




数据的来源:
1、企业生产的用户数据
2、数据管理咨询公司
3、政府/机构提供的公开的数据
4、第三方数据平台购买数据
5、爬虫爬取数据
1.什么是爬虫?
简单来说,爬虫是模拟人去网络上获取数据的一个程序,抓取网页上的数据
2.爬虫的作用
自动化操作,无需人去手工操作,比如下载文件
精确快速获取网页数据
爬取资源,如视频,音频,文件等
对爬取数据做分析
3.爬虫的价值和合法性
价值:降低了获取数据的成本,比人工快,开发效率高
合法性:爬虫的技术在法律上是不被禁止的,但也具有一定的违法风险,有利有弊,辩证看待,正确使用。爬取过程不影响网站的正常使用,不去窃取别人网站的隐私,当不小心获取的时候要及时终止
4.爬虫怎么抓取网页上的数据:
网页三大特征:
- 网页有唯一URL
- 网页是HTML描述页面信息
- 网页都使用HTTP/HTTPS协议传输HTML数据
爬虫设计思路:
- 确定URL
- 通过HTTP/HTTPS协议获取对应的HTML页面
- 提取页面有用的数据
注意:如果是iframe框架的登录接口,是嵌套在网页上的,src可以调整到对应登录的地方,想直接单独访问那个url会访问不到,因为没有登录
5.爬虫的分类
-
普通爬虫(通用爬虫):
通常指 “ 搜索引擎 ” 的爬虫,获取整个页面的数据目的:尽可能把互联网上所有的网页下载下来,放到本地服务器里形成备份,再对这些网页做相关处理(提取关键字、去掉广告),最后提供一个用户检索接口
抓取流程:选取一部分已有的URL,把它们放到待爬虫队列,从队列中取出URL,然后解析DNS获得主机的IP,通过IP对应的服务器下载HTML页面,保存到搜索引擎的本地服务器。分析这些网页内容,找出网页里面其他的URL连接,继续执行第二步,直到爬取条件结束
-
局部爬虫(聚焦爬虫):
针对特定网站的爬虫,面向需求的爬虫,获取页面的局部数据,比如音频、视频、图片等等。 -
增量爬虫:
每隔一段时间获取网站最新的数据
简单来说:通用爬虫就像互联网的“全景扫描仪”,典型代表是搜索引擎的爬虫,追求尽可能覆盖更多网页;聚焦爬虫则是“精准狙击枪”,只为特定目标抓取数据。
6.爬虫的进攻方与防守方(robots协议)
反爬:网站通过制定对应的政策来防止爬虫获取网站的数据
反反爬:通过制定对应的政策来破解网站的反爬机制,从而获取网站的数据
robots.txt 君子协议,哪些是可以爬的【allow】,哪些是不可以的【disallow】
/robots.txt
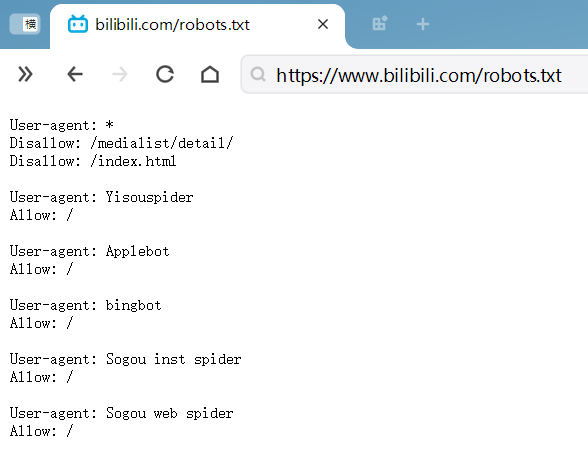
阿b的大部分都是allow,少部分是disallow,大家也可以多看几个网站了解一下,比如百度、豆瓣、微博等等。
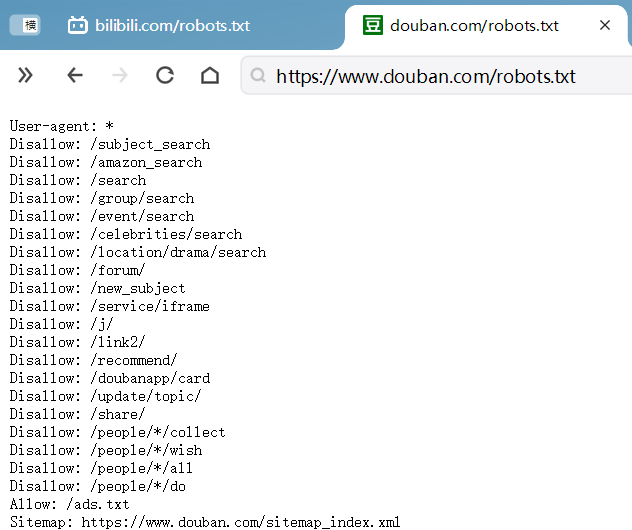
豆瓣的 Allow: /ads.txt ,我们可以看下有哪些数据:
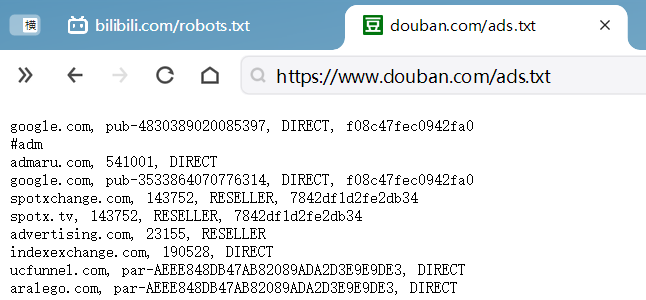
待继续补充…

















 3246
3246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









