







调度器基础
调度
调度就是按照某种调度的算法设计,从进程的就绪队列当中选取进程分配CPU,主要是协调对CPU等相关资源的使用。进程调度目的:最大限度利用CPU时间。
调度器
Linux内核中用来安排调度进程(一段程序的执行过程)执行的模块称为**调度器(Scheduler),它可以切换进程状态(Process status)**。比如:执行、可中断睡眠、不可中断睡眠、退出、暂停等。
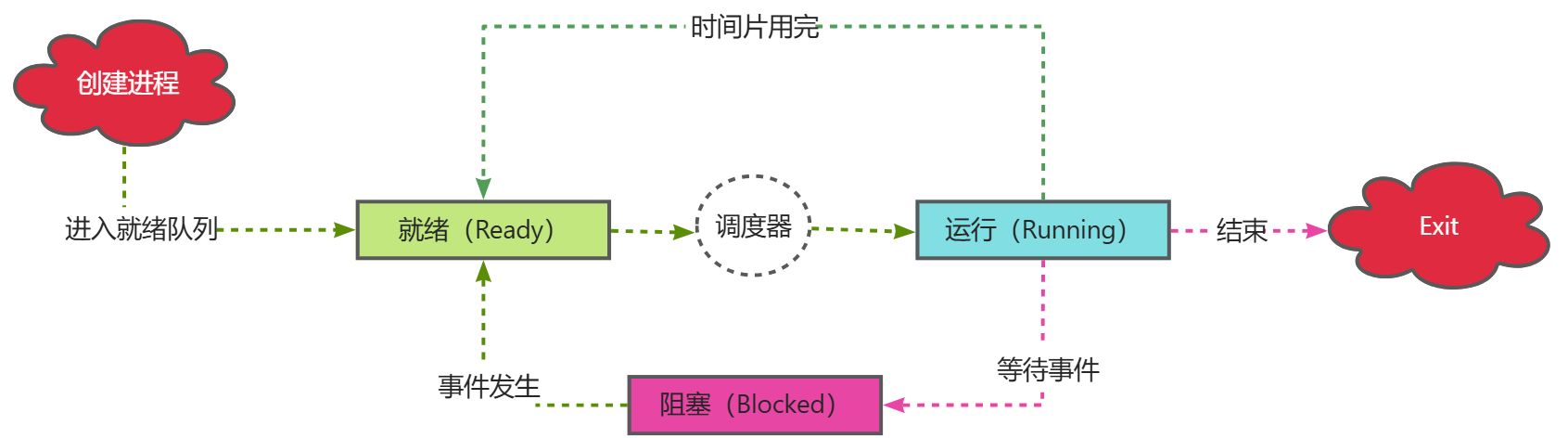
调度器相当于CPU中央处理器的管理员,主要负责完成做两件事情:
- 选择某些就绪进程来执行。
- 打断某些执行的进程,让它们变为就绪状态。
抢占式调度器
如果调度器支持将进程从就绪状态切换到执行状态,同时支持将进程从执行状态切换到就绪状,称该调度器为**抢占式调度器**。
调度器实现基础
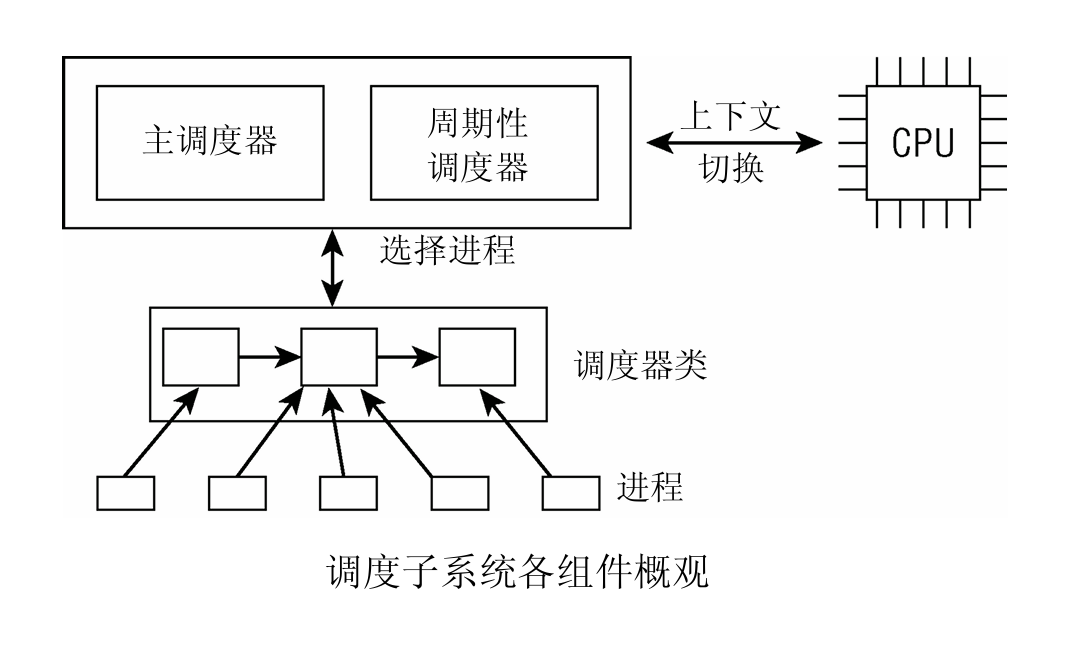
调度器调度过程中,有两个核心概念:调度类和调度队列。它们是调度器实现的基础。
为了方便添加新的调度策略,Linux内核抽象了调度类sched_class,定义了5种调度类,每种调度类的优先级不同,每种调度类是一个全局变量。每个调度类对应一个运行队列。
调度器进行调度时,按照调度类进行调度,从该调度类对应的运行队列中选取进程进程调度。
调度类
调度策略和调度类是怎么关联上的?
同一个调度类,可以有不同的调度策略,如SCHED_FIFO,SCHED_RR。
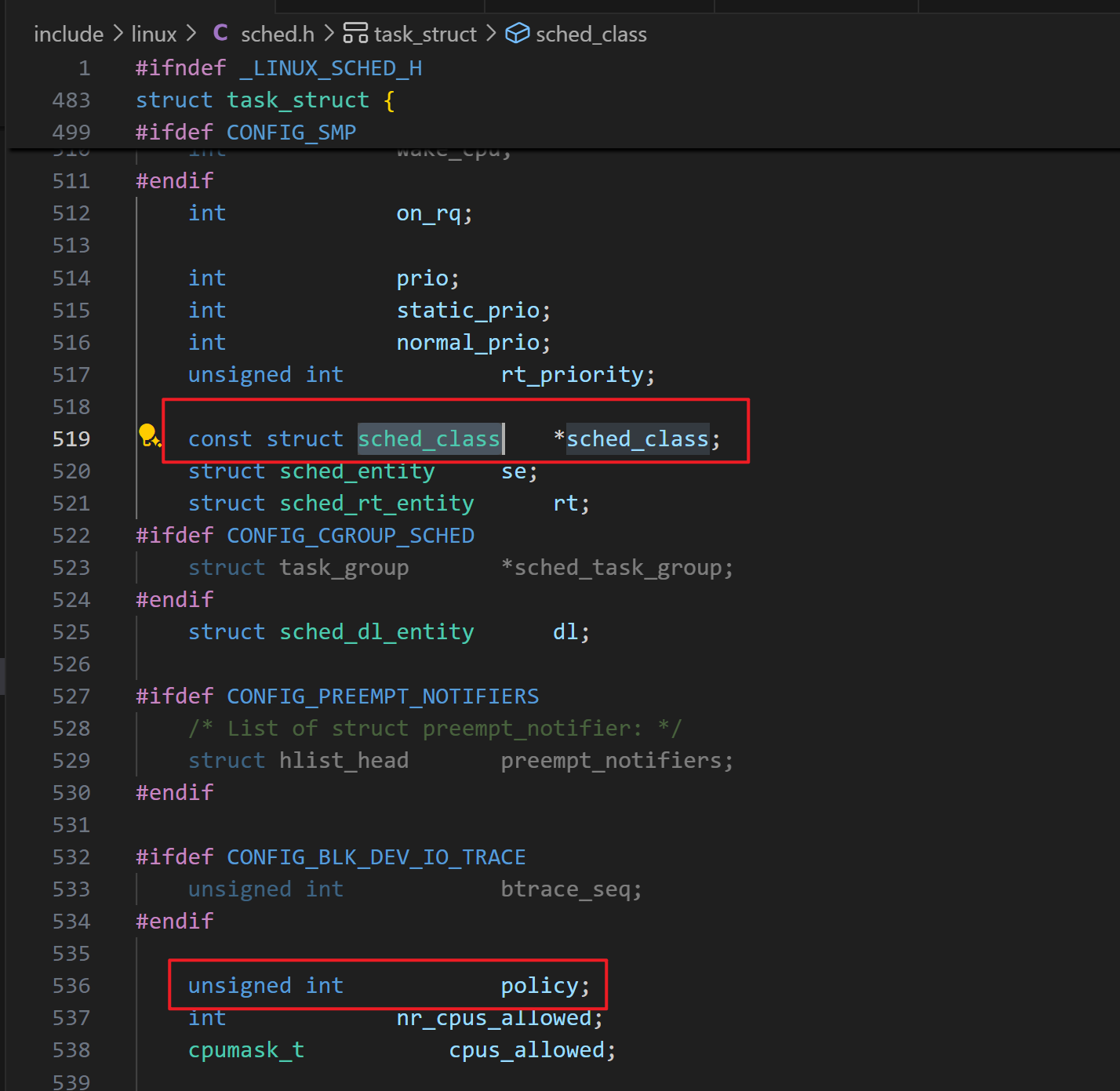
调度类是Linux调度器的策略引擎,定义了如何管理进程、分配CPU时间以及选择下一个运行任务的规则。它们通过一组函数指针提供统一的接口,使内核能够支持多种调度策略共存。
内核目前实现了5 种调度类,如下表所示。
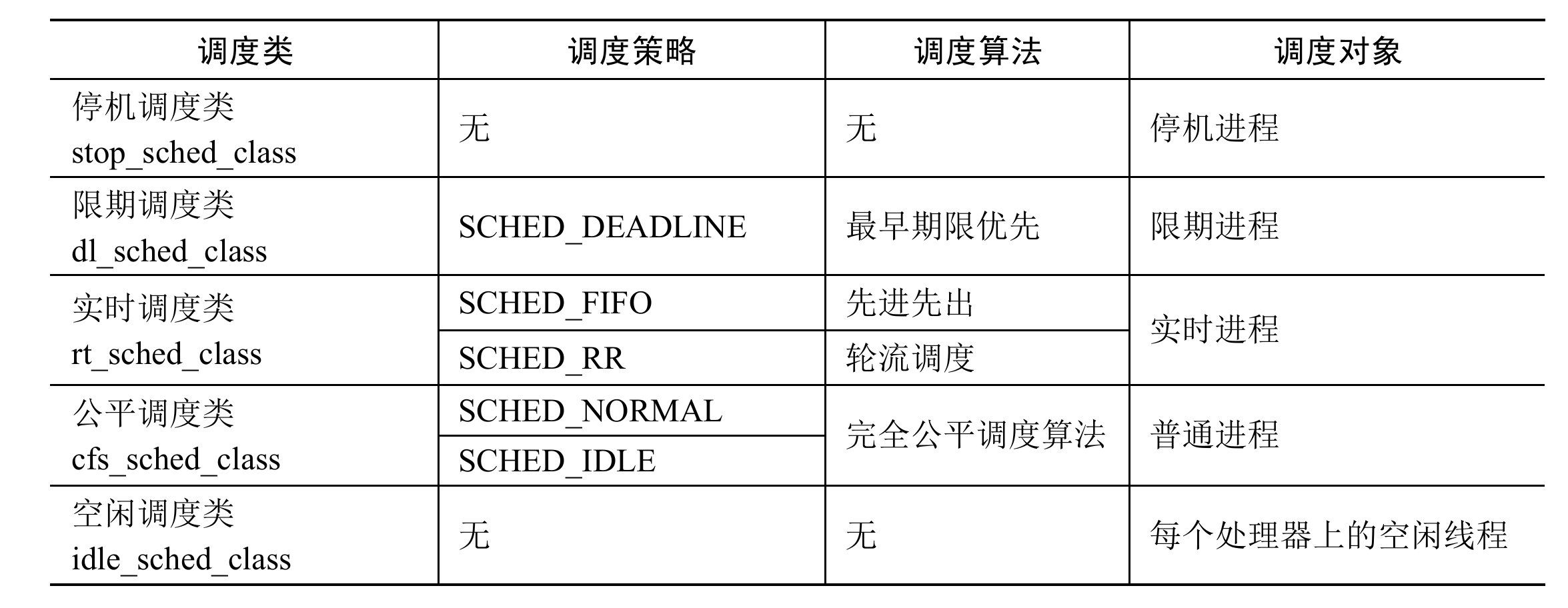
这5种调度类的优先级从高到低依次为:停机调度类、限期调度类、实时调度类、公 平调度类和空闲调度类。
这5中调度类分别定义了一个全局变量,通过链表链接起来。
extern const struct sched_class stop_sched_class;
extern const struct sched_class dl_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;
数据结构
struct sched_class {
const struct sched_class *next; // 指向下一个调度类(优先级链表)
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*yield_task) (struct rq *rq);
bool (*yield_to_task) (struct rq *rq, struct task_struct *p, bool preempt);
void (*check_preempt_curr) (struct rq *rq, struct task_struct *p, int flags);
/*
* It is the responsibility of the pick_next_task() method that will
* return the next task to call put_prev_task() on the @prev task or
* something equivalent.
*
* May return RETRY_TASK when it finds a higher prio class has runnable
* tasks.
*/
struct task_struct * (*pick_next_task) (struct rq *rq,
struct task_struct *prev,
struct rq_flags *rf);
void (*put_prev_task) (struct rq *rq, struct task_struct *p);
#ifdef CONFIG_SMP
int (*select_task_rq)(struct task_struct *p, int task_cpu, int sd_flag, int flags);
void (*migrate_task_rq)(struct task_struct *p);
void (*task_woken) (struct rq *this_rq, struct task_struct *task);
void (*set_cpus_allowed)(struct task_struct *p,
const struct cpumask *newmask);
void (*rq_online)(struct rq *rq);
void (*rq_offline)(struct rq *rq);
#endif
void (*set_curr_task) (struct rq *rq);
void (*task_tick) (struct rq *rq, struct task_struct *p, int queued);
void (*task_fork) (struct task_struct *p);
void (*task_dead) (struct task_struct *p);
/*
* The switched_from() call is allowed to drop rq->lock, therefore we
* cannot assume the switched_from/switched_to pair is serliazed by
* rq->lock. They are however serialized by p->pi_lock.
*/
void (*switched_from) (struct rq *this_rq, struct task_struct *task);
void (*switched_to) (struct rq *this_rq, struct task_struct *task);
void (*prio_changed) (struct rq *this_rq, struct task_struct *task,
int oldprio);
unsigned int (*get_rr_interval) (struct rq *rq,
struct task_struct *task);
void (*update_curr) (struct rq *rq);
#define TASK_SET_GROUP 0
#define TASK_MOVE_GROUP 1
#ifdef CONFIG_FAIR_GROUP_SCHED
void (*task_change_group) (struct task_struct *p, int type);
#endif
};
调度类关键方法解析
**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">enqueue_task</font>**- 将任务加入调度类对应的运行队列
- CFS:将
**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">sched_entity</font>**插入红黑树 - RT:将任务加入优先级队列
- CFS:将
- 将任务加入调度类对应的运行队列
**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">dequeue_task</font>**- 从运行队列移除任务(如任务阻塞或退出)
**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">pick_next_task</font>**- 核心选择逻辑:从队列中选择下一个运行任务
- CFS:选择红黑树最左侧(最小vruntime)任务
- RT:选择最高优先级队列的首任务
- 核心选择逻辑:从队列中选择下一个运行任务
**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">task_tick</font>**- 处理时间片更新和抢占检查
- CFS:更新
**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">vruntime</font>**,检查是否需要调度 - RT:减少时间片,检查是否需轮转(RR策略)
- CFS:更新
- 处理时间片更新和抢占检查
调度类与运行队列的关系

调度类的优先级链
调度器通过静态优先级链遍历调度类:
// 内核代码:kernel/sched/sched.h
extern const struct sched_class stop_sched_class;
extern const struct sched_class dl_sched_class;
extern const struct sched_class rt_sched_class;
extern const struct sched_class fair_sched_class;
extern const struct sched_class idle_sched_class;
// 优先级链:stop → dl → rt → fair → idle
stop_sched_class.next = &dl_sched_class;
dl_sched_class.next = &rt_sched_class;
rt_sched_class.next = &fair_sched_class;
fair_sched_class.next = &idle_sched_class;
调度流程:
- 从
**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">stop_sched_class</font>**(最高优先级调度类)开始调用对应调度类的**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">pick_next_task</font>** - 若返回
**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">NULL</font>**,则继续调用下一级调度类 - 直到找到可运行任务或执行
**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">idle</font>**
调度类设计哲学
- 策略与机制分离
- 调度器核心只处理通用逻辑(如上下文切换)
- 调度类实现具体策略(如CFS/RT)
- 可扩展性
- 新增调度策略只需实现新的
**<font style="color:rgb(64, 64, 64);background-color:rgb(236, 236, 236);">sched_class</font>** - 无需修改核心调度器(如Deadline类后来新增)
- 新增调度策略只需实现新的
- 优先级保障
- 高优先级调度类天然抢占低优先级
- 实时任务可立即抢占普通进程
实时调度类(rt_sched_class)
实时调度类为每个调度优先级维护一个队列,其代码如下:
/*
* This is the priority-queue data structure of the RT scheduling class:
*/
struct rt_prio_array {
DECLARE_BITMAP(bitmap, MAX_RT_PRIO+1); /* include 1 bit for delimiter */
struct list_head queue[MAX_RT_PRIO]; // MAX_RT_PRIO = 100
};
/* Real-Time classes' related field in a runqueue: */
struct rt_rq {
struct rt_prio_array active;
unsigned int rt_nr_running;
unsigned int rr_nr_running;
...
};
位图bitmap用来快速查找第一个非空队列。数组queue的下标是实时进程的调度优先级,下标越小,优先级越高。
每次调度,先找到优先级最高的第一个非空队列,然后从队列中选择第一个进程。 使用先进先出调度策略`SCHED_FIFO`的进程没有时间片,如果没有优先级更高的进程,并且它不主动让出处理器,那么它将一直霸占处理器。 使用轮流调度策略`SCHED_RR`的进程有时间片,用完时间片以后,进程加入队列的尾部。默认的时间片是5毫秒,可以通过文件“/proc/sys/kernel/sched_rr_timeslice_ms”修改时间片。
核心特性
| 特性 | 说明 |
|---|---|
| 优先级范围 | 1(最低)~ 99(最高),数值越大优先级越高 |
| 调度策略 | SCHED_FIFO(先进先出)和 SCHED_RR(时间片轮转) |
| 抢占能力 | 可抢占所有低优先级任务(包括普通CFS任务) |
| 时间片机制 | 仅SCHED_RR使用时间片,SCHED_FIFO无时间片限制 |
| 队列结构 | 每个CPU维护100个优先级队列(0~99),每个队列是FIFO或RR链表 |
调度策略
SCHED_FIFO (先进先出)
- 行为:
- 任务持续运行直至:① 主动让出CPU ② 被更高优先级任务抢占 ③ 阻塞/退出
- 同优先级任务严格按入队顺序执行(无时间片概念)
- 适用场景:
// 示例:设置进程为SCHED_FIFO,优先级80
struct sched_param param = { .sched_priority = 80 };
sched_setscheduler(pid, SCHED_FIFO, ¶m);
- 紧急中断处理
- 关键控制任务(如机器人运动控制)
SCHED_RR (轮转调度)
- 行为:
- 默认时间片:100ms(可通过
/proc/sys/kernel/sched_rr_timeslice_ms调整) - 时间片耗尽后,任务移到同优先级队列尾部
- 仍可被高优先级任务抢占
- 默认时间片:100ms(可通过
- 适用场景:
# 查看RR默认时间片(单位ms)
cat /proc/sys/kernel/sched_rr_timeslice_ms
- 周期性数据采集
- 流媒体处理(音视频编码)
核心数据结构
实时运行队列 (rt_rq)
struct rt_rq {
struct rt_prio_array active; // 活跃任务数组(100个优先级队列)
unsigned int rt_nr_running; // 就绪任务数
// ...
};
优先级数组 (rt_prio_array)
struct rt_prio_array {
DECLARE_BITMAP(bitmap, MAX_RT_PRIO+1); // 位图标记非空队列
struct list_head queue[MAX_RT_PRIO]; // 100个链表(每个优先级一个)
};
- 位图优化:快速定位最高非空优先级(如
find_first_bit(bitmap))
实时任务控制 (task_struct)
struct task_struct {
// ...
// 实时任务特有字段
struct sched_rt_entity rt;
unsigned int rt_priority; // 实时优先级 (1-99)
const struct sched_class *sched_class; // 指向rt_sched_class
// ...
};
调度类方法实现
实时调度类定义:
const struct sched_class rt_sched_class = {
.next = &fair_sched_class, // 下一级是CFS
.enqueue_task = enqueue_task_rt,
.dequeue_task = dequeue_task_rt,
.pick_next_task = pick_next_task_rt,
.task_tick = task_tick_rt,
// ...
};
调度场景示例
场景1:高优先级FIFO任务抢占

场景2:RR任务时间片轮转

实时任务管理工具
- 命令行工具:
# 设置实时优先级
chrt -f 90 /path/to/program # SCHED_FIFO优先级90
chrt -r 50 /path/to/program # SCHED_RR优先级50
# 查看任务调度策略
chrt -p 1234 # 查看PID 1234的策略
公平调度类(faired_sched_class)
公平调度类使用完全公平调度(Completely Fair Scheduling)算法。完全公平调度算法引入了虚拟运行时间的概念:`虚拟运行时间 = 实际运行时间 × nice 0 对应的权重 / 进程nice值对应的权重`
nice 值和权重的对应关系如下(nice值越小,权重越大):
/*
* Nice levels are multiplicative, with a gentle 10% change for every
* nice level changed. I.e. when a CPU-bound task goes from nice 0 to
* nice 1, it will get ~10% less CPU time than another CPU-bound task
* that remained on nice 0.
*
* The "10% effect" is relative and cumulative: from _any_ nice level,
* if you go up 1 level, it's -10% CPU usage, if you go down 1 level
* it's +10% CPU usage. (to achieve that we use a multiplier of 1.25.
* If a task goes up by ~10% and another task goes down by ~10% then
* the relative distance between them is ~25%.)
*/
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
nice 0 对应的权重是 1024,nice n-1 的权重大约是 nice n 权重的 1.25 倍。
使用空闲调度策略(SCHED_IDLE)的普通进程的权重是 3(比nice值19的权重还要小),nice 值对权重没有影响,定义如下:
#define WEIGHT_IDLEPRIO 3
完全公平调度算法使用红黑树把进程按虚拟运行时间从小到大排序,每次调度时选择 虚拟运行时间最小的进程。
显然,进程的静态优先级越高,权重越大,在实际运行时间相同的情况下,虚拟运行时间越短,进程累计的虚拟运行时间增加得越慢,在红黑树中向右移动的速度越慢,被调度器选中的机会越大,被分配的运行时间相对越多。
调度器选中进程以后分配的时间片是多少呢?
调度周期:在某个时间长度可以保证运行队列中的每个进程至少运行一次,我们把这个时间长度称为调度周期。
** 调度最小粒度**:为了防止进程切换太频繁,进程被调度后应该至少运行一小段时间,我们把这个时间长度称为调度最小粒度。默认值是0.75毫秒,可以通过文件/proc/sys/kernel/sched_min_granularity_ns调整。
进程的时间片的计算公式如下:
进程的时间片=(调度周期×进程的权重 / 运行队列中所有进程的权重总和)
按照这个公式计算出来的时间片称为理想的运行时间。
设计哲学
- 完全公平性:模拟"理想多任务处理器",让 N 个任务在任意相等时间段内各获得 1/N 的CPU 时间
- 动态优先级:通过
vruntime自动惩罚 CPU 贪婪型任务,奖励 I/O 密集型任务 - 低延迟:最小调度粒度(0.75ms)保证交互式任务响应性
- 层级公平:支持 cgroup 组调度,实现容器间资源分配
核心数据结构
a) 调度实体(sched_entity)
struct sched_entity {
struct load_weight load; // 权重(优先级相关)
struct rb_node run_node; // 红黑树节点
u64 vruntime; // 关键:虚拟运行时间
u64 exec_start; // 本次运行开始时间
u64 sum_exec_runtime; // 总实际运行时间
// ...
};
- 权重计算:权重由 nice 值(-20~19)映射,NICE_0_LOAD=1024,每级相差约 10%
static const int prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
b) CFS 运行队列(cfs_rq)
struct cfs_rq {
struct rb_root_cached tasks_timeline; // 红黑树根节点(按vruntime排序)
struct sched_entity *curr; // 当前运行任务
struct sched_entity *next; // 下一个候选任务(用于抢占优化)
unsigned int nr_running; // 就绪任务数
u64 min_vruntime; // 队列最小vruntime(单调递增)
struct rb_node *rb_leftmost; // 红黑树最左节点
// ...
};
核心算法:虚拟时间(vruntime)
- 计算公式:
vruntime += 实际运行时间 × (NICE_0_LOAD / 权重)
其中 NICE_0_LOAD = 1024(nice=0 的基准权重) - 公平性实现:
- 高优先级(低nice)任务:权重高 → vruntime 增长慢 → 更易被调度
- 低优先级(高nice)任务:权重低 → vruntime 增长快 → 调度机会少
- 红黑树排序:所有任务按 vruntime 从小到大排序,调度器总是选择 vruntime 最小的任务(最左节点)
调度类方法实现
公平调度类定义(kernel/sched/fair.c):
const struct sched_class fair_sched_class = {
.next = &idle_sched_class, // 下一级是空闲调度
.enqueue_task = enqueue_task_fair,
.dequeue_task = dequeue_task_fair,
.pick_next_task = pick_next_task_fair,
.task_tick = task_tick_fair,
.set_curr_task = set_curr_task_fair,
// ...
};
监控工具
# 查看进程调度信息
cat /proc/$PID/sched
# 性能分析
perf sched record -- sleep 1
perf sched map
运行队列
每个处理器有一个运行队列,用于保存处于**可运行状态(TASK_RUNNING)**的进程,结构体是rq,定义的全局变量如下:
DEFINE_PER_CPU_SHARED_ALIGNED(struct rq, runqueues);
各个活动进程只出现在一个运行队列中,在多个CPU上同时运行一个进程是不可能的。
运行队列是全局调度器许多操作的起点。但进程并不是由运行队列的成员直接管理的! 这是各个调度器类的职责,因此在运行队列中嵌入了特定于调度器类的子运行队列。
struct rq {
...
struct cfs_rq cfs;
struct rt_rq rt;
struct dl_rq dl;
struct task_struct *curr, *idle, *stop;
...
};
结构体rq中嵌入了公平运行队列cfs、实时运行队列rt和限期运行队列dl,停机调度类和空闲调度类在每个处理器上只有一个内核线程,不需要运行队列,直接定义成员stop和idle分别指向迁移线程和空闲线程。
参考资料
- Professional Linux Kernel Architecture,Wolfgang Mauerer
- Linux内核深度解析,余华兵
- Linux设备驱动开发详解,宋宝华
- linux kernel 4.12


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









