






目录
(五)代码示例:使用 cuDNN 的 TensorFlow 程序
六、案例分析:在 Windows 11 上搭建深度学习开发环境
在 Windows 11 上安装 CUDA 和 cuDNN 是许多 GPU 加速计算和深度学习任务的重要步骤。本文将详细介绍 CUDA 和 cuDNN 的概念,以及在 Windows 11 上安装它们的详细步骤,包括代码示例、应用场景和注意事项。
一、CUDA 和 cuDNN 的概念
(一)CUDA 的概念
CUDA(Compute Unified Device Architecture)是 NVIDIA 推出的一种并行计算平台和编程模型,它允许开发者利用 NVIDIA GPU 的强大计算能力来加速计算密集型任务。CUDA 提供了一系列的 API、工具和库,使开发者能够在 C、C++、Python 等编程语言中编写在 GPU 上运行的代码。
(二)cuDNN 的概念
cuDNN(CUDA Deep Neural Network library)是 NVIDIA 为深度学习应用提供的 GPU 加速库。它提供了许多用于深度学习的基本操作,如卷积、池化、归一化等,能够显著提高深度学习框架(如 TensorFlow、PyTorch)在 GPU 上的运行效率。
二、安装 CUDA
(一)检查显卡和驱动
在安装 CUDA 之前,需要确保你的显卡和驱动支持 CUDA。
-
按下 Win+R 键,输入
cmd,打开命令提示符。 -
输入以下命令,查看显卡信息和驱动版本:nvidia-smi
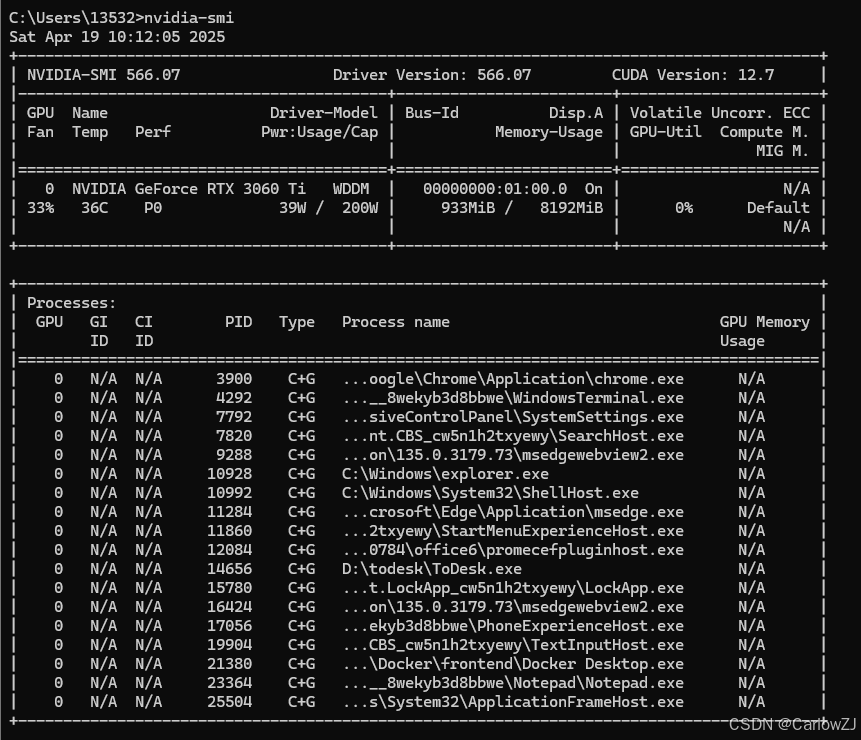
在命令行中运行`nvidia-smi`命令,查看显卡和驱动信息。其中,`CUDA Version`表示当前驱动支持的 CUDA 版本,如 12.5。如果该命令无法运行,说明显卡驱动未正确安装或显卡不支持 CUDA。此时需要更新显卡驱动或更换支持 CUDA 的显卡。
### (二)下载 CUDA Toolkit
根据显卡驱动支持的 CUDA 版本,选择合适的 CUDA Toolkit 版本进行下载。
访问 NVIDIA CUDA Toolkit Archive 页面,选择与驱动兼容的 CUDA 版本。例如,如果驱动支持 CUDA 12.5,则可以选择下载 CUDA Toolkit 12.5 或更低版本。点击对应的 CUDA Toolkit 版本,进入新页面,依次选择操作系统(Windows)、架构(x86_64)、平台(Windows)、版本(如 Windows 11)等信息,然后点击 Download 按钮下载 CUDA Toolkit。下载的安装包通常为`.exe`格式,如`cuda_12.5.0_551.85_windows.exe`。
### (三)安装 CUDA Toolkit
双击下载的 CUDA Toolkit 安装包,开始安装过程。
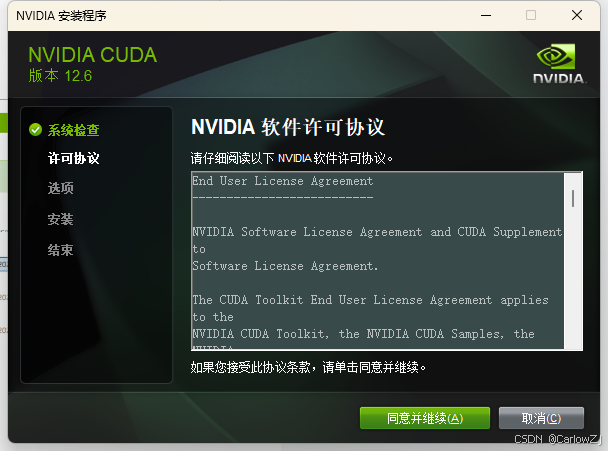
1. 点击 “同意并继续” 接受许可协议。
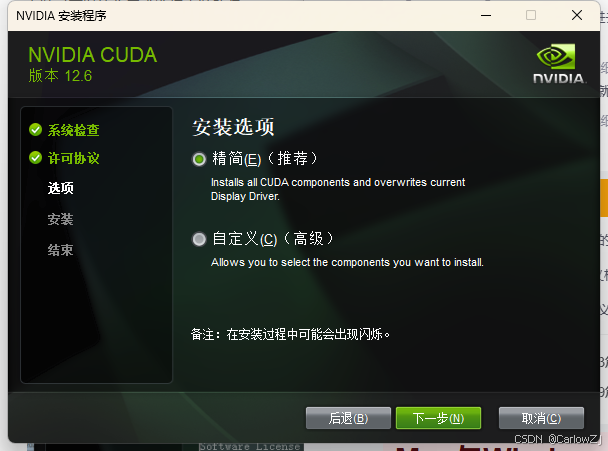
2. 选择 “自定义” 安装类型,点击 “下一步”。
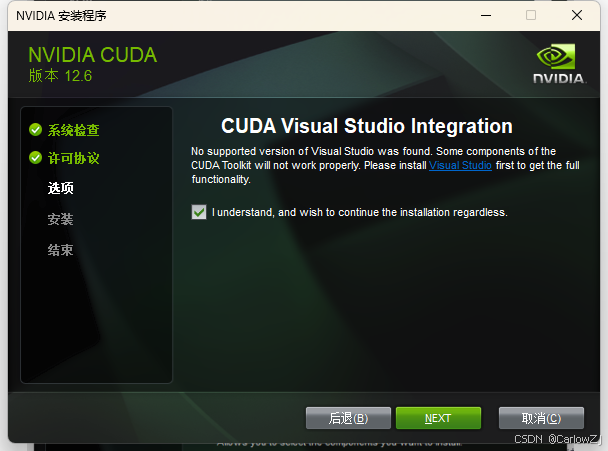
3. 在安装组件选择界面,勾选 “CUDA” 组件,取消勾选 “Visual Studio Integration”(除非已安装 Visual Studio 且需要集成 CUDA 工具链)。
4. 点击 “Driver components”,取消勾选 “Display Driver” 和 “HD Audio”,避免因驱动版本不匹配导致的兼容性问题。
5. 点击 “下一步”,选择安装路径。建议安装到非系统盘以节省系统盘空间。例如,选择`D:\CUDA\v12.5`作为安装目录。
6. 点击 “安装” 开始安装 CUDA Toolkit。安装过程可能需要几分钟时间,请耐心等待。
### (四)验证 CUDA 安装
安装完成后,需要验证 CUDA 是否安装成功。
1. 重启计算机,确保所有环境变量更新生效。
2. 按下 Win+R 键,输入`cmd`,打开命令提示符。
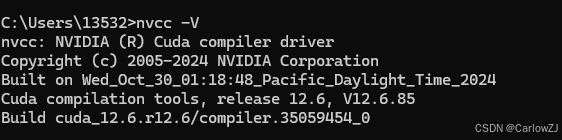
3. 输入以下命令,查看 CUDA 编译器版本:
```bash
nvcc -V如果命令行输出了 CUDA 编译器的版本信息,如nvcc: NVIDIA (R) Cuda compiler driver和built on Wed_Oct_18_17:08:58_2023等信息,则表示 CUDA 安装成功。例如:
nvcc: NVIDIA (R) Cuda compiler driver
Built on Wed_Oct_18_17:08:58_2023
Cuda compilation tools, release 12.5, V12.5.65(五)CUDA 安装异常处理
如果在验证时发现nvcc -V命令无法识别或输出错误,可以尝试以下解决方法:
-
检查环境变量是否正确配置。确保 CUDA 的
bin和include目录已添加到系统环境变量PATH中。例如,对于安装在D:\CUDA\v12.5的 CUDA,应将D:\CUDA\v12.5\bin和D:\CUDA\v12.5\include添加到PATH。 -
手动添加环境变量。打开 “控制面板”,选择 “系统和安全” > “系统” > “高级系统设置”,点击 “环境变量” 按钮,在 “系统变量” 下找到
Path变量,点击 “编辑”,将 CUDA 的bin和include目录路径添加到列表中,点击 “确定” 保存设置。 -
检查 CUDA 安装路径下的
bin目录是否存在nvcc.exe文件。如果该文件不存在或损坏,可能需要重新安装 CUDA Toolkit。
(六)运行 CUDA 示例程序
除了使用nvcc -V命令验证 CUDA 安装外,还可以运行 CUDA 提供的示例程序来进一步确认安装是否成功。
-
打开命令提示符,进入 CUDA 安装目录下的
extras\demo_suite目录。例如:
cd D:\CUDA\v12.5\extras\demo_suite
2. 运行以下命令,测试 GPU 的性能和功能:
```bash
.\bandwidthTest.exe.\deviceQuery.exe
如果两个示例程序均输出`Result = PASS`,则表示 CUDA 安装成功且 GPU 可正常工作[^70^]。
### (七)安装 CUDA 驱动程序
如果在安装 CUDA Toolkit 时未安装显卡驱动程序,或者需要更新显卡驱动以获得更好的性能和兼容性,可以手动安装 CUDA 驱动程序。
访问 NVIDIA 官方驱动下载页面,选择与显卡型号和操作系统匹配的驱动程序版本。例如,对于 NVIDIA GeForce RTX 3080 和 Windows 11 系统,选择相应的驱动程序版本,下载并运行安装程序,按照提示完成安装。安装完成后,重启计算机以使驱动程序生效。
### (八)配置 Visual Studio 集成(可选)
如果需要在 Visual Studio 中进行 CUDA 编程,可以配置 Visual Studio 集成。
1. 打开 Visual Studio,选择 “工具” > “扩展和更新”。
2. 在扩展商店中搜索 “NVIDIA CUDA” 相关的扩展,如 “NVIDIA CUDA Toolkit” 或 “CUDA for Visual Studio”,下载并安装。
3. 安装完成后,重启 Visual Studio,创建一个新的 CUDA 项目或打开现有的 CUDA 项目进行开发[^70^]。
### (九)代码示例:CUDA 程序
以下是一个简单的 CUDA 程序示例,计算两个数组的加法运算:
```cpp
#include <stdio.h>
__global__ void addArrays(int *a, int *b, int *c, int n) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
if (index < n) {
c[index] = a[index] + b[index];
}
}
int main() {
const int arraySize = 1024;
int a[arraySize], b[arraySize], c[arraySize];
int *d_a, *d_b, *d_c;
// 初始化数组
for (int i = 0; i < arraySize; ++i) {
a[i] = i;
b[i] = i * 2;
}
// 分配 GPU 内存
cudaMalloc((void**)&d_a, arraySize * sizeof(int));
cudaMalloc((void**)&d_b, arraySize * sizeof(int));
cudaMalloc((void**)&d_c, arraySize * sizeof(int));
// 将数据从 CPU 传输到 GPU
cudaMemcpy(d_a, a, arraySize * sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(d_b, b, arraySize * sizeof(int), cudaMemcpyHostToDevice);
// 执行 GPU 加法运算
int blockSize = 256;
int gridSize = (arraySize + blockSize - 1) / blockSize;
addArrays<<<gridSize, blockSize>>>(d_a, d_b, d_c, arraySize);
// 将结果从 GPU 传输回 CPU
cudaMemcpy(c, d_c, arraySize * sizeof(int), cudaMemcpyDeviceToHost);
// 验证结果
for (int i = 0; i < arraySize; ++i) {
if (c[i] != 3 * i) {
printf("Error at index %d: %d != %d\n", i, c[i], 3 * i);
return 1;
}
}
printf("All elements computed correctly.\n");
// 释放 GPU 内存
cudaFree(d_a);
cudaFree(d_b);
cudaFree(d_c);
return 0;
}将上述代码保存为add.cu文件,使用 CUDA 编译器nvcc进行编译:
nvcc -o add add.cu运行生成的可执行文件add.exe,如果输出“All elements computed correctly.”,则表示程序运行成功,CUDA 环境配置正确。
三、安装 cuDNN
(一)注册 NVIDIA 账户
下载 cuDNN 需要 NVIDIA 账户,如果没有,需要先注册。
访问 NVIDIA 官方注册页面,输入有效的邮箱地址、设置密码等信息,完成注册流程。注册完成后,登录 NVIDIA 开发者门户。
(二)下载 cuDNN
根据已安装的 CUDA 版本,选择对应的 cuDNN 版本进行下载。
访问 cuDNN Archive 页面,选择与 CUDA 版本匹配的 cuDNN 版本。例如,如果已安装 CUDA 12.5,则选择 cuDNN 版本为 CUDA 12.x。点击对应的 cuDNN 版本,选择适用于 Windows 系统的安装包格式,如图形化安装程序(.exe)或压缩包(.zip),然后下载安装包。
(三)安装 cuDNN
下载完成后,根据安装包类型进行安装。
1. 图形化安装
-
双击下载的 cuDNN 安装程序,如
cudnn-windows-x86_64-9.5.0.50_cuda12-archive.exe。 -
运行安装程序,按照图形界面提示进行操作。在安装过程中,选择对应的 CUDA 版本(如 CUDA 12.5),cuDNN 将自动安装到相应的目录下。
2. 压缩包安装
-
解压下载的 cuDNN 压缩包,如
cudnn-windows-x86_64-9.5.0.50_cuda12-archive.zip。 -
将解压后的
bin、include和lib目录中的文件复制到 CUDA 安装目录下对应的目录中。例如,对于默认安装路径C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.5,将:-
bin\cudnn*.dll复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.5\bin -
include\cudnn*.h复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.5\include -
lib\x64\cudnn*.lib复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.5\lib\x64
-
-
添加环境变量。打开 “控制面板”,选择 “系统和安全” > “系统” > “高级系统设置”,点击 “环境变量” 按钮。在 “系统变量” 下找到
Path变量,点击 “编辑”,将C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.5\bin添加到列表中,点击 “确定” 保存设置。同时,可以将C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.5\include和C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.5\lib\x64也添加到Path环境变量中,以便在开发环境中方便地使用 cuDNN 库。
(四)验证 cuDNN 安装
验证 cuDNN 是否安装成功,可以通过运行 CUDA 示例程序或使用深度学习框架进行测试。
-
在 Python 环境中安装深度学习框架,如 TensorFlow 或 PyTorch。以 TensorFlow 为例,运行以下命令安装 TensorFlow GPU 版本:
pip install tensorflow-gpu
2. 运行以下 Python 代码,检查 TensorFlow 是否能够检测到 GPU 并使用 cuDNN:
```python
import tensorflow as tf
print("TensorFlow version:", tf.__version__)
print("Is GPU available:", tf.config.list_physical_devices('GPU'))如果输出显示 GPU 可用,并且 TensorFlow 能够成功利用 GPU 加速计算,则表示 cuDNN 安装成功。
(五)代码示例:使用 cuDNN 的 TensorFlow 程序
以下是一个使用 cuDNN 的 TensorFlow 程序示例,构建并训练一个简单的卷积神经网络(CNN)用于图像分类:
import tensorflow as tf
from tensorflow.keras.datasets import cifar10
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Dense, Flatten
# 加载 CIFAR-10 数据集
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 数据预处理
x_train, x_test = x_train / 255.0, x_test / 255.0
y_train, y_test = tf.keras.utils.to_categorical(y_train, 10), tf.keras.utils.to_categorical(y_test, 10)
# 构建 CNN 模型
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(32, 32, 3)),
MaxPooling2D((2, 2)),
Conv2D(64, (3, 3), activation='relu'),
MaxPooling2D((2, 2)),
Flatten(),
Dense(64, activation='relu'),
Dense(10, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, epochs=10, validation_data=(x_test, y_test))
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test)
print('Test accuracy:', test_acc)运行上述代码,如果 TensorFlow 能够利用 GPU 加速训练过程,并且模型能够正常收敛,达到较高的测试准确率,则说明 cuDNN 安装成功,GPU 加速功能正常工作。
四、应用场景
(一)深度学习框架加速
-
TensorFlow 和 PyTorch 等主流深度学习框架都支持 CUDA 和 cuDNN。通过安装 CUDA 和 cuDNN,可以显著加速模型的训练和推理过程。例如,在训练卷积神经网络(CNN)进行图像分类任务时,利用 GPU 加速可以将训练时间从数小时缩短到数分钟,极大提高了研究和开发效率。
-
在自然语言处理(NLP)领域,使用 GPU 加速的深度学习模型(如 Transformer)可以更快地处理大规模文本数据,提高机器翻译、文本生成等任务的性能和效率。
(二)计算机视觉与图像处理
-
在计算机视觉任务中,如目标检测、图像分割等,CUDA 和 cuDNN 提供的 GPU 加速能力使得实时处理高清视频流成为可能。例如,在安防监控系统中,利用 GPU 加速的目标检测模型可以实时识别视频中的物体和行为,提高监控系统的响应速度和准确性。
-
医学图像分析领域,研究人员可以利用 CUDA 和 cuDNN 加速的深度学习算法进行医学图像的诊断和分析,如肿瘤检测、器官分割等,为医疗诊断提供更高效、准确的辅助工具。
(三)高性能计算与科学计算
-
CUDA 和 cuDNN 在高性能计算(HPC)领域有广泛应用,如物理模拟、气象预测、分子动力学模拟等。这些领域通常需要处理大规模的数值计算,GPU 的并行计算能力可以显著加速计算过程,提高研究效率和成果产出。
-
在科学计算中,如线性代数计算、偏微分方程求解等,CUDA 提供的并行计算库(如 cuBLAS、cuSPARSE)和 cuDNN 提供的深度学习原语可以优化计算性能,为科学研究提供更强大的计算支持。
(四)游戏开发与图形渲染
-
游戏开发者可以利用 CUDA 和 cuDNN 进行游戏物理引擎的加速,如碰撞检测、粒子系统模拟等,提高游戏的物理真实感和运行流畅度。
-
在图形渲染方面,CUDA 可以加速光线追踪、阴影计算等复杂图形算法,为游戏和影视特效制作提供更高质量的视觉效果。
五、注意事项
(一)兼容性问题
-
确保显卡驱动与 CUDA 版本兼容。可以通过运行
nvidia-smi命令查看当前驱动支持的 CUDA 版本,选择低于或等于该版本的 CUDA Toolkit 进行安装。 -
cuDNN 版本必须与 CUDA 版本匹配。在下载 cuDNN 时,务必选择与已安装 CUDA 版本对应的 cuDNN 版本,否则可能导致运行时错误或性能问题。
(二)环境变量配置
-
正确配置 CUDA 和 cuDNN 的环境变量是确保其正常工作的关键。在安装完成后,检查
PATH环境变量是否包含 CUDA 的bin目录和 cuDNN 的bin目录。如果未正确配置,可能导致命令行无法识别nvcc或其他 CUDA 工具,或者深度学习框架无法找到 cuDNN 库。 -
对于开发环境(如 Visual Studio 或 Python),可能还需要在项目设置或环境配置中指定 CUDA 和 cuDNN 的包含目录(
include)和库目录(lib),以便编译器和链接器能够正确找到所需的头文件和库文件。
(三)安装路径选择
-
建议将 CUDA 和 cuDNN 安装到非系统盘,以避免系统盘空间不足导致的安装失败或系统运行缓慢。同时,尽量避免安装路径中包含空格或特殊字符,以免在编译或运行过程中引发路径相关的问题。
(四)更新与回滚
-
在更新 CUDA 或 cuDNN 版本时,建议先备份旧版本的安装目录和相关数据。如果新版本出现兼容性问题或性能问题,可以及时回滚到旧版本以恢复系统的稳定性和正常运行。
-
如果需要卸载 CUDA,可以直接通过控制面板中的 “程序和功能” 选项卸载 CUDA Toolkit。卸载完成后,手动删除相关的环境变量设置和残留文件夹,确保系统清洁。
(五)资源监控与管理
-
在运行 GPU 加速的应用程序时,监控 GPU 的资源使用情况(如显存占用、计算资源利用率等)是确保系统稳定运行的重要措施。可以使用 NVIDIA 提供的工具(如
nvidia-smi命令)或第三方监控软件来实时查看 GPU 的状态,合理分配资源,避免因资源不足导致的应用程序崩溃或系统卡顿。 -
对于长时间运行的深度学习任务或高性能计算任务,合理设置任务的优先级和资源限制,避免单个任务占用过多的 GPU 资源,影响其他任务的执行或系统的正常响应。
六、案例分析:在 Windows 11 上搭建深度学习开发环境
(一)需求分析
一位深度学习开发者需要在 Windows 11 电脑上搭建一个深度学习开发环境,用于训练和部署基于 TensorFlow 的图像分类模型。电脑配备了支持 CUDA 的 NVIDIA GeForce RTX 3080 显卡,要求能够充分利用 GPU 加速计算,提高模型训练效率。
(二)环境搭建步骤
-
检查显卡和驱动 :按下 Win+R 键,输入
cmd,打开命令提示符。运行nvidia-smi命令,查看显卡型号和驱动支持的 CUDA 版本。结果显示显卡为 NVIDIA GeForce RTX 3080,驱动支持的 CUDA 版本为 12.5。 -
安装 CUDA Toolkit :访问 NVIDIA CUDA Toolkit Archive 页面,选择 CUDA Toolkit 12.5 版本进行下载。下载完成后,运行安装程序,选择 “自定义” 安装类型,取消勾选 “Visual Studio Integration” 和 “Driver components” 中的 “Display Driver” 和 “HD Audio”。将安装路径设置为
D:\CUDA\v12.5,完成安装。 -
验证 CUDA 安装 :重启计算机后,打开命令提示符,运行
nvcc -V命令,验证 CUDA 是否安装成功。输出显示 CUDA 版本为 12.5,说明安装成功。进一步运行 CUDA 示例程序bandwidthTest.exe和deviceQuery.exe,均输出Result = PASS,确认 GPU 功能正常。 -
注册 NVIDIA 账户并下载 cuDNN :访问 NVIDIA 官网注册账户,完成邮箱验证后,登录开发者门户。进入 cuDNN Archive 页面,选择与 CUDA 12.5 版本匹配的 cuDNN 9.5.0 版本进行下载。
-
安装 cuDNN :下载 cuDNN 压缩包后,解压文件,将
bin、include和lib目录中的文件复制到D:\CUDA\v12.5对应的目录中。打开 “环境变量” 设置,将D:\CUDA\v12.5\bin添加到Path环境变量中。 -
安装深度学习框架和相关工具 :在 Python 环境中,使用
pip命令安装 TensorFlow GPU 版本:
pip install tensorflow-gpu
同时,安装其他必要的工具和库,如`numpy`、`matplotlib`等:
```bash
pip install numpy matplotlib(三)应用效果
通过在 Windows 11 上搭建深度学习开发环境,开发者能够充分利用 NVIDIA GeForce RTX 3080 显卡的计算能力,加速 TensorFlow 模型的训练过程。与仅使用 CPU 训练相比,GPU 加速使模型训练时间大幅缩短,提高了开发效率。同时,cuDNN 的优化功能确保了深度学习操作的高效执行,模型在图像分类任务中表现出较高的准确率和稳定性能。该开发环境为开发者进行深度学习研究和应用开发提供了强大的支持,使得复杂的模型训练和实验能够在更短的时间内完成,加速了项目的进展和创新。
七、总结与展望
在 Windows 11 上安装 CUDA 和 cuDNN 是利用 NVIDIA GPU 进行加速计算和深度学习开发的关键步骤。通过本文的详细讲解,读者可以全面了解 CUDA 和 cuDNN 的概念、安装方法、配置步骤、应用场景以及注意事项。无论是在深度学习框架加速、计算机视觉、高性能计算还是游戏开发等领域,CUDA 和 cuDNN 都能够提供强大的计算支持,帮助开发者提高工作效率和应用性能。
随着深度学习和 GPU 计算技术的不断发展,CUDA 和 cuDNN 将持续优化和进化。未来,我们可以期待以下方面的改进和拓展:
-
性能提升 :NVIDIA 将不断优化 CUDA 和 cuDNN 的底层算法和架构,提高 GPU 的计算效率和能效比。新的 GPU 架构和计算技术将为深度学习和高性能计算带来更高的性能突破。
-
易用性增强 :CUDA 和 cuDNN 的安装和配置过程将进一步简化,降低使用门槛。更多的自动化工具和集成开发环境(IDE)支持将使开发者能够更轻松地利用 GPU 加速功能,减少配置和调试的时间成本。
-
功能扩展 :cuDNN 将增加对更多深度学习操作和模型架构的支持,满足不断发展的研究和应用需求。同时,CUDA 将进一步加强与其他 NVIDIA 技术(如 RTX 实时光线追踪、AI 加速渲染等)的融合,为开发者提供更丰富的功能和更强大的创造力。
-
跨平台兼容性 :虽然 CUDA 主要面向 NVIDIA GPU,但随着异构计算的发展,CUDA 和 cuDNN 将在跨平台兼容性和互操作性方面取得进展。更好的支持多 GPU 平台、云环境和边缘设备,将使开发者能够更灵活地部署和扩展深度学习应用。
通过掌握 CUDA 和 cuDNN 的安装与应用,开发者可以在 Windows 11 系统上充分利用 NVIDIA GPU 的强大计算能力,推动深度学习和高性能计算项目的发展。无论是进行前沿的学术研究还是开发创新的商业应用,CUDA 和 cuDNN 都将成为不可或缺的工具,助力开发者在人工智能和计算科学领域取得更大的成就。
另:
1.
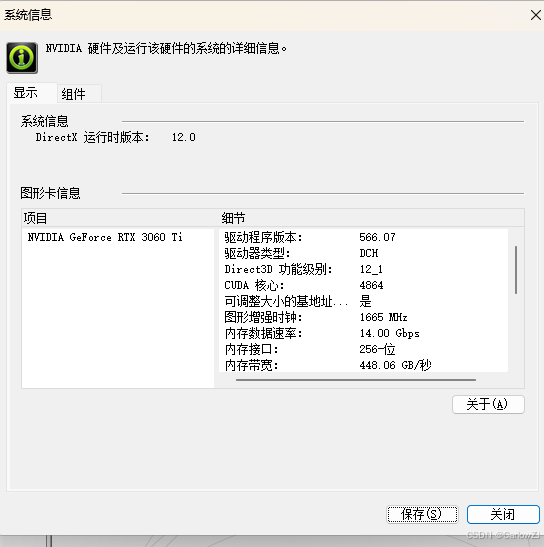
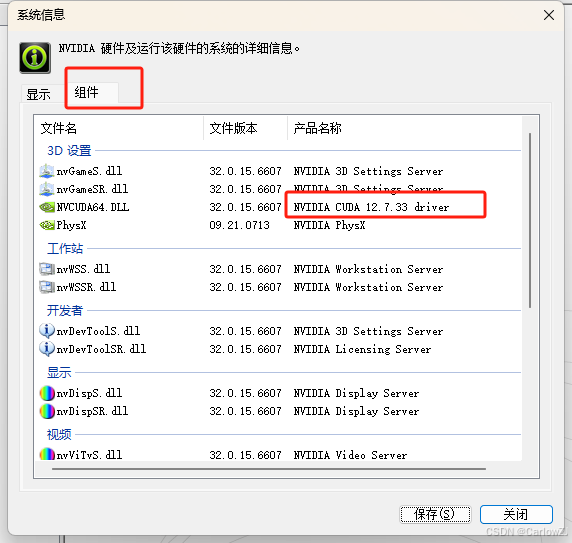
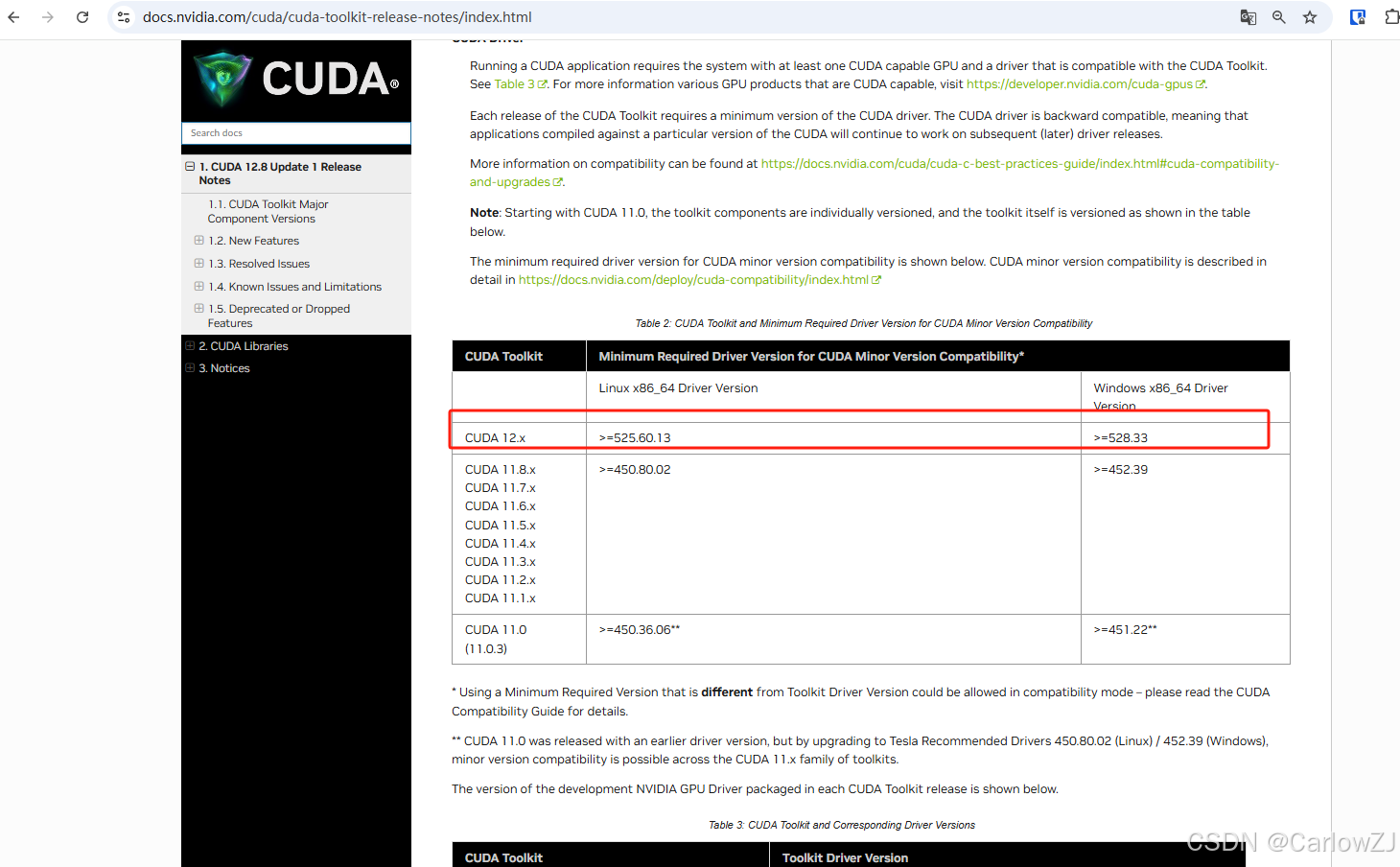
按照自己电脑配置查看对应的cuda版本:1. CUDA 12.8 Update 1 Release Notes — Release Notes 12.8 documentation
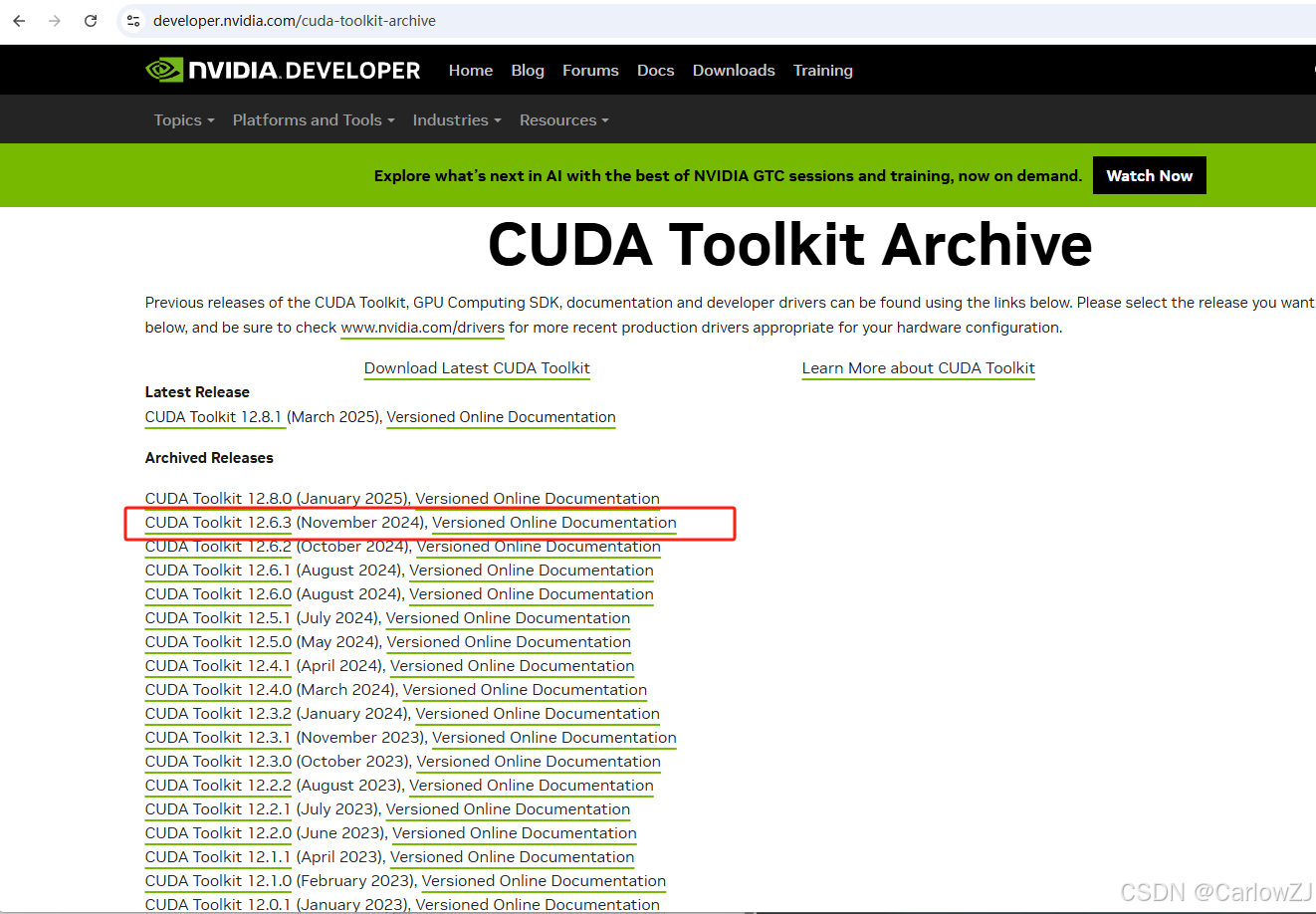
下载cuda:CUDA Toolkit Archive | NVIDIA Developer
版本不能高于你的配置的版本,比如:我的是12.7,那么我就选择12.7以下版本
文件较大,准备足够多的内存
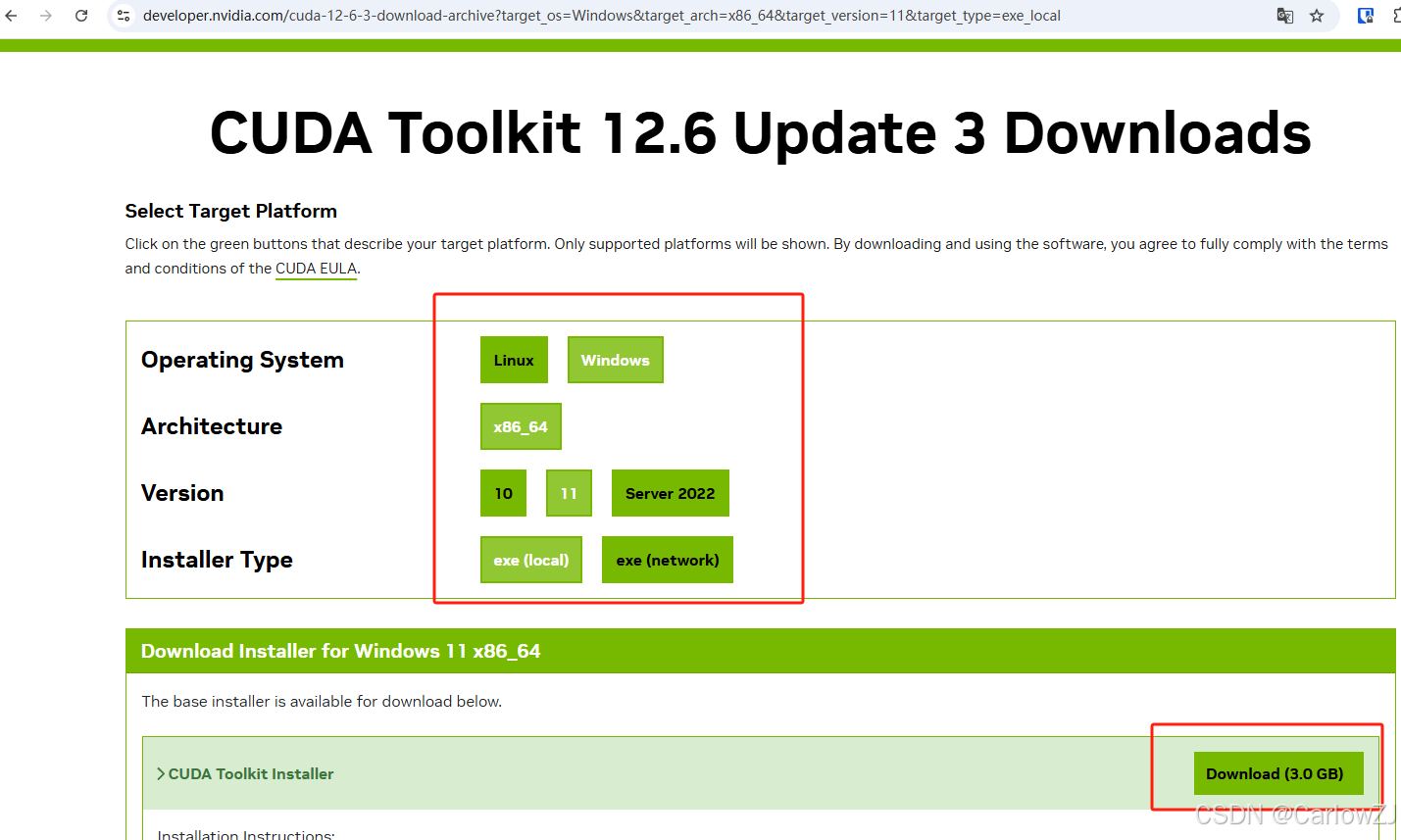

安装时可以按你需求选择安装路径



















 1221
1221

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











