




概述
是一种将高维数据(如文本、图像、音频)映射到低维空间的技术,其中每个数据点由实数构成的向量表示,这些向量在向量空间中的位置反映了数据的语义特征。这种技术广泛应用于自然语言处理和机器学习中,使得计算机能够理解和处理文本等数据。以下是关于Embedding模型的一些关键点:1
- 定义与用途:Embedding模型的主要目的是将高维数据(如文本)转化为低维的实数向量,这些向量在数学空间中的位置反映了数据的语义特征,使得计算机可以更容易地处理和分析这些数据。例如,在自然语言处理中,embedding可以将单词或句子转化为向量,这些向量的位置关系反映了单词或句子之间的语义关系。
- 实现方式:Embedding模型的实现通常依赖于深度学习技术,如神经网络。这些模型通过训练学习数据的特征,生成能够表示数据语义的向量。例如,Word2Vec模型就是一种常用的生成词向量的方法,它通过预测文本中的下一个词来学习单词的语义特征。
- 应用示例:在实际应用中,如文本分类或情感分析任务中,可以通过训练一个Embedding模型来将文本转化为向量表示,然后利用这些向量进行进一步的分类或分析。此外,SentenceTransformer库提供了一种方便的方式来训练和使用针对句子的Embedding模型。
总体来说,Embedding模型是现代数据分析和机器学习中的一个关键技术,它使得计算机能够理解和处理复杂的数据结构,如文本和图像,从而推动了人工智能技术在多个领域的应用和发展。
模型调研
与大模型类似,Embedding也是使用模型来实现的,只不过Embedding模型更为轻量。一般都在2G以内。经调研(附录[6~10]),发现以下模型对中文的支持效果较好,且已经开源方便本地私有化部署
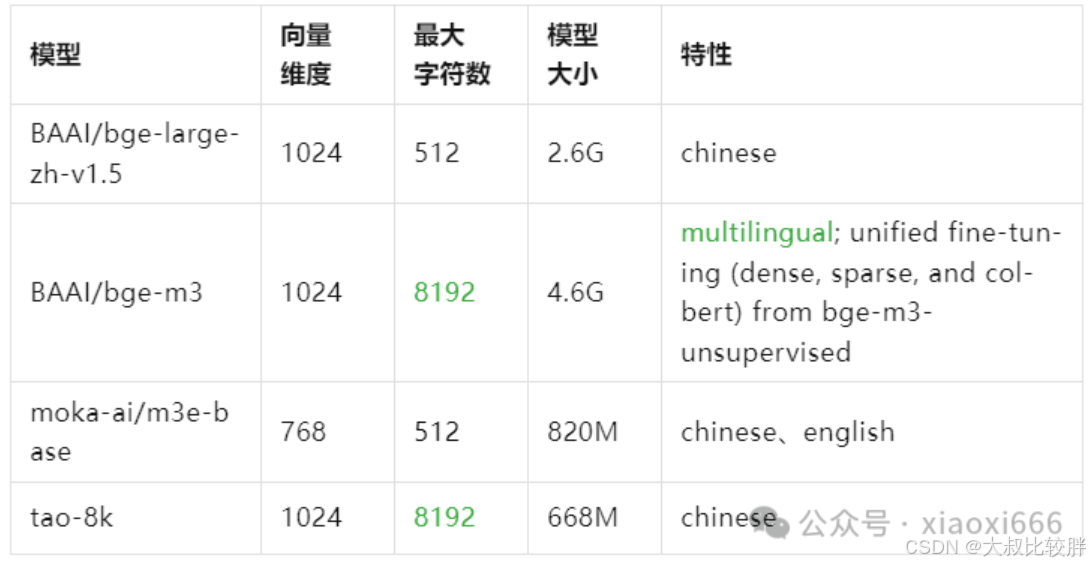
可以看得出m3模型的优势是支持多语言,并且字符数扩展到了8192,这意味着BGE-M3能够高效地处理长篇幅的文档,满足对于长文档检索的需求。


















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











