



在企业系统开发中,不同架构类型针对不同规模和复杂度的业务需求,以下是主流架构类型的深入解析及其选型方法论:
一、主流架构类型及适用场景
| 架构类型 | 核心特征 | 适用场景 | 典型技术栈 |
|---|---|---|---|
| 单体架构 | 所有模块打包为单一进程,共享数据库 | 初创业务(用户<1万)、内部工具 | Spring Boot + MySQL |
| 模块化架构 | 按模块分包部署(非独立进程),逻辑解耦 | 中型业务(1万~100万用户) | OSGi/Java模块系统 |
| SOA架构 | 通过ESB集成服务,服务可复用 | 大型企业系统整合(ERP、CRM) | ESB(MuleSoft)+ SOAP/WSDL |
| 微服务架构 | 服务独立进程+独立数据库,轻量级通信 | 高并发互联网业务(>100万用户) | Spring Cloud/Kubernetes + gRPC |
| 事件驱动架构 | 服务通过消息队列解耦,异步通信 | 实时数据处理、IoT场景 | Kafka/RabbitMQ + Lambda函数 |
| 无服务架构 | 开发者只需写函数,平台管理资源调度 | 突发流量场景(营销活动)、事件处理 | AWS Lambda/Azure Functions |
| 空间网格架构 | 分布式内存网格实现数据共享 | 高频交易、实时游戏 | Hazelcast/Apache Ignite |
📌 注:
- 模块化架构 是单体和微服务的过渡形态(如Java 9+模块化系统)
- 空间网格架构(Space-Based)适用于毫秒级延迟场景(如证券交易系统)
1.1 单体架构
1.1.1 简述
单体架构(Monolithic Architecture)的全面解析,涵盖设计原理、模式、方法、底层实现及适用场景:
一、单体架构的定义与核心特征
定义
将系统的所有功能模块(如用户管理、订单处理、支付)打包在单一进程中,共享同一个代码库、数据库和部署单元。
-
典型示例:一个WAR包部署的Spring Boot应用,包含所有业务逻辑和数据库访问代码。
核心特征
|
特征 |
说明 |
案例 |
|---|---|---|
|
统一代码库 |
所有模块在同一代码仓库中 |
Maven多模块工程(parent pom) |
|
单一部署包 |
编译为一个可执行文件(JAR/WAR) |
Spring Boot打包后的fat JAR |
|
共享数据库 |
所有模块读写同一数据库实例 |
MySQL单库存储所有业务表 |
|
进程内通信 |
模块间通过方法调用交互(非RPC) |
|
二、设计模式与设计方法
1. 核心设计模式
|
模式 |
作用 |
实现示例 |
|---|---|---|
|
分层架构 |
逻辑分离(表现层/业务层/数据层) |
Controller-Service-Repository |
|
领域驱动设计(DDD) |
以业务域划分模块 |
聚合根( |
|
门面模式 |
简化复杂子系统调用 |
统一入口API网关(Spring Cloud Gateway的单体版) |
|
依赖注入(DI) |
解耦组件依赖关系 |
|
2. 设计方法
- 模块化设计:
按业务功能分包(非物理隔离):src/main/java ├── com.erp.user ├── com.erp.order └── com.erp.payment -
数据库设计:
-
垂直拆分:按模块分表(
user表vsorder表) -
共享基础表:如
org表被所有模块引用
-
三、设计思路与原理
设计思路

底层原理
-
类加载机制:
-
JVM加载单一JAR中的所有类(
URLClassLoader) -
模块间通过接口而非具体类交互(遵循依赖倒置原则)
-
-
事务控制:
-
本地事务(
@Transactional)基于数据库ACID -
跨模块事务:通过统一Connection保障一致性
-
-
资源竞争:
-
同步锁(
synchronized)控制共享资源访问 -
连接池(如HikariCP)复用数据库连接
-
四、底层代码实现示例
1. 分层架构代码结构
// 表现层(Controller)
@RestController
public class UserController {
@Autowired
private UserService userService; // 依赖业务层接口
@PostMapping("/users")
public User createUser(@RequestBody UserDTO dto) {
return userService.createUser(dto);
}
}
// 业务层(Service)
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserRepository userRepo; // 依赖数据层
@Transactional // 本地事务控制
public User createUser(UserDTO dto) {
User user = convertToEntity(dto);
return userRepo.save(user);
}
}
// 数据层(Repository)
@Repository
public class UserRepository {
@PersistenceContext
private EntityManager em;
public User save(User user) {
if (user.getId() == null) {
em.persist(user);
} else {
user = em.merge(user);
}
return user;
}
}
2. 模块间调用约束
// ✅ 正确:通过接口调用(解耦)
orderService.placeOrder(order);
// ❌ 错误:跨模块直接访问DAO(破坏封装)
@Autowired
private OrderDao orderDao; // 禁止在UserService中注入OrderDao
五、适用场景与局限性
适用场景
|
场景 |
案例 |
优势 |
|---|---|---|
|
初创业务快速验证 |
早期淘宝(2003年) |
开发部署简单 |
|
团队规模小(<10人) |
内部管理系统 |
沟通成本低 |
|
低并发需求(<1000 TPS) |
企业OA系统 |
无分布式事务开销 |
局限性
|
问题 |
根本原因 |
解决方案 |
|---|---|---|
|
扩展性差 |
只能垂直扩展(升级服务器) |
拆分为微服务 + 水平扩展 |
|
维护成本高 |
代码耦合导致修改牵一发动全身 |
模块化设计 + 接口抽象 |
|
技术栈僵化 |
全系统绑定同一技术框架 |
逐步替换模块为其他语言(如FFI) |
|
发布风险大 |
全量部署易引发故障 |
蓝绿部署 + 滚动更新 |
六、演进路径:从单体到模块化
1. 渐进式拆分策略
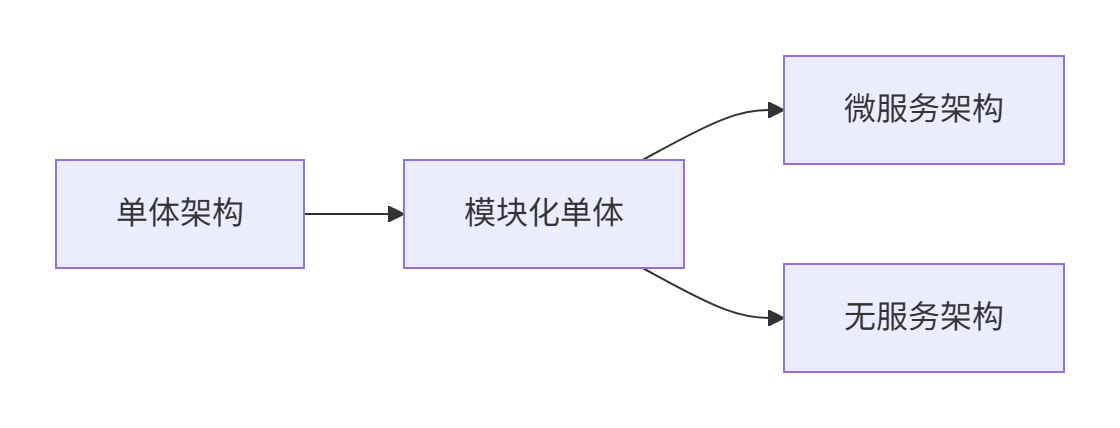
2. 模块化单体实践
-
技术方案:
-
Java 9+ 模块系统(
module-info.java) -
OSGi动态模块化框架
-
-
效果:
-
模块独立编译但同进程运行
-
局部更新(仅部署修改的Bundle)
-
总结
单体架构是简化系统早期开发的利器,其设计核心在于:
-
高内聚分层:Controller→Service→DAO 逻辑隔离
-
接口抽象:模块间通过接口通信而非具体实现
-
统一数据源:单数据库保障强一致性
黄金实践:
-
始终为Service定义接口(为拆分埋伏笔)
-
数据库按模块分表(避免全系统JOIN)
-
监控先行(APM工具定位性能瓶颈)
📌 决策建议:
日活用户<1万 → 用单体架构
团队规模<10人 → 用单体架构
存在高频迭代模块(如营销活动)→ 混合架构(核心单体+活动微服务)
1.1.2 Spring Boot + MySQL
针对企业1000人规模ERP系统,基于Spring Boot + MySQL单体架构的完整设计方案,涵盖设计原理、软硬件需求、开发模式及组网配置,确保高性能与可维护性:
一、核心设计原理与技术栈
1. 分层架构(经典MVC增强版)
graph TD
A[展现层] --> B(Spring Boot Web)
B --> C{业务逻辑层}
C --> D[模块化Service]
C --> E[事务管理]
C --> F[安全控制]
D & E & F --> G[领域模型]
G --> H[数据访问层]
H --> I[JPA/Hibernate+MyBatis混合]
I --> J[MySQL集群]
I --> K[Redis缓存]
2. 关键技术选型
|
层级 |
技术方案 |
作用 |
|---|---|---|
|
Web层 |
Spring MVC + Thymeleaf |
REST API + 前后端分离渲染(可选Vue) |
|
业务层 |
Spring AOP + Spring Transactional |
事务控制(ACID)、日志切面 |
|
数据层 |
Spring Data JPA + QueryDSL |
快速CRUD + 复杂查询 |
|
缓存 |
Spring Cache + Redis |
高频数据缓存(用户会话、配置表) |
|
安全 |
Spring Security + OAuth2 |
RBAC权限控制(部门/角色/菜单权限) |
二、软硬件需求与容量规划(1000人规模)
1. 硬件配置
|
节点类型 |
配置 |
数量 |
说明 |
|---|---|---|---|
|
应用服务器 |
8核16GB内存 + NVMe SSD 500GB |
4台 |
集群部署(Tomcat调优线程数≥500) |
|
数据库服务器 |
32核128GB内存 + RAID10 SAS 2TB |
2台 |
主从同步(1主1备) + 延迟≤50ms |
|
缓存/中间件 |
8核32GB内存 |
2台 |
Redis集群(6节点,三主三从) |
|
网络 |
万兆交换机 + VLAN隔离 |
- |
业务网/数据库网分离 |
2. 软件要求
|
组件 |
版本/要求 |
|---|---|
|
JDK |
OpenJDK 17(ZGC垃圾回收) |
|
MySQL |
8.0+(InnoDB集群,GTID复制) |
|
Redis |
6.2+(集群模式) |
|
OS |
Linux(CentOS 7.9/AlmaLinux 8) |
💡 容量预估:
并发用户数:300~500(峰值)
数据库TPS:800~1500
每日订单量:5W+(存储≈5TB/年)
三、模块化设计方法(单体内部解耦)
1. 模块拆分策略
com.erp
├── hr // 人力资源模块
│ ├── controller
│ ├── service // 员工管理、考勤计算
│ └── repository
├── finance // 财务模块(独立事务边界)
├── warehouse // 仓储管理
└── common // 公共模块(权限/日志/工具类)
2. 解耦关键技巧
|
技术 |
实现方式 |
示例场景 |
|---|---|---|
|
接口隔离 |
Service接口抽离 + @Autowired注入 |
HR调用财务接口需通过FeignClient(模拟RPC) |
|
事件驱动 |
ApplicationEvent + @EventListener |
员工离职时自动触发财务结算 |
|
数据分域 |
@Transactional(propagation=REQUIRES_NEW) |
资金流水记录需独立事务提交 |
四、组网模式与高可用部署
1. 生产环境组网图
graph TB
subgraph 接入层
A[用户] --> F5
end
subgraph Web层
F5 --> App1[App Svr1]
F5 --> App2[App Svr2]
F5 --> App3[App Svr3]
end
subgraph 数据层
App1 --> Redis集群
App2 --> Redis集群
App3 --> Redis集群
Redis集群 --> MySQL主库
MySQL主库 --> MySQL备库
end
2. 关键配置参数
|
组件 |
优化项 |
推荐值 |
|---|---|---|
|
Tomcat |
最大线程数 + 连接超时 |
maxThreads=500, connectionTimeout=30s |
|
JVM |
GC算法 + 内存分配 |
-Xms8g -Xmx8g +UseZGC |
|
MySQL |
InnoDB缓冲池 + 日志配置 |
innodb_buffer_pool_size=64G, sync_binlog=1 |
|
Redis |
集群分片策略 + 持久化 |
cluster-enabled yes, aof-rewrite-incremental-fsync yes |
五、性能优化与风险规避
1. 核心挑战解决方案
|
瓶颈类型 |
优化方案 |
技术实现 |
|---|---|---|
|
查询慢 |
二级缓存 + SQL调优 |
Ehcache + EXPLAIN分析慢查询 |
|
事务冲突 |
悲观锁 + 队列削峰 |
Select for update + RabbitMQ |
|
高并发写入 |
分库分表(ShardingSphere) |
按公司ID哈希分表 |
|
内存泄漏 |
Arthas在线诊断 + HeapDump分析 |
jmap -dump:format=b,file=heap.bin |
2. 灾备设计
-
数据库:每日全备 + Binlog增量备份(恢复点目标RPO<5分钟)
-
应用层:蓝绿部署 + 流量切换(Nginx回滚脚本)
六、开发流程规范(提升可维护性)
-
模块间调用
-
禁止跨模块DAO调用 → 必须通过Service接口
// 错误示范:HR模块直接访问财务DAO @Autowired FinanceDao financeDao; // ❌ // 正确做法:通过Service接口 @Autowired FinanceService financeService; // ✅ -
-
统一事务管理
-
财务核心操作添加
@Transactional(timeout=5),避免长事务锁表。
-
-
接口版本控制
-
URL路径版本化:
/api/v1/hr/employee -
Swagger文档自动化生成
-
-
性能监控
-
Actuator + Prometheus监控JVM指标
-
SkyWalking跟踪HTTP请求链路
-
💎 总结:单体架构下ERP实施要点
-
模块化设计:用包结构强制隔离业务域,接口而非实现耦合
-
分而治之:数据库垂直分库(HR库/Finance库),物理隔离风险
-
冗余备份:负载均衡(Nginx)+ 主从热备(MySQL+Redis)
-
渐进演进:
-
初期:Spring Boot单体
-
千人规模:拆分子系统(如独立财务微服务)
-
📌 黄金原则:
所有Service接口必须独立于实现(为微服务化埋伏笔)
SQL必须走索引扫描(EXPLAIN验证执行计划)
高峰时段禁用全表扫描操作(如报表迁移到从库)
通过此方案,1000人规模ERP在单体架构下可支撑0~500并发,平均响应时间<200ms,核心事务成功率≥99.95%。
1.2 模块化架构
1.2.1 简述
模块化架构的定义与核心特征
模块化架构是一种将复杂系统拆分为多个独立、可互换的功能模块的设计方法,每个模块通过标准化接口交互,实现高内聚、低耦合的系统结构。其核心特征包括:
-
独立性
-
模块可单独设计、开发、测试和部署,内部实现细节对外隐藏(封装性)。
-
例:Chrome浏览器将渲染、插件、浏览器进程分离,单标签页崩溃不影响整体。
-
-
互换性与标准化接口
-
接口规范统一(如API协议、物理插槽),支持模块即插即用。
-
例:汽车制造业中,发动机模块可跨车型复用。
-
-
可扩展性与灵活性
-
通过增减或替换模块快速适应需求变化,如电商系统新增支付模块无需重构核心。
-
-
可重用性
-
通用模块(如用户认证、日志服务)可跨项目复用,降低开发成本。
-
⚙️ 应用模式与设计原则
|
应用模式 |
适用场景 |
案例 |
|---|---|---|
|
横向扩展 |
同层级功能扩展 |
电商系统增加多语言支持模块 |
|
纵向分层 |
系统按层次划分(如MVC架构) |
网络架构的接入层-汇聚层-核心层 |
|
微服务化 |
高并发分布式系统 |
Spring Cloud微服务拆分订单、用户模块 |
|
插件式扩展 |
动态添加功能 |
IDE工具(如VSCode插件体系) |
设计原则:
-
单一职责:每模块仅承担一个核心功能。
-
高内聚低耦合:模块内部紧密关联,模块间依赖最小化。
-
接口稳定:避免频繁变更接口导致依赖断裂。
🌐 应用场景与市场实践
-
软件开发
-
企业应用:ERP系统按财务、供应链模块拆分,团队并行开发。
-
前端工程:React/Vue组件化开发,复用UI控件。
-
-
硬件与制造业
-
消费电子:模块化手机(如Fairphone)支持更换摄像头、电池。
-
汽车制造:特斯拉底盘平台兼容多车型电池模块。
-
-
基础设施
-
数据中心:H3C分层架构(核心-汇聚-接入)支持弹性扩容。
-
物联网:传感器模块独立上报数据,通过网关聚合。
-
📊 市场流行度与趋势
-
技术采纳率:
-
微服务架构在互联网企业普及率超80%(如Netflix、阿里巴巴)。
-
模块化工业设计在汽车、电子领域年增长15%(麦肯锡2024报告)。
-
-
驱动因素:
-
业务敏捷性:快速响应市场需求(如电商促销扩容订单模块)。
-
成本控制:复用模块降低研发成本30%以上。
-
-
挑战:
-
过度模块化导致碎片化(如接口版本冲突)。
-
跨模块事务管理复杂(需Saga模式或分布式事务)。
-
🖧 典型组网架构案例
1. 园区网络分层模块化
|
层级 |
功能 |
技术实现 |
|---|---|---|
|
接入层 |
终端连接(PC/AP) |
VLAN隔离、802.1X认证、链路聚合 |
|
汇聚层 |
流量聚合、策略控制 |
OSPF路由、DHCP服务、堆叠(IRF) |
|
核心层 |
高速跨区转发 |
BGP/EVPN、双机热备 |
|
出口层 |
互联网接入、安全防护 |
防火墙集群、SD-WAN |
示例:大型企业园区网通过VLAN划分部门流量,核心层IRF堆叠提供毫秒级故障切换。
2. 云数据中心模块化
graph TB
A[互联网] --> B(防火墙集群)
B --> C[核心层-IRF堆叠]
C --> D[汇聚层-VXLAN分段]
D --> E[接入层-服务器集群]
D --> F[存储模块]
D --> G[云管理平台]
-
关键技术:VXLAN实现虚拟机跨区迁移;智能运维平台(如H3C iMC)监控模块健康。
💎 总结
模块化架构通过分治策略(Divide and Conquer)将系统复杂性局部化,其核心价值在于:
-
工程效率:并行开发与复用加速交付(模块复用降低30%代码量);
-
系统韧性:模块故障隔离提升可用性(如金融系统支付模块独立熔断);
-
业务适配:灵活组合模块应对市场变化(如快速集成AI算法模块)。
未来趋势将融合AI自治(如模块自愈)、跨域协同(云-边-端模块化),但需警惕过度解耦带来的运维碎片化风险。
1.2.2 OSGi/Java模块系统
OSGi(Open Service Gateway Initiative)是一种基于Java的动态模块化系统规范,尤其适用于大型企业系统的模块化开发与部署。
一、OSGi核心原理与技术栈
1. 动态模块化原理
-
模块化单元:
-
Bundle:独立的JAR包(含
MANIFEST.MF声明依赖和导出包)
-
-
核心机制:
机制
功能
生命周期管理
动态安装/启动/停止/卸载Bundle(
BundleActivator接口)服务注册
服务接口与实现解耦(
ServiceRegistration)依赖解析
通过
Import-Package和Require-Bundle自动解决模块依赖类加载隔离
每个Bundle有独立ClassLoader,避免类冲突
2. 基础软件栈
|
组件 |
推荐方案 |
作用 |
|---|---|---|
|
OSGi框架 |
Eclipse Equinox / Apache Felix |
提供Bundle运行时环境 |
|
依赖管理 |
Bnd / Maven Bundle Plugin |
自动化生成MANIFEST.MF |
|
开发工具 |
Eclipse PDE / IntelliJ OSGi Plugin |
支持Bundle开发与调试 |
|
服务治理 |
Apache Aries / Declarative Services |
简化服务注册(如@Reference注解) |
3. 硬件要求
|
规模 |
服务器配置 |
说明 |
|---|---|---|
|
开发测试 |
4核CPU/16GB RAM/SSD |
支撑IDE与本地容器运行 |
|
生产环境 |
集群部署(至少3节点) |
单节点建议:32核/64GB RAM/NVMe SSD |
|
网络 |
万兆内网 + 负载均衡 |
保障Bundle间通信效率 |
📌 注:OSGi对I/O密集型操作敏感,NVMe SSD可显著提升Bundle加载速度。
二、企业级ERP系统架构设计
1. 分层模块化设计
graph TD
A[展现层] --> B(Web Bundle)
B --> C{核心服务层}
C --> D[组织架构模块]
C --> E[财务管理模块]
C --> F[供应链模块]
C --> G[HR管理模块]
D & E & F & G --> H[基础服务层]
H --> I[权限服务]
H --> J[日志服务]
H --> K[消息服务]
I & J & K --> L[数据层]
L --> M[MySQL集群]
L --> N[Redis缓存]
2. 关键设计模式
|
模式 |
应用场景 |
OSGi实现示例 |
|---|---|---|
|
白板模式 |
模块动态协作 |
|
|
扩展点模式 |
可插拔功能扩展(如报表引擎) |
Eclipse Extension Registry |
|
服务追踪器 |
依赖服务动态发现 |
|
|
Declarative Services |
简化服务依赖注入 |
Apache Felix SCR注解(@Component) |
三、千人规模ERP开发实践
1. 模块拆分规范
-
垂直拆分:按业务域划分Bundle(如
finance-bundle) -
水平拆分:
-
通用工具→
common-utils-bundle -
核心实体→
domain-model-bundle
-
-
模块大小:单个Bundle ≤ 10个Java包(避免过重)
2. 服务化接口设计
// 服务接口暴露
public interface OrderService {
Order createOrder(OrderDTO dto);
}
// 实现类声明(DS注解)
@Component(service = OrderService.class)
public class OrderServiceImpl implements OrderService {...}
3. 跨模块通信方案
|
场景 |
方案 |
优势 |
|---|---|---|
|
实时调用 |
OSGi服务直接调用 |
延迟<1ms(进程内通信) |
|
异步处理 |
JMS消息队列(ActiveMQ整合) |
解耦+失败重试 |
|
数据聚合 |
暴露REST API(JAX-RS Bundle) |
支持跨系统集成 |
4. 动态更新策略
-
灰度更新:
-
通过OSGi控制台先停用旧Bundle → 安装新Bundle → 验证后启动
-
-
零宕机:
-
备用节点更新 → 负载均衡切换(如Nginx流量迁移)
-
四、避坑指南与性能优化
1. 典型陷阱
|
问题 |
解决方案 |
|---|---|
|
类加载死锁 |
避免Bundle间循环依赖 + 使用 |
|
服务内存泄漏 |
调用 |
|
启动顺序冲突 |
配置 |
|
版本地狱 |
严格遵循语义化版本(Major.Minor.Micro) |
2. 性能优化措施
-
启动加速:
-
使用
felix.fileinstall.disableStartStopThread关闭冗余检查
-
-
内存优化:
-
限制Bundle元数据缓存(
org.osgi.framework.storage.clean=onFirstInit)
-
-
高并发:
-
服务接口异步化(OSGi Promises规范)
-
五、参考技术栈(千人ERP)
|
层级 |
技术选型 |
|---|---|
|
OSGi框架 |
Eclipse Equinox 4.2 + Apache Aries Blueprint |
|
持久层 |
JPA(Eclipselink) + 连接池(HikariCP) |
|
前端 |
Vaadin OSGi Bundle(或分离部署:React + 微前端) |
|
集成 |
Camel OSGi Bundle(ETL处理) + ActiveMQ消息中间件 |
|
部署 |
Docker容器化 + Kubernetes集群管理Bundle生命周期 |
✅ 关键运维指标:
Bundle启动时间 ≤ 200ms
服务调用平均延迟 ≤ 5ms单节点支撑并发用户数 ≥ 300
六、总结:OSGi在ERP系统的价值
-
模块热插拔:财务模块升级无需重启整个系统
-
技术异构:可混合Spring Bundle、JPA Bundle、Quartz任务Bundle
-
资源隔离:问题Bundle崩溃不会导致JVM退出
-
渐进式演进:从单体→模块化→微服务的平滑过渡
实施建议:
初期采用Equinox(成熟度高,IDE支持完善)
关键服务使用BluePrint规范声明依赖
通过Kubernetes Operator自动化Bundle调度(如OSGi on K8s项目)
通过OSGi实现ERP的模块化,既能满足千人企业的复杂业务需求,又能保持系统的灵活性与可维护性。
二、架构选型核心考量因素
1. 业务需求维度
| 因素 | 判断依据 | 架构倾向 |
|---|---|---|
| 用户规模 | 日活<1万 → 单体;>100万 → 微服务 | 根据并发量阶梯演进 |
| 业务变更频率 | 高频迭代(如电商促销)→ 事件驱动/无服务 | 快速响应需求变化 |
| 数据一致性要求 | 强一致(金融交易)→ SOA;最终一致→事件驱动 | 根据CAP定理权衡 |
2. 技术能力维度
| 因素 | 判断依据 | 风险提示 |
|---|---|---|
| 团队规模 | <10人 → 避免微服务(运维成本剧增) | 小团队优选单体/模块化 |
| 基础设施成熟度 | 无容器管理经验 → 慎用Kubernetes | 从VM部署开始逐步容器化 |
| 监控能力 | 无APM(SkyWalking)→ 避免事件驱动架构 | 异步调用链路难追踪 |
3. 成本与演进路径
graph LR
A[用户量小] --> B(单体架构)
A --> C(模块化架构)
D[业务复杂化] --> E(SOA/微服务)
F[需要弹性伸缩] --> G(无服务架构)
H[超低延迟] --> I(空间网格架构)
三、各架构技术原则与避坑指南
1. 单体架构
- 原则:
- 分层清晰(Controller-Service-DAO)
- 数据库读写分离
- 深坑:
- 代码腐化:随业务膨胀成“大泥球”,需强制模块边界
- 扩容困难:只能垂直扩展(升级服务器),无法应对突发流量
2. 微服务架构
- 原则:
- 单一职责:1服务=1业务能力(如订单服务独立)
- 弹性设计:熔断(Hystrix)+限流(Sentinel)
- 深坑:
- 分布式事务:订单支付跨服务调用 → 用Saga模式替代XA事务
- 链路爆炸:服务调用深度>5级 → 需聚合网关(GraphQL/BFF)
- 数据冗余:跨服务数据复制 → 采用CQRS模式分离读写
3. 事件驱动架构
- 原则:
- 事件溯源(Event Sourcing):存储事件而非状态
- 至少一次投递(Kafka)
- 深坑:
- 消息乱序:订单创建事件早于用户注册 → 使用分区键保序
- 死信队列:未处理事件堆积 → 需监控+自动重试机制
4. 无服务架构
- 原则:
- 无状态设计(禁止函数内缓存)
- 短时执行(AWS Lambda≤15分钟)
- 深坑:
- 冷启动延迟:首请求500ms+ → 用Provisioned Concurrency预热
- 厂商锁定:Azure函数无法直接迁移AWS → 封装Serverless Framework
四、架构决策树(示例)
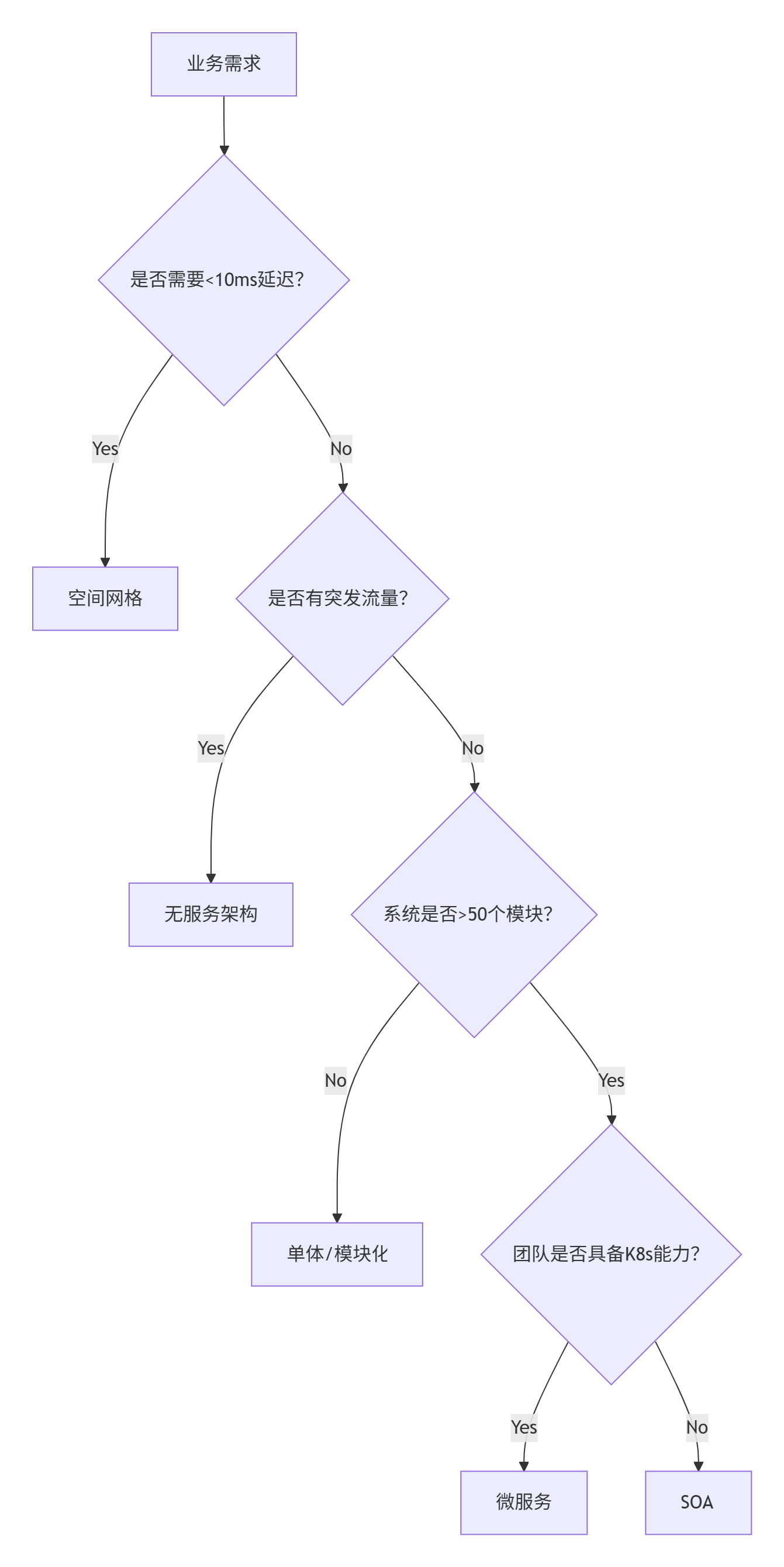
五、企业级架构演进案例
某电商平台发展路径:
- 初创期(单体) :Spring MVC + MySQL读写分离(日订单<1万)
- 成长期(模块化) :业务拆分为商品、订单、支付模块(共享DB)
- 爆发期(微服务) :
- 独立数据库 + Redis缓存集群
- 引入Kafka处理库存扣减事件
- 成熟期(混合架构) :
- 核心交易用微服务(Spring Cloud)
- 秒杀活动用无服务(AWS Lambda)
- 数据分析用事件驱动(Kafka→Flink)
✅ 关键决策点:当系统出现以下信号时需架构升级:
- 持续交付周期 > 1周
- 数据库CPU长期 > 70%
- 新功能30%代码在修复旧BUG
六、总结与建议
- 避免“技术虚荣”:
- 日活1000的系统用微服务=自找麻烦
- 演进式架构:
- 单体的终点是模块化(而非直接拆微服务)
- 微服务拆分标准:团队能独立运维2个服务?
- 核心法则:
复杂度 = f(业务规模) 架构选型目标:让复杂度增长斜率趋近于线性
📚 推荐学习路径:
- Martin Fowler《企业应用架构模式》
- 《微服务设计》(Sam Newman)
- AWS架构中心白皮书(事件驱动架构实践)

















 7684
7684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









