



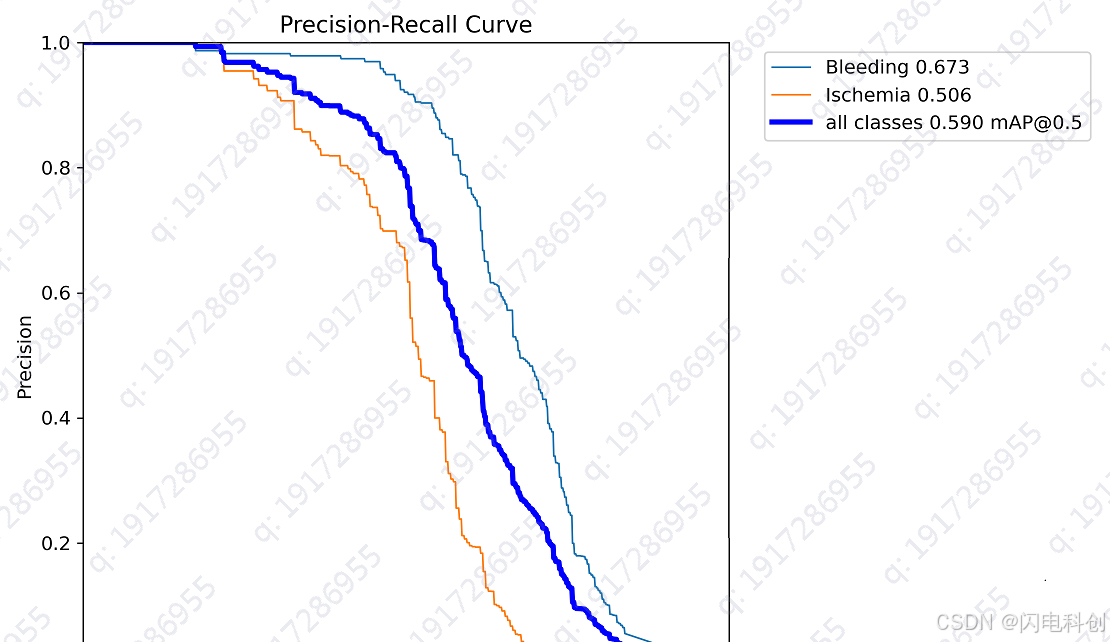
脑卒中实例分割是医学影像分析中的一个复杂任务,尤其在脑卒中图像的处理过程中,面临一系列挑战。与其他疾病的分割任务相比,脑卒中的实例分割不仅要求高精度地识别脑内不同类型的病灶,还需要对重叠病灶、复杂的结构变化等多方面因素进行建模。
计算机人工智sci/ei会议/ccf/核心,擅长机器学习,深度学习,神经网络,语义分割等计算机视觉,精通大小论文润色修改,代码复现,创新点改进等等
以下是脑卒中实例分割算法的主要难度分析:
1. 病灶形态和位置的多样性
🎯 难点:
- 多种病灶类型:脑卒中的病灶可能涉及缺血性(如梗死核心区、半暗带)和出血性(如脑出血区域)两大类型,每种病灶在影像中的表现差异很大,形态、大小、位置等都可能不同。
- 不规则形状:脑卒中病灶的形状非常不规则,可能是椭圆形、条状、弯曲等,且不同病灶之间有时会互相重叠,增加了分割的复杂度。
🚧 挑战:
- 难以建立统一的模型来处理所有种类的病灶,尤其是在不同形态下,算法可能对边缘模糊的区域分割精度较低。
- 病灶的不同位置和大小可能导致同一模型对不同区域的处理效果大不相同。
2. 多模态医学影像数据的融合
🎯 难点:
- 模态差异:脑卒中的影像通常包含多种模态(如T1、T2、DWI、FLAIR、CT等),每种模态的成像特性不同,病灶在不同模态下的表现也不同。不同模态下的病灶边界、形态特征和信号强度可能差异巨大。
🚧 挑战:
- 跨模态融合(例如通过深度学习模型结合多个模态信息)需要对不同模态的数据进行有效的对齐与特征融合。不同模态的信息互补性较强,但如何从多个模态中有效提取信息,并综合利用这些信息进行高效分割,依然是一个重要的难题。
- 模态间对比度差异可能导致某些模态对病灶的检测能力较差,这需要算法能够在各种模态下找到准确的病灶位置。
3. 实例分割的高精度要求
🎯 难点:
- 实例分割不仅要分割出病灶的总体区域(语义分割),还要对病灶进行区分,甚至是相邻或重叠的病灶。传统的语义分割方法并不足以处理这些复杂情形。
- 实例之间的边界模糊:脑卒中的病灶可能与周围组织的边界不明显,尤其是脑部病灶往往存在模糊边缘(如梗死区域和健康脑组织的过渡区),分割时很容易出现漏分或误分。
🚧 挑战:
- 对相邻或重叠病灶的处理较为困难,需要模型能够精确地区分不同的实例。
- 通过像素级的实例分割,既要求精确捕捉病灶的形态,又要避免将多个病灶误分为一个,或者将病灶分割成多个不相关的部分。
4. 标注的稀缺性和不一致性
🎯 难点:
- 标注困难:脑卒中影像的标注过程需要大量专业知识和经验,因此标注的样本数量通常非常有限。尤其是实例分割任务,每个病灶的边界、类别、大小等都需要详细标注,这对于医生和标注者来说是一项繁重且耗时的工作。
- 标注不一致性:即使由多名专家进行标注,标注的结果也可能存在较大差异,这种标注的不一致性会对算法训练造成困难。
🚧 挑战:
- 标注的稀缺性直接导致了训练数据集的有限性,这使得算法在训练时容易出现过拟合,难以在不同场景和病例中泛化。
- 不一致的标注使得监督学习难以建立准确的模型,尤其是在细节上容易产生差异。
5. 跨医院和设备的数据异质性
🎯 难点:
- 数据异质性:不同医院使用的影像采集设备(如MRI、CT)不同,成像的分辨率、噪声水平、对比度等特征都可能存在显著差异,这使得从多个数据源训练的模型容易遇到跨域迁移的问题。
- 影像分辨率差异:不同医院使用的设备可能有不同的分辨率,导致数据集在尺度上存在差异。
🚧 挑战:
- 跨域泛化能力差,一套在某一设备下训练好的模型可能无法很好地迁移到其他设备或医院的影像数据上。
- 数据预处理复杂,需要对不同设备的数据进行标准化或归一化处理,减少因设备差异带来的影响。
6. 缺乏时序数据分析能力
🎯 难点:
- 动态演化:脑卒中的病灶随着时间推移发生变化,急性期、亚急性期、慢性期的病灶具有不同的表现。传统的静态影像分割方法很难处理这种动态变化。
- 时序信息的缺失:大多数现有分割方法都是基于单张影像进行建模,而脑卒中患者的病灶随着时间发展不断变化。
🚧 挑战:
- 如何结合多时相影像进行病灶演化建模,并准确预测病灶的发展趋势,仍是一个亟待解决的问题。
- 时间信息的建模需要利用时序数据(例如CT或MRI的不同时间点图像),并在分割任务中有效地利用这些时间信息进行优化。
7. 实时计算与低延迟要求
🎯 难点:
- 在临床环境中,脑卒中的早期诊断和治疗(如溶栓、取栓等)对于时间的要求非常高,因此需要分割算法能够提供低延迟、高效能的推理结果。
- 实时计算要求算法在计算资源有限的设备(如移动设备、边缘计算平台)上进行部署,而这通常会限制模型的复杂度。
🚧 挑战:
- 在保证分割精度的同时,如何降低模型的计算复杂度,减少延迟是一个巨大的挑战。
- 对实时性要求较高时,模型的计算效率(如内存占用、推理时间)需要大幅提升。



















 1399
1399

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











