




安装chrome浏览器和配置好chromedriver,对应版本查询(win+R,cmd,chromedriver)
python安装好selenium库
1.浏览器窗口相关:
get打开浏览器:
from selenium import webdriver
browser = webdriver.Chrome() #browser变量名可以自己随便取
browser.get('某个url')
关闭浏览器:
browser.quit()
网页最大化:
browser.maximize_window()
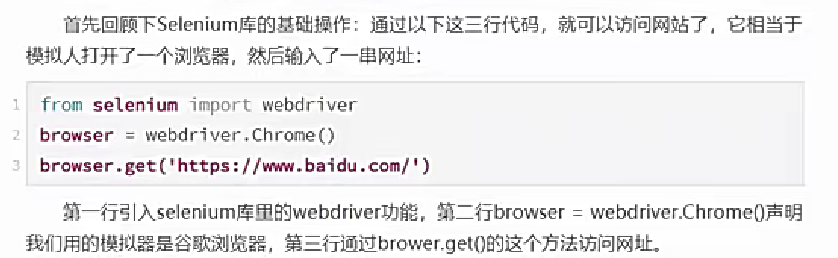
2.用xpath定位元素【重点】
在网页用F12,点小箭头找你要的元素,复制这个元素的xpath(就不用自己去找结构层级去写了)
现在获取到了这个元素,这个xpath相当于是它身份的象征,如同id
browser.find_element_by_xpath('对应的xpath')
当我们想点击这个元素,用.click()
browser.find_element_by_xpath('对应的xpath').click()
想在输入框里面输入内容,用.send_keys()
browser.find_element_by_xpath('对应的xpath').send_keys('要输入的内容')
如果默认输入框里面有内容,用.clear()清除
browser.find_element_by_xpath('对应的xpath').clear()
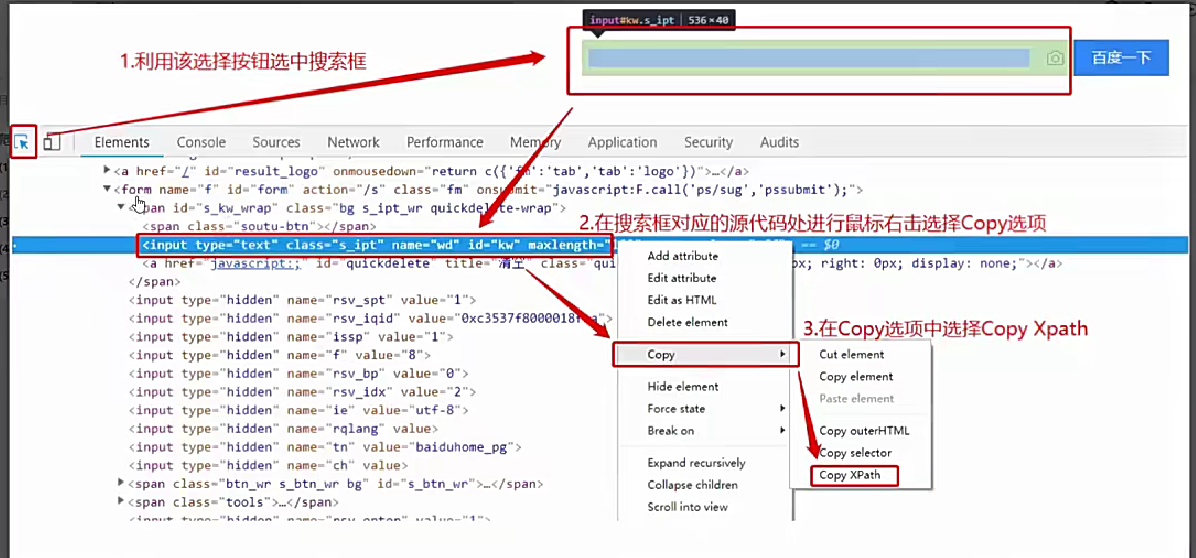
3.用css_selector定位元素
和xpath同样操作,使用时将 find_element_by_xpath 换成 find_element_by_css_selector 即可
如果上述两个方法都定位不到元素,可以使用pyautogui库
因为是访问网页点击按钮后跳转,所以最好休息3秒钟再进行其他操作,如果是request直接访问某网页,则通常不需要等待。
time.sleep(3)
我的理解:request直接访问url,selenium模拟打开浏览器访问url
【注意:使用的时候要记得导入库,比如用time.sleep()要记得在代码顶部写好 import time】
4.page_source获取网页源代码
data=browser.page_source()
print(data)
5.无界面浏览器的设置【爬取大量数据时不想打开多个页面】
主要区别在于把一行代码换成了三行代码
from selenium import webdriver
browser = webdriver.Chrome() #browser变量名可以自己随便取
browser.get('某个url')
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
browser = webdriver.Chrome(options = chrome_options)#参数名由chrome_options改成了options
browser.get('某个url')
6.子页面、同级页面切换 和 滚轴滚动
(1)切换子页面(网页中的网页)
browser.switch_to.frame(子页面的name值)
(2)切换浏览器同级页面
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.baidu.com/s?rtt=1&bsst=1&cl=2&tn=news&ie=utf-8&word=阿里巴巴")
browser.find_element_by_xpath("//*[@id='1']/div/h3/a").click() # 模拟点击第一条新闻,会新打开一个网页
handles = browser.window_handles # 获取浏览器所有窗口句柄,也即各个窗口的身份信息
browser.switch_to.window(handles[0]) # 切换到最开始打开的窗口
browser.switch_to.window(handles[-1]) # 切换到最新(倒数第一个)打开的窗口
data = browser.page_source # 这里获取到的就是最新打开页面的网页源代码了,因为切换到了它
print(data)
如果有三个页面就是0,-1,-2
(3)控制滚动轴滚动
#方法1:滚动1个页面高度的距离(非常灵活,强烈推荐)
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
#方法2:离最顶端向下滚动60000像素距离,通常也就是滚到最下面了
browser.execute_script('document.documentElement.scrollTop=60000')
大屏电脑一般就是1920*1080像素,滚动60000像素一般也就滚动到最下面了
7.浏览器前进或者后退
回到前一页面:
browser.back()
前往下一页面:
browser.forward()

















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









