




 本文探讨了小样本类别增量学习的问题,该问题涉及模型在新数据集上学习新样本同时保持旧样本知识的能力。主要难点包括灾难性遗忘和新数据过拟合。提出使用嵌入网络和NCM分类器,通过正则化项保持旧知识,以缓解这两个问题。在每个数据集学习阶段,使用固定的基础模型保留旧知识,而新模型则不断学习新知识。
本文探讨了小样本类别增量学习的问题,该问题涉及模型在新数据集上学习新样本同时保持旧样本知识的能力。主要难点包括灾难性遗忘和新数据过拟合。提出使用嵌入网络和NCM分类器,通过正则化项保持旧知识,以缓解这两个问题。在每个数据集学习阶段,使用固定的基础模型保留旧知识,而新模型则不断学习新知识。
paper
[1] CVPR 2020: Semantic Drift Compensation for Class-Incremental Learning
[2] CVPR 2020: Few-Shot Class-Incremental Learning
目录
什么是小样本类别增量学习?
流程:
1)模型在大规模基础数据集 D ( 1 ) D^{(1)} D(1) 上训练
2)模型在不断增加的新数据集 D ( t ) ( t > 1 ) D^{(t)} (t>1) D(t)(t>1)上学习。 D ( t ) 与 D ( 1 ) D^{(t)}与D^{(1)} D(t)与D(1)类别不重叠,且样本数量较少。要求模型学习新样本,同时不忘记旧样本
关键两个难题:
1)对旧数据灾难性遗忘
2)对新数据过拟合
动机
增量学习过程中,base tasks 学习base knowledge,new tasks学习new (lifelong) knowledge。用两个组件base和life-long learning,分别保持旧知识和学习新知识。如图所示,Base Model学习旧知识,其参数保持不变。Model t(t>1)学习新知识,融合上一个模型的知识。
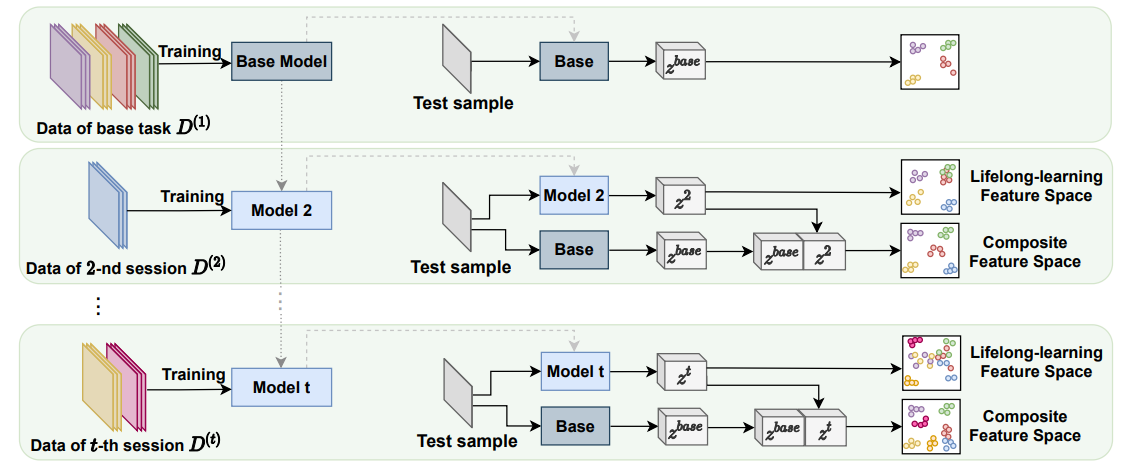
session D ( t ) D^{(t)} D(t)表示第t个数据集的学习阶段。
嵌入网络
小样本类别增量学习的图像分类框架主要有两种,特征提取器+softmax分类器,特征提取器+NCM分类器。由于用softmax分类器的挑战性及面对长任务序列的困难性[1],本选择第二种框架。
特征提取
特征提取网络使用嵌入网络。损失函数如下:
L = L M L + L R (1) \mathcal{L} = \mathcal{L}_{ML} + \mathcal{L}_{R} \tag{1} L=LML+LR(1)
其中, L M L \mathcal{L}_{ML}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2298
2298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









