型的泛化能力:无监督学习能够捕捉数据的内在结构和分布,使模型在未见过的数据上表现更好。
-
适应性强:通过微调,模型可以快速适应不同的任务和领域,具有很强的灵活性。
二、无监督微调的实现
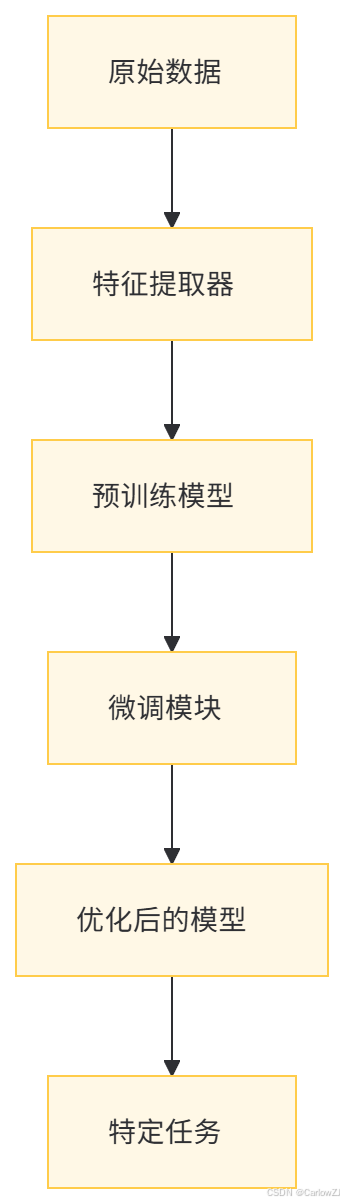
(一)架构设计
无监督微调的架构通常包括以下几个部分:
-
特征提取器:用于从原始数据中提取特征表示。可以使用自编码器、变分自编码器(VAE)或生成对抗网络(GAN)等无监督学习模型。
-
预训练模型:在无监督学习阶段训练好的模型,用于提供初始的特征表示。
-
微调模块:在少量标注数据上对预训练模型进行优化,使其适应特定任务。
(二)代码示例
以下是一个基于PyTorch的无监督微调实现示例:
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
# 定义自编码器
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(784, 256),
nn.ReLU(),
nn.Linear(256, 128),
nn.ReLU()
)
self.decoder = nn.Sequential(
nn.Linear(128, 256),
nn.ReLU(),
nn.Linear(256, 784),
nn.Sigmoid()
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return decoded
# 无监督预训练
def pretrain(model, dataloader, optimizer, criterion, epochs):
model.train()
for epoch in range(epochs):
for data in dataloader:
inputs, _ = data
inputs = inputs.view(inputs.size(0), -1)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, inputs)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item()}")
# 微调
def fine_tune(model, dataloader, optimizer, criterion, epochs):
model.train()
for epoch in range(epochs):
for inputs, labels in dataloader:
inputs = inputs.view(inputs.size(0), -1)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f"Epoch {epoch+1}, Loss: {loss.item()}")
# 加载数据
transform = transforms.Compose([transforms.ToTensor()])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
# 初始化模型和优化器
model = AutoEncoder()
optimizer = optim.Adam(model.parameters(), lr=0.001)
criterion = nn.MSELoss()
# 无监督预训练
pretrain(model, train_loader, optimizer, criterion, epochs=10)
# 微调(假设我们有一些标注数据)
# fine_tune(model, train_loader, optimizer, criterion, epochs=5)
(三)数据流图
以下是无监督微调的数据流图,使用Mermaid格式表示:
三、无监督微调的应用场景
(一)自然语言处理
-
文本分类:在文本分类任务中,无监督微调可以通过预训练语言模型(如BERT)提取文本的语义特征,然后在少量标注数据上进行微调,从而实现高效的文本分类。
-
情感分析:情感分析是自然语言处理中的一个重要任务。无监督微调可以利用大量未标注的文本数据来学习情感特征,然后通过微调来适应特定的情感分析任务。
(二)计算机视觉
-
图像分类:在图像分类任务中,无监督微调可以通过自编码器或GAN等模型提取图像的特征表示,然后在少量标注数据上进行微调,从而提高分类精度。
-
目标检测:目标检测任务需要检测图像中的目标对象并进行分类。无监督微调可以利用无监督学习提取图像的通用特征,然后通过微调来适应目标检测任务。
四、无监督微调的注意事项
(一)数据质量
-
数据清洗:在无监督学习阶段,数据的质量对模型的性能影响很大。需要对数据进行清洗,去除噪声和异常值。
-
数据增强:通过数据增强技术(如旋转、翻转、裁剪等)可以增加数据的多样性,提高模型的泛化能力。
(二)模型选择
-
选择合适的无监督学习模型:不同的无监督学习模型适用于不同的任务。例如,自编码器适用于特征提取,GAN适用于生成任务。
-
选择合适的微调策略:微调策略包括学习率调整、优化器选择等。需要根据具体任务选择合适的微调策略。
(三)过拟合问题
-
正则化技术:在微调阶段,容易出现过拟合问题。可以通过正则化技术(如Dropout、L2正则化等)来缓解过拟合。
-
早停机制:通过早停机制可以在模型开始过拟合之前停止训练,从而提高模型的泛化能力。
五、总结
无监督微调是一种结合了无监督学习和微调优点的技术,具有很强的灵活性和适应性。通过无监督学习提取通用特征,然后通过微调优化模型,可以在标注数据稀缺的情况下实现高效的模型训练。本文详细介绍了无监督微调的概念、实现方法、应用场景和注意事项,希望对读者有所帮助。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











