




【学习目标】
- 掌握推理模型数据集的结构及转换。
- 掌握强化学习GRPO算法以及GRPOTrainer的应用;
- 掌握推理模型的训练流程。
【任务描述】
2025年1月,杭州深度求索公司(DeepSeek)发布了推理模型DeepSeek-R1,让推理模型的关注度快速的飙升,学术圈也掀起一股复现DeepSeek-R1的浪潮。李飞飞等斯坦福大学和华盛顿大学的研究人员以不到50美元的云计算费用,成功训练出了一个名为s1的人工智能推理模型。该模型在数学和编码能力测试中的表现,据称与OpenAI-o1和DeepSeek-R1等尖端推理模型不相上下。当然DeepSeek-R1的火热还是有其本质原因的:比如创新的强化学习GRPO、MoE/MLA/MTP、高性能低成本、开源等。
本任务要求在低成本条件下,基于Qwen基座模型,使用OpenAI的GSM8K数据集(一个包含8,500道左右高质量的小学数学题),使用强化学习GRPO复现类似DeepSeek-R1的推理模型。最终模型推理类似下图右侧部分所示:
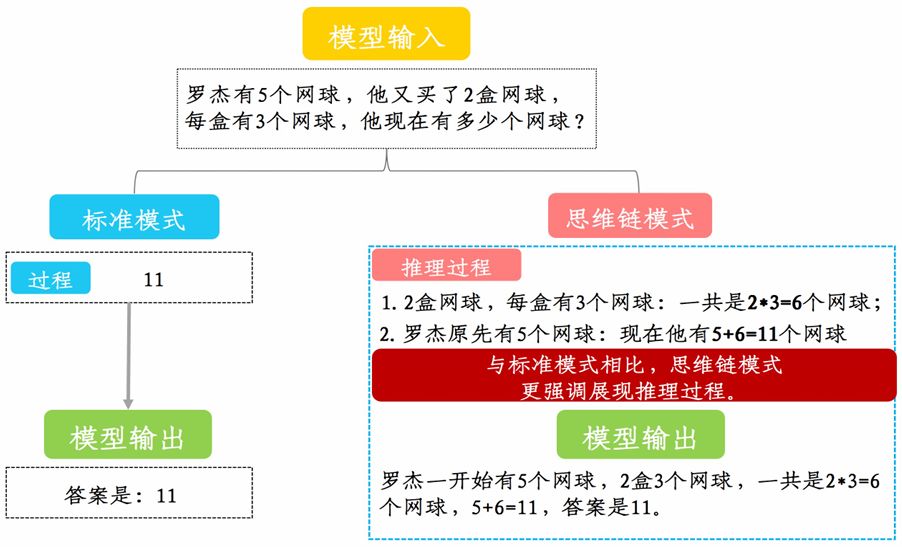
使用Huggingface TRL库基于GRPO复现DeepSeek-R1推理模型




















 755
755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











