




百亿级存储架构: ElasticSearch+HBase 海量存储架构与实现
尼恩:百亿级数据存储架构起源
在40岁老架构师 尼恩的读者交流群(50+)中,经常性的指导小伙伴们改造简历。
经过尼恩的改造之后,很多小伙伴拿到了一线互联网企业如得物、阿里、滴滴、极兔、有赞、希音、百度、网易、美团的面试机会,拿到了大厂机会。
这些机会的来源,主要是尼恩给小伙伴 改造了简历,植入了亮点项目、黄金项目。
尼恩的 亮点项目、黄金项目 需要持续迭代。下一个亮点项目、黄金项目是:百亿级数据存储架构。
同时,小伙伴在面试时,经常遇到这个面试难题。比如,前几天一个小伙伴面试字节,就遇到了这道题
阿里面试:百亿级数据存储,怎么设计?
字节面试:百亿级数据存储,只是分库分表吗?
于是,尼恩组织小伙伴开始研究和 设计 《百亿级数据存储架构》,帮助大家打造一个新的黄金项目,实现大厂的梦想。
已经发布的文章包括:
100亿级任务调度篇:从0到1, 从入门到 XXLJOB 工业级使用
高并发搜索ES圣经:从0到1, 从入门到 ElasticSearch 工业级使用
超级底层:10WQPS/PB级海量存储HBase/RocksDB,底层LSM结构是什么?
一:百亿级 海量存储数据服务的业务背景
很多公司的业务数据规模庞大,在百亿级以上, 而且通过多年的业务积累和业务迭代,各个业务线错综复杂,接口调用杂乱无章,如同密密麻麻的蛛网,形成了难以理清的API Call蜘蛛网。
API 调用蜘蛛网 如图 所示:
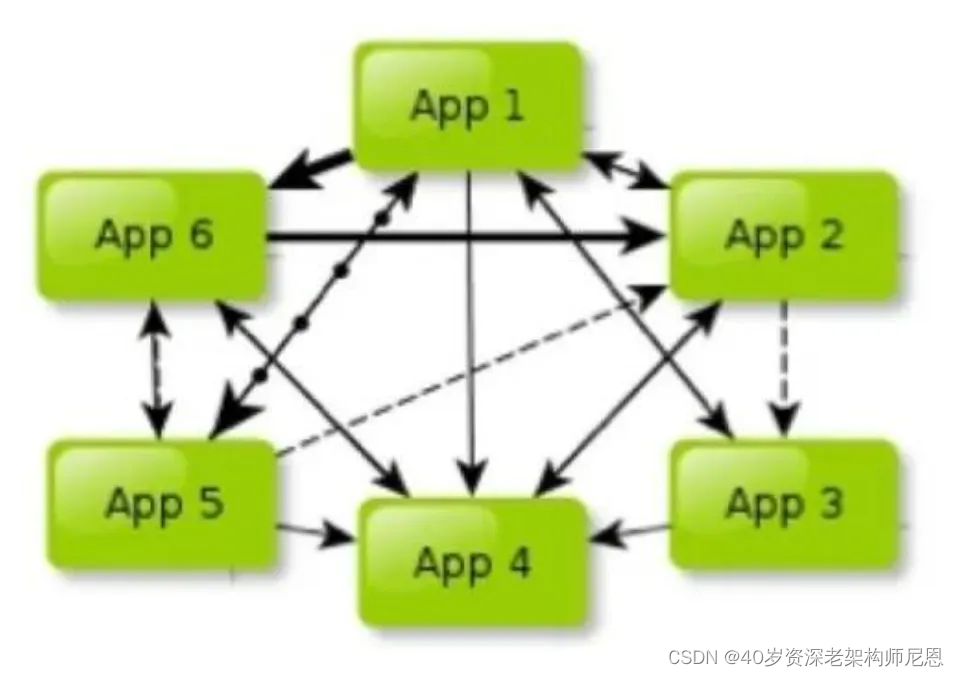
这种API 调用蜘蛛网的特点是:
-
第一,各个业务线互相依赖。A向B要数据,B向C请求接口,C向A需求服务,循环往复,令人目不暇接。
-
第二,各自为政,独立发展。各业务线各有财产,各自为营,宛如诸侯割据,拥兵自重。各自一滩、烟囱化非常严重。
-
第三,无休止的跑腿成本、无休止的会议沟通成本,沟通和协调成本让人望而生畏。
如何降低成本,降本增效, 迫切需要进行各个业务线的资源的整合、数据的整合、形成统一的海量数据服务,这里成为为数智枢纽(Data Intelligence Hub)服务/ 或者百亿级 数据中心服务,通过 统一的 数智枢纽(Data Intelligence Hub)服务 将这错综复杂的蜘蛛网变成简明的直线班车。
数智枢纽(Data Intelligence Hub)服务 / 或者百亿级 数据中心服务 如下图 所示:
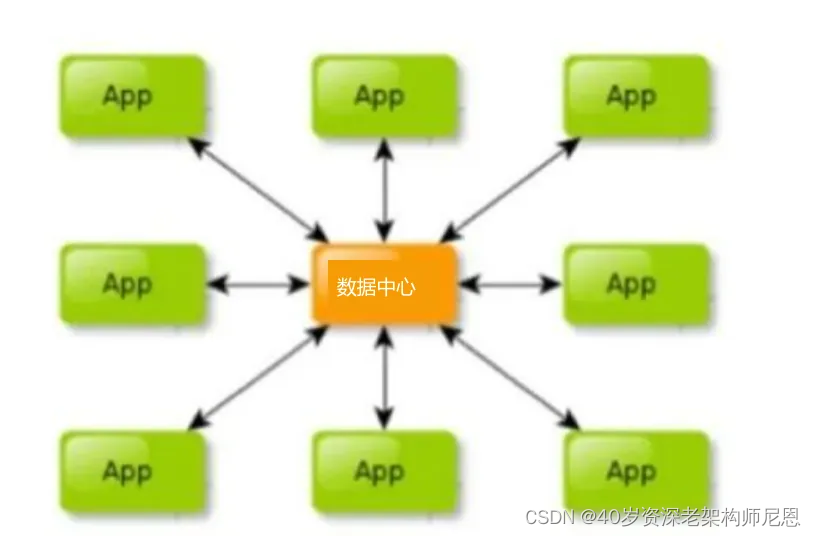
数智枢纽(Data Intelligence Hub)服务/ 或者百亿级 数据中心服务带来的几个优势:
-
第一,将省去不必要的接口调用。业务穿插不再混乱,减少无休止的会议沟通,解决数据难以获取、速度缓慢的问题。
-
第二,统一数据中心将大大节省产品和开发人员的时间,提升整体工作效率。各个业务线在新的系统下将协同作战,资源高效利用,真正实现事半功倍。
-
第三,进行统一的高可用优化、高并发优化,确保:稳如泰山,快如闪电。
总而言之,数智枢纽(Data Intelligence Hub)服务 的出现,将从根本上改变我们的统一数据存储和数据访问的工作方式,实现资源整合和效率提升。最终实现了: 稳如泰山,快如闪电,大气磅礴,节约成本,清晰明了。
二:架构设计与模块介绍
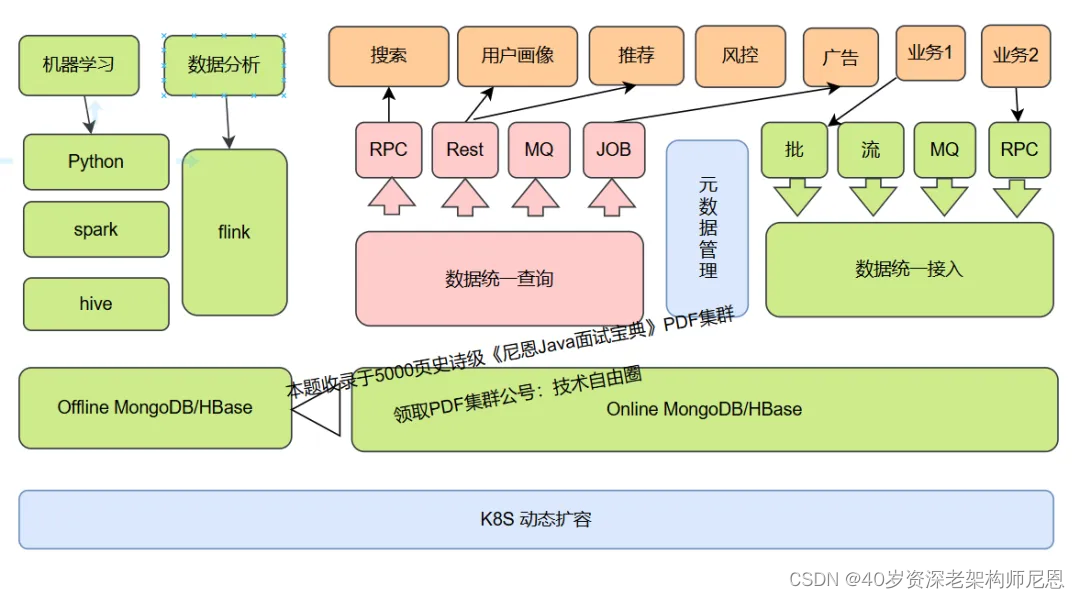
先看一下整体架构,整个数智枢纽(Data Intelligence Hub)服务 核心主要分为:
-
数据统一接入层
-
数据统一查询层
-
元数据管理
-
索引建立
-
平台监控
-
在线与离线数据存储层
先看一下整体架构图,如下图:
下面将分别对其进行介绍。
尼恩提示: 以上内容比较复杂, 如果需要深入了解, 请参见尼恩后续的《百亿级海量数据存储架构和实操》配套视频。
三:数据统一查询层的业务梳理
一般来说,数据统一查询层,大同小异,可以总结出以下几大常见的数据查询类型:
-
Key-Value查询,最简单的kv查询,并发量可能很高,速度要求快。比如风控。
-
Key-Map查询,定向输出,比如常见的通过文章id获取文章详情数据,kv查询升级版。
-
MultiKey-Map批量查询,比如常见的推荐Feed流展示,Key-Map查询升级版。
-
C-List多维查询查询,指定多个条件进行数据过滤,条件可能很灵活,分页输出满足条件的数据。这是非常常见的,比如筛选指定标签或打分的商品进行推荐、获取指定用户过去某段时间买过的商品等等。
-
G-Count统计分析查询,数仓统计分析型需求。如数据分组后的数据统计。
-
G-Top统计排行查询,根据某些维度分组,展示排行。如数据分组后的最高Top10帖子。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1802
1802



 到【灌水乐园】发言
到【灌水乐园】发言








