




 本文提出了一种带视觉结构约束的直推式零样本学习方法,旨在解决未见类样本分类问题。方法通过视觉中心学习(VCL)、基于倒角距离的视觉结构约束(CDVSc)、基于二部图匹配的视觉结构约束(BMVSc)和基于Wasserstein距离的视觉结构约束(WDVSc),实现未见类样本的有效分类。实验结果表明,该方法在AwA2数据集上取得了显著的效果。
本文提出了一种带视觉结构约束的直推式零样本学习方法,旨在解决未见类样本分类问题。方法通过视觉中心学习(VCL)、基于倒角距离的视觉结构约束(CDVSc)、基于二部图匹配的视觉结构约束(BMVSc)和基于Wasserstein距离的视觉结构约束(WDVSc),实现未见类样本的有效分类。实验结果表明,该方法在AwA2数据集上取得了显著的效果。
带视觉结构约束的直推式零样本学习
Motivation

我们的方法是受[ECCV2016]的激发,思想如图所示:由于预训练CNN的强大判别性,测试图像的视觉特征可以分成不同的簇。我们把这些簇的中心叫Real Centers,我们相信如果我们有一个完美的投影函数将语义属性投影到视觉空间,这些投影中心(称Synthetic Centers)应该会和Real Centers对齐。然而,由于域漂移问题,在源域上学习到的投影函数并不完美,所以Synthetic Centers(即VCL Centers)会和Real Centers偏离,这样的话在这些偏离的中心中进行最近邻搜索并分配标签就会导致很差的ZSL性能。基于以上分析,除了源域数据,在学习投影函数的过程中,我们尝试利用存在的目标域未见类簇的判别性结构,即,学到的投影函数也应该在目标域对齐Synthetic Centers和Real Centers。
图中,VCL Centers是未见类投影中心,我们期望其和未见类的真实中心Real Center接近。但是我们没有未见类标签,所以用K-Means Centers中心去近似Real Centers。BMVSc Centers是我们使用视觉结构约束之后,得到的新投影中心,它们比VCL Centers更靠近真实中心。
Method
Visual Center Learning (VCL)
VCL是baseline。只使用源域的标注数据作为训练数据。
c
i
s
y
n
,
s
=
σ
2
(
w
2
T
σ
1
(
w
1
T
a
i
s
)
)
(1)
c_i^{syn,s} = \sigma_2(w_2^T\sigma_1(w_1^Ta_i^s)) \tag{1}
cisyn,s=σ2(w2Tσ1(w1Tais))(1)
其中,
c
i
s
y
n
,
s
c_i^{syn,s}
cisyn,s表示第i个已见类在视觉空间的投影中心,
a
i
s
a_i^s
ais表示第i个已见类的属性表示。
σ
\sigma
σ表示非线性操作Leak ReLU,
w
w
w是全连接层的参数。投影函数有两层全连接表示。
L
M
S
E
=
1
S
∑
i
=
1
S
∣
∣
c
i
s
y
n
,
s
−
c
i
s
∣
∣
2
2
+
Ψ
(
w
1
,
w
2
)
(2)
\mathcal L_{MSE} = \frac{1}{S} \sum_{i=1}^{S} || c_i^{syn, s} - c_i^s ||_2^2 + \Psi(w_1, w_2) \tag{2}
LMSE=S1i=1∑S∣∣cisyn,s−cis∣∣22+Ψ(w1,w2)(2)
其中,
c
j
s
c_j^s
cjs表示第i个已见类在视觉空间的真实中心,用所有特征向量的均值表示。
测试阶段,用投影函数得到未见类的投影中心 c i s y n , u c_i^{syn,u} cisyn,u,将测试图片在视觉空间距离最近的未见类作为分类结果。
i ∗ = arg min i ∣ ∣ ϕ ( x k u ) − c i s y n , u ∣ ∣ 2 (3) i^* = \argmin_i || \phi(x_k^u) - c_i^{syn, u} ||_2 \tag{3} i∗=iargmin∣∣ϕ(xku)−cisyn,u∣∣2(3)
ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)是CNN特征提取器, x k u x_k^u xku是未见类第u类的第k张图像, ϕ ( x ) ∈ R d × 1 \phi(x) \in \mathcal R^{d \times 1} ϕ(x)∈Rd×1。
代码里语义空间到视觉空间的映射用的是GCN不是FC
CDVSc——基于倒角距离的视觉结构约束
我们要对齐未见类的投影中心和真实中心。 但是在直推式ZSL中,只有未见类的未标注样本。实验发现,聚类中心和真实中心离的很近。所以,我们用聚类中心来代替真实中心。
那么,对齐聚类中心结构和投影中心结构的问题可以表示成减小两个无序高维点集距离的问题。受3D点云工作的启发,我们提出了对称倒角距离约束来解决结构匹配问题:
L C D = ∑ x ∈ C s y n , u min y ∈ C c l u , u ∣ ∣ x − y ∣ ∣ 2 2 + ∑ y ∈ C c l u , u min C s y n , u ∣ ∣ x − y ∣ ∣ 2 2 (4) \mathcal L_{CD} = \sum_{x \in C^{syn, u}} \min_{y \in C^{clu, u}} || x-y ||_2^2 + \sum_{y \in C^{clu, u}} \min_{C^{syn, u}} ||x-y||_2^2 \tag{4} LCD=x∈Csyn,u∑y∈Cclu,umin∣∣x−y∣∣22+y∈Cclu,u∑Csyn,umin∣∣x−y∣∣22(4)
最终的损失如下:
L C D V S c = L M S E + β × L C D (5) \mathcal L_{CDVSc} = \mathcal L_{MSE} + \beta \times \mathcal L_{CD} \tag{5} LCDVSc=LMSE+β×LCD(5)
BMVSc——基于二部图匹配的视觉结构约束
CDVSc的问题在于,有时候会存在多对一的匹配现象。这会导致投影中心会被拉到错误的真实中心。为了解决这个问题,我们提出了基于二部图匹配的约束来找到两个集合之间全局最小距离,同时满足一对一匹配原则。我们可以将这一问题形式化为一个最小权重匹配问题:
L B M = min X ∑ i , j d i s i j x i j , s . t . ∑ j x i j = 1 , ∑ i x i j = 1 , x i j ∈ { 0 , 1 } (6) \mathcal L_{BM} = \min_X \sum_{i,j} dis_{ij} x_{ij}, \ s.t. \ \sum_j x_{ij}=1, \sum_i x_{ij}=1, x_{ij} \in \{{0, 1}\} \tag{6} LBM=Xmini,j∑disijxij, s.t. j∑xij=1,i∑xij=1,xij∈{0,1}(6)
其中, X \boldsymbol X X是分配矩阵, x i j \boldsymbol x_{ij} xij表示集合 A \mathbf A A中的元素 i \boldsymbol i i和集合 B \mathbf B B中的元素 j \boldsymbol j j的匹配关系,D是距离矩阵,dij表示集合A中的元素i和集合B中的元素j的距离。论文用匈牙利算法来解决这个问题,时间复杂度是O(V2E)。总loss如下:
L B M V S c = L M S E + β × L B M (7) \mathcal L_{BMVSc} = \mathcal L_{MSE} + \beta \times \mathcal L_{BM} \tag{7} LBMVSc=LMSE+β×LBM(7)
实验效果:

如图,CDVSc存在多对一的匹配。
WDVSc——基于Wasserstein距离的视觉结构约束
理想情况下,如果投影和真实中心是紧凑而且准确的,上面的基于距离的二部图匹配可以达到全局最优。然而,这个假设并不总是成立,尤其是对于目标类的近似聚类中心,因为这些中心可能包含噪声而且并不足够准确。通过使用Wasserstein距离,用可变值的矩阵X而不是用固定值(0或1)的分配矩阵来表示两个点集的联合概率分布。这个目标形式化和公式6很像,但是X表示的是软联合概率值而不是固定值(0或1)。这篇论文中,采用了基于Sinkhorn迭代的熵正则化最优传输问题:
L
W
D
=
min
X
∑
i
,
j
d
i
s
i
j
x
i
j
−
ϵ
H
(
X
)
(8)
\mathcal L_{WD} = \min_{X} \sum_{i,j} dis_{ij}x_{ij} - \epsilon H(X) \tag{8}
LWD=Xmini,j∑disijxij−ϵH(X)(8)
其中,H(X)是矩阵的熵
H
(
X
)
=
−
∑
i
j
x
i
j
log
x
i
j
H(X) = -\sum_{ij}x_{ij}\log x_{ij}
H(X)=−∑ijxijlogxij,
ϵ
\epsilon
ϵ是正则化参数。X可以写成
X
=
d
i
a
g
{
u
}
K
d
i
a
g
{
v
}
X=diag\{u\}Kdiag\{v\}
X=diag{u}Kdiag{v},迭代过程交替优化u和v:
u
(
k
+
1
)
=
a
K
v
(
k
+
1
)
,
v
(
k
+
1
)
=
b
K
T
u
(
k
+
1
)
(9)
u^{(k+1)}=\frac {a} {Kv^{(k+1)}}, \qquad v^{(k+1)}=\frac {b} {K^Tu^{(k+1)}} \tag{9}
u(k+1)=Kv(k+1)a,v(k+1)=KTu(k+1)b(9)
其中,K是矩阵D算出来的核矩阵。最终loss如下:
L W D V S c = L M S E + β × L W D (10) \mathcal L_{WDVSc} = \mathcal L_{MSE} + \beta \times \mathcal L_{WD} \tag{10} LWDVSc=LMSE+β×LWD(10)
存在无关测试图片的真实场景
训练步骤如下:
步骤1: 因为源域数据是干净的,所以假设域漂移问题没有那么严重,我们先用VCL方法得到初始的未见类投影中心C。
步骤2: 视觉空间中每个源域类别的最远距离点对组成距离集合
D
\mathcal D
D。【直径集合】
步骤3: 选择可靠的图像 x(符合条件当且仅当存在一个未见类的中心,和它的距离小于距离集合中最大距离的一半)组合成目标域,在这个集合上做聚类。
步骤4: 分别执行CDVSc、BMVSc和WDVSc。
注意:这个max(D)/2就是目标域/未见类的半径,在半径范围内的,算作目标域样本。
Experiment
SS定量对比实验
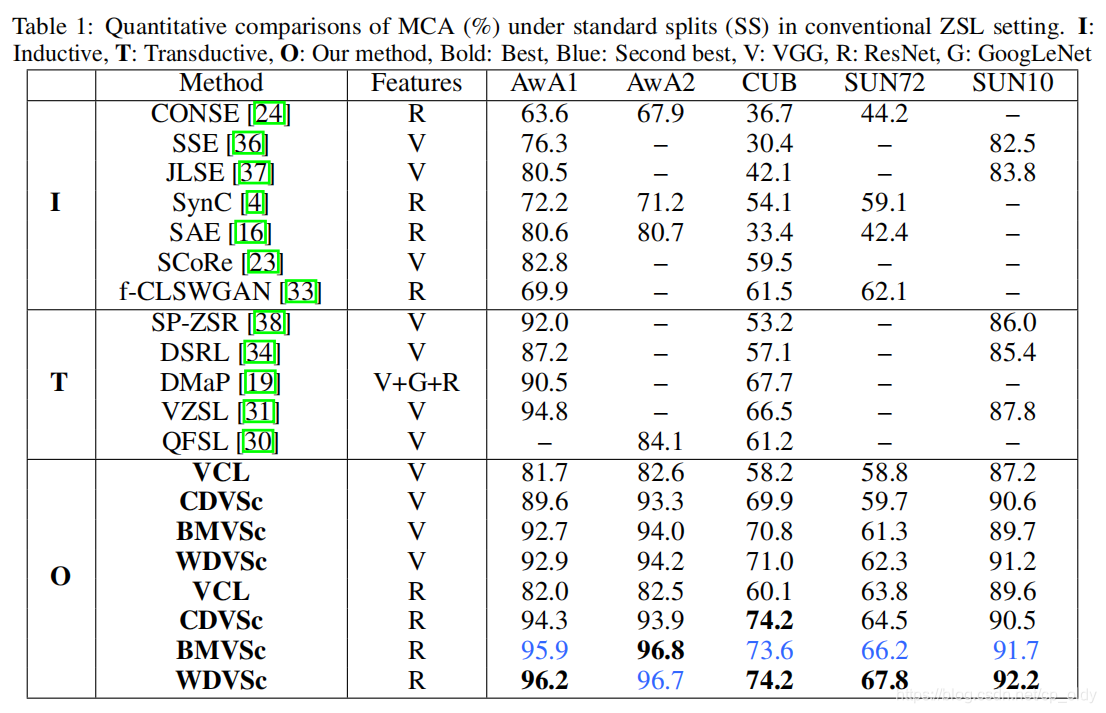
PS定量对比实验 && GZSL定量对比实验
测试集有无关图像的场景

怎么构造包含无关图像的测试集?
在AwA1中混入8K张aPY数据集的图片。Table 4展示了实验结果,使用过滤策略的训练过程比一般训练过程精度高。
定性实验及分析

错分类原因:
1) 错误类和正确类视觉特征太像:比如海豹seal和海象walrus
2) 标注错误:比如海豹spots属性,而海象没有,但是两个类都有斑点属性标注
思考:此时有斑点和没斑点的图像都能学到“斑点”这个属性,说明模型学的是某个“视觉特征”到“斑点”这个属性的映射
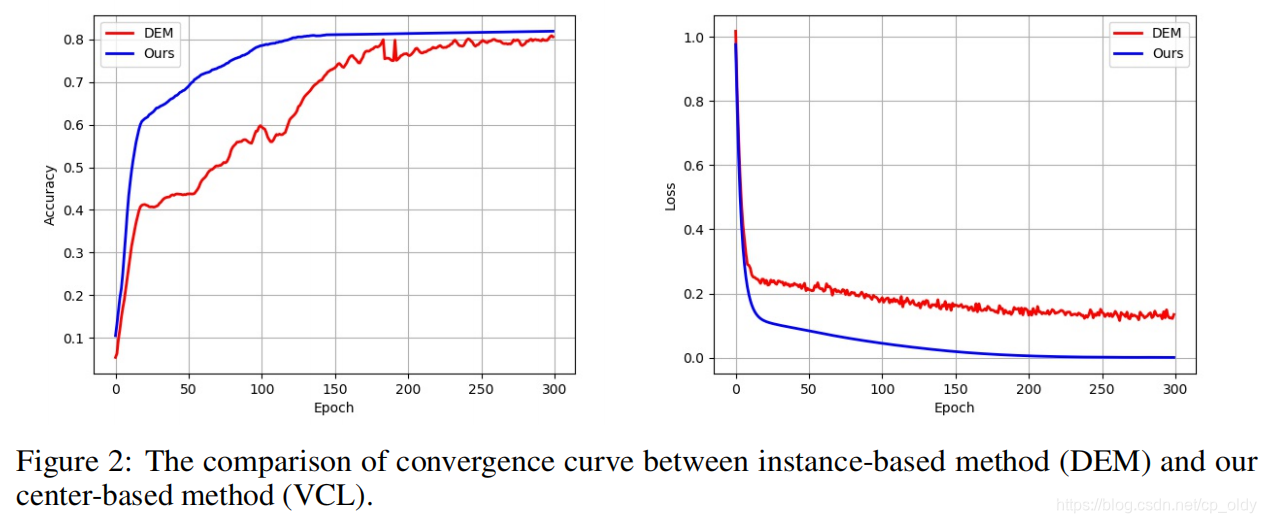
对齐类中心和对齐样本
VCL(蓝线)速度和精度都有优势
如果未见类多少个未知,怎么办?
如下表所示,在AwA2数据集上,如果知道是10个未知类,效果最好;如果不知道,可以设置成一个固定数量,这样就是在对齐超类中心,但是也是有效果的。

文中说,首先在语义空间和视觉空间都执行K-Means,然后用BMVSc和WDVSc来对齐这两个生成集合。有个疑问,视觉空间是直接做5聚类,那语义空间是先在属性空间做5聚类再投影吗?还是先做投影再做5聚类?
为什么选择视觉空间比语义空间作为分类空间好?
- 使用语义空间作为嵌入空间会加剧投影对象对原点的收缩程度。
- 更靠近原点的点更有可能成为中心。
从另一个角度来考虑:视觉到语义的映射会丢失信息,语义都视觉的映射会恢复信息。
问题
- 假设是未见类视觉特征可分,视觉结构约束有效,那么,针对不可分情况,怎么办?
CUB的可分性就不好,但是实验性能还可以,因为大部分类别的中心对齐添加视觉约束有效。 - 公式2和公式3,l2损失有平方,而欧式距离开根号?
参考博客,可以这么理解,对于loss,需要求梯度,如果有根号后,梯度的计算就变得复杂了。
论文传送门
论文
http://papers.nips.cc/paper/9188-transductive-zero-shot-learning-with-visual-structure-constraint
补充文件
https://proceedings.neurips.cc/paper/2019/file/5ca359ab1e9e3b9c478459944a2d9ca5-Supplemental.zip
代码
https://github.com/raywzy/VSC

















 429
429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









