




一、请求
前一章节(点击超链接跳转) 已经描述过 爬虫响应的原理 和 怎么通过抓包获取第二次请求后得到的网址,接下来进一步了解请求信息和进行实操:
1 请求行:
会附带的三种信息 —— 请求地址(url)协议(http) 请求方法(get/post)

2 请求头:
需要放到服务器上,或者服务器需要的数据,爬虫需要着重了解的地方(headers、cooki、User-Agent,又叫ua数据)
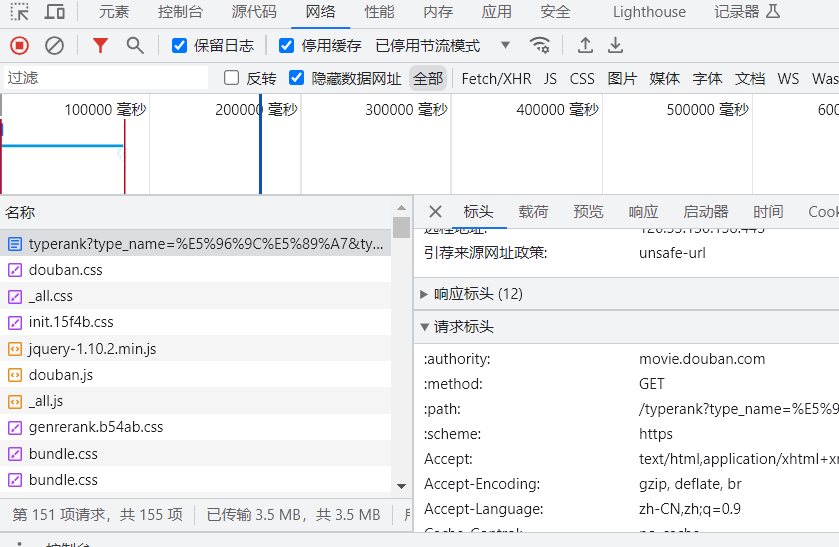
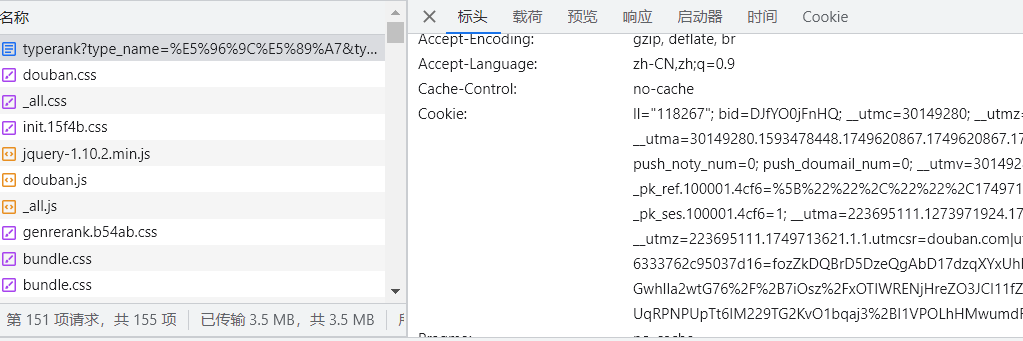
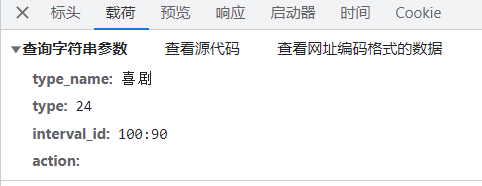
3 请求体:
放置一些参数。标头的请求网址里面的数据也对应着载荷里面的内容,比如下方这个请求网址:
https://movie.douban.com/typerank?**type_name**=%E5%96%9C%E5%89%A7&**type**=24&**interval_id**=100:90&**action**=
二、响应
1 状态行:
包括 协议 和 状态码 ,了解是否请求成功了,状态码(一般是200,123开头都可以)OK即成功,状态码400/500/404(45开头请求失败)是请求失败了。

2 响应头:
放到客户端上面要使用的信息
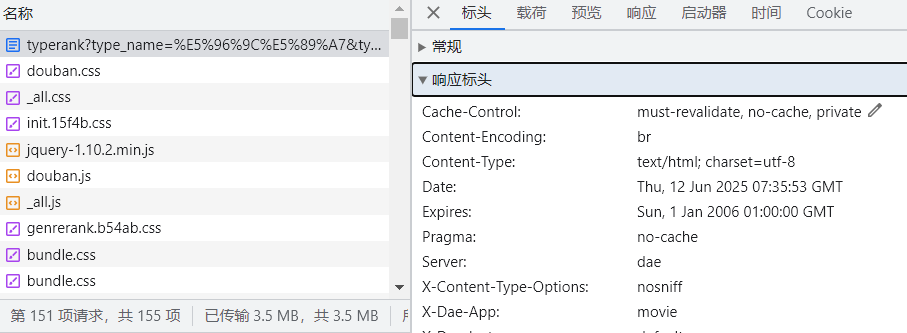
3 响应体:
返回的具体的数据,如html的页面(网页源代码)
三、普通爬虫获取的操作思路(requests库)
先安装好requests库,以豆瓣电影网页为例:
1、抓包
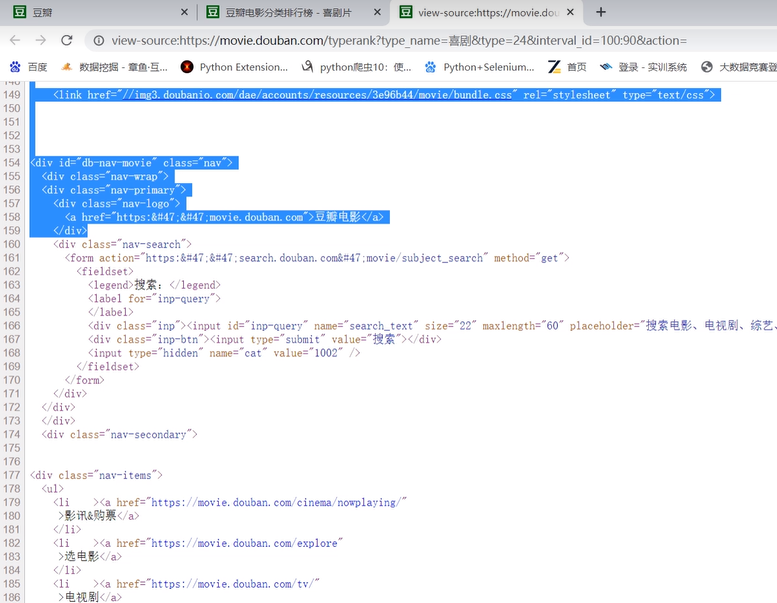
F12点击网络进行抓包,才能对数据进行分析。找到chart文档,了解请求方法。有没有人会不清楚为什么是找chart文档?原因如下:
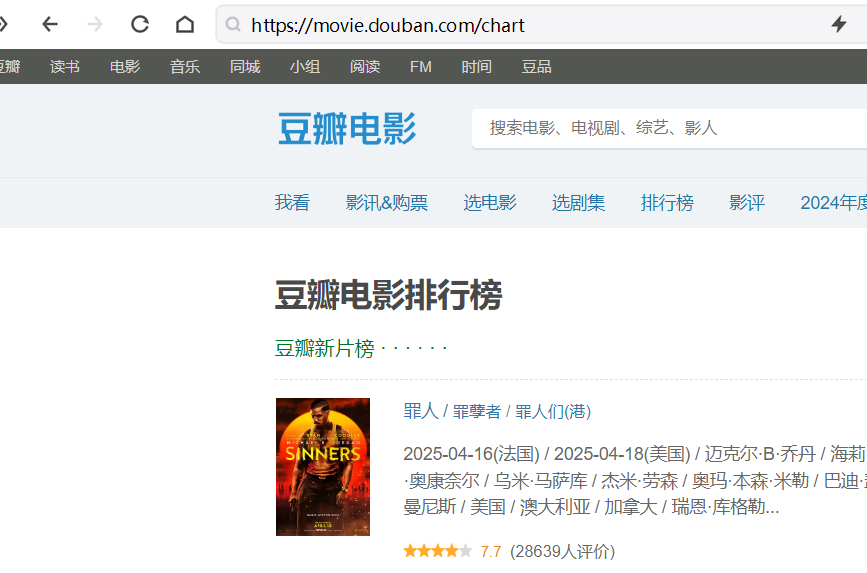
看排行榜页面的网址,“https://movie.douban.com/chart
” 对应的文档就是chart

2、请求响应
编写一段请求代码,收到的响应结果是418,4开头的状态码表示请求失败
import requests
url='https://movie.douban.com/chart' #请求的对象
html=requests.get(url)
print(html)
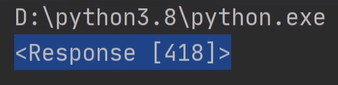
失败的原因是?被识别成爬虫了,网址的反爬机制。 请求头一定要有且是伪装好的
import requests
url='https://movie.douban.com/chart' #请求的对象
html=requests.get(url)
#被网站识别出爬虫了,先获取我们的headers看看
print(html.request.headers)
先获取一下自己的headers,发现我们自己在请求时,就写明了我们是爬虫程序 ‘User-Agent’: ‘python-requests/2.28.1’ ,所以我们需要修改请求头数据。
注意修改格式保持一致,都是字典类型。 ‘User-Agent’: 'XXX‘
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
UA伪装:
找到网页里【请求头】里面的【User-Agent】对应的数据,然后创建一个新的headers,数据是字典类型
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36"
} #字典类型
html=requests.get(url,headers=headers)
补充:request里面还有很多参数(按住ctrl键点击函数名称就可以看到封装好的函数的内容了),这次要加上的是headers
import requests
url='https://movie.douban.com/chart' #请求的对象
headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit........'}
html=requests.get(url,headers=headers)
#被网站识别出爬虫了,先获取headers
#print(html.request.headers)
print(html)
得到的结果是<Response [200]>,服务器回复浏览器成功!

碎碎念一句,之后不论网页是否设置反爬机制,最好都把headers写好,养成好习惯
四、爬取豆瓣图片操作步骤(代码)
下面尝试爬取一张豆瓣的图片并保存在本地,在网站上 F12 随便定位到一张图片,找到src,获取图片的链接

想要保存到本地,open方法一定写好【保存的图片名】 和 【写入的方式】(通常为w,但这里存图片,用request.content,数据是二进制字节加个b —— wb)
import requests
response = requests.get('https://img2.doubanio.com/view/photo/s_ratio_poster/public/p2920268831.webp')
# print(response.status_code) #测试状态码无误 是200
# print(response.content) #获取到是图片的二进制形式
#保存到本地
with open('罪人.png','wb') as f:# 写好保存的图片名 和 写入的方式(通常为w,但这里是二进制字节加个b)
f.write(response.content)
运行一下代码,现在本地文件夹里面已经有我们爬下来的图片了。



















 2025
2025

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









