







 超级会员免费看
超级会员免费看
 本文介绍了在大数据处理场景中,Flink如何利用KeyedStream进行常见的滚动聚合操作,如最大值、最小值和求和。通过实例展示了读取文件、数据分组、聚合API的使用,并解释了滚动聚合的工作原理。
本文介绍了在大数据处理场景中,Flink如何利用KeyedStream进行常见的滚动聚合操作,如最大值、最小值和求和。通过实例展示了读取文件、数据分组、聚合API的使用,并解释了滚动聚合的工作原理。
前言
在很多业务场景下,我们需要对读取到的数据根据业务字段做聚合、统计甚至计算等操作,因此flink提供了基于KeyedStream 的丰富的滚动聚合算子满足多种业务场景下的聚合统计需求
下面来看看几种常用的滚动聚合算子API操作
环境准备
1、准备一个外部文件,用于程序读取
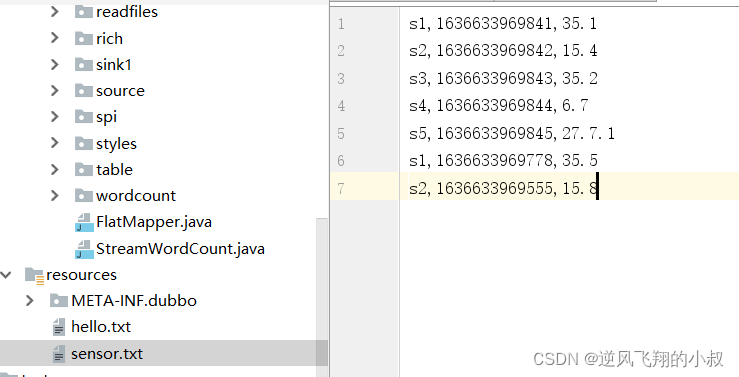
这里在工程的resources目录下,准备一个sensor.txt文件,内容如下
编码实现
需求说明,读取上述文件中的每行数据,按照第一个字段分组,求第三个字段的最大值
import com.congge.source.SensorReading;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apa
 订阅专栏 解锁全文
订阅专栏 解锁全文



















 588
588

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











