






页交换概念
系统物理内存不足时,内核需要进行页回收;页交换(swap)是页回收的主要方法之一;
页交换的原理是:当内存不足的时候,把最近很少访问的没有存储设备支持的物理页的数据暂时保存到交换区,释放内存空间,当交换区中存储的页被访问的时候,再把数据从交换区读到内存中;
交换区可以是一个磁盘分区,也可以是存储设备上的一个文件;使用磁盘分区和文件作为交换区的具体方法,可以查阅相关资料;
可以用sudo swapon --show或者cat /proc/swaps查询系统中的swap分区;

可以使用sudo fdisk -l查询系统中的所有分区;
目前常用的存储设备是:机械硬盘、固态硬盘和NAND闪存;
固态硬盘使用NAND闪存作为存储介质;NAND闪存的特点是:写入数据之前需要把擦除快擦除,每个擦除块的擦除次数有限,范围是105~106,频繁地写数据会缩短闪存地寿命;
所以,如果设备使用固态硬盘或NAND闪存存储数据,不适合启用交换区;如果设备使用机械硬盘存储数据,可以启用交换区;
zswap
交换区的缺点是读写速度慢,影响程序的执行性能;为了缓解这个问题,内核3.11版本引入了zswap,它是交换页的轻量级压缩缓存;zswap把准备换出的页压缩到动态分配的内存池,仅当压缩缓存的大小达到限制时才会把压缩缓存里面的页写到交换区;swap以消耗CPU周期为代价,大幅度减少读写交换区的次数,带来了重大的性能提升,因为解压缩比从交换区读更快;
编译内核时需要开启配置宏CONFIG_ZSWAP。
技术原理
数据结构
交换区格式
交换区的第一页是交换区首部,内核使用数据结构swap_header描述交换区首部:
/*
* Magic header for a swap area. The first part of the union is
* what the swap magic looks like for the old (limited to 128MB)
* swap area format, the second part of the union adds - in the
* old reserved area - some extra information. Note that the first
* kilobyte is reserved for boot loader or disk label stuff...
*
* Having the magic at the end of the PAGE_SIZE makes detecting swap
* areas somewhat tricky on machines that support multiple page sizes.
* For 2.5 we'll probably want to move the magic to just beyond the
* bootbits...
*/
union swap_header {
struct {
char reserved[PAGE_SIZE - 10];
char magic[10]; /* SWAP-SPACE or SWAPSPACE2 */
} magic;
struct {
char bootbits[1024]; /* Space for disklabel etc. */
__u32 version;
__u32 last_page;
__u32 nr_badpages;
unsigned char sws_uuid[16];
unsigned char sws_volume[16];
__u32 padding[117];
__u32 badpages[1];
} info;
};
- mkswap - 创建swap时,在设备第一页写入swap_header
- swapon - 激活swap时,读取第一页的swap_header并验证magic和元数据
- 每个交换设备(分区或文件)都有一个swap_header
交换区信息
内核定义了交换区信息数组swap_info,每个数组项存储一个交换区的信息。
struct swap_info_struct *swap_info[MAX_SWAPFILES];
enum {
SWP_USED = (1 << 0), /* is slot in swap_info[] used? */
SWP_WRITEOK = (1 << 1), /* ok to write to this swap? */
SWP_DISCARDABLE = (1 << 2), /* blkdev support discard */
SWP_DISCARDING = (1 << 3), /* now discarding a free cluster */
SWP_SOLIDSTATE = (1 << 4), /* blkdev seeks are cheap */
SWP_CONTINUED = (1 << 5), /* swap_map has count continuation */
SWP_BLKDEV = (1 << 6), /* its a block device */
SWP_FILE = (1 << 7), /* set after swap_activate success */
SWP_AREA_DISCARD = (1 << 8), /* single-time swap area discards */
SWP_PAGE_DISCARD = (1 << 9), /* freed swap page-cluster discards */
SWP_STABLE_WRITES = (1 << 10), /* no overwrite PG_writeback pages */
/* add others here before... */
SWP_SCANNING = (1 << 11), /* refcount in scan_swap_map */
};
/*
* The in-memory structure used to track swap areas.
*/
struct swap_info_struct {
unsigned long flags; /* SWP_USED etc: see above */
signed short prio; /* swap priority of this type */
struct plist_node list; /* entry in swap_active_head */
struct plist_node avail_list; /* entry in swap_avail_head */
signed char type; /* strange name for an index */
unsigned int max; /* extent of the swap_map */
unsigned char *swap_map; /* vmalloc'ed array of usage counts */
struct swap_cluster_info *cluster_info; /* cluster info. Only for SSD */
struct swap_cluster_list free_clusters; /* free clusters list */
unsigned int lowest_bit; /* index of first free in swap_map */
unsigned int highest_bit; /* index of last free in swap_map */
unsigned int pages; /* total of usable pages of swap */
unsigned int inuse_pages; /* number of those currently in use */
unsigned int cluster_next; /* likely index for next allocation */
unsigned int cluster_nr; /* countdown to next cluster search */
struct percpu_cluster __percpu *percpu_cluster; /* per cpu's swap location */
struct swap_extent *curr_swap_extent;
struct swap_extent first_swap_extent;
struct block_device *bdev; /* swap device or bdev of swap file */
struct file *swap_file; /* seldom referenced */
unsigned int old_block_size; /* seldom referenced */
#ifdef CONFIG_FRONTSWAP
unsigned long *frontswap_map; /* frontswap in-use, one bit per page */
atomic_t frontswap_pages; /* frontswap pages in-use counter */
#endif
spinlock_t lock; /*
* protect map scan related fields like
* swap_map, lowest_bit, highest_bit,
* inuse_pages, cluster_next,
* cluster_nr, lowest_alloc,
* highest_alloc, free/discard cluster
* list. other fields are only changed
* at swapon/swapoff, so are protected
* by swap_lock. changing flags need
* hold this lock and swap_lock. If
* both locks need hold, hold swap_lock
* first.
*/
struct work_struct discard_work; /* discard worker */
struct swap_cluster_list discard_clusters; /* discard clusters list */
};
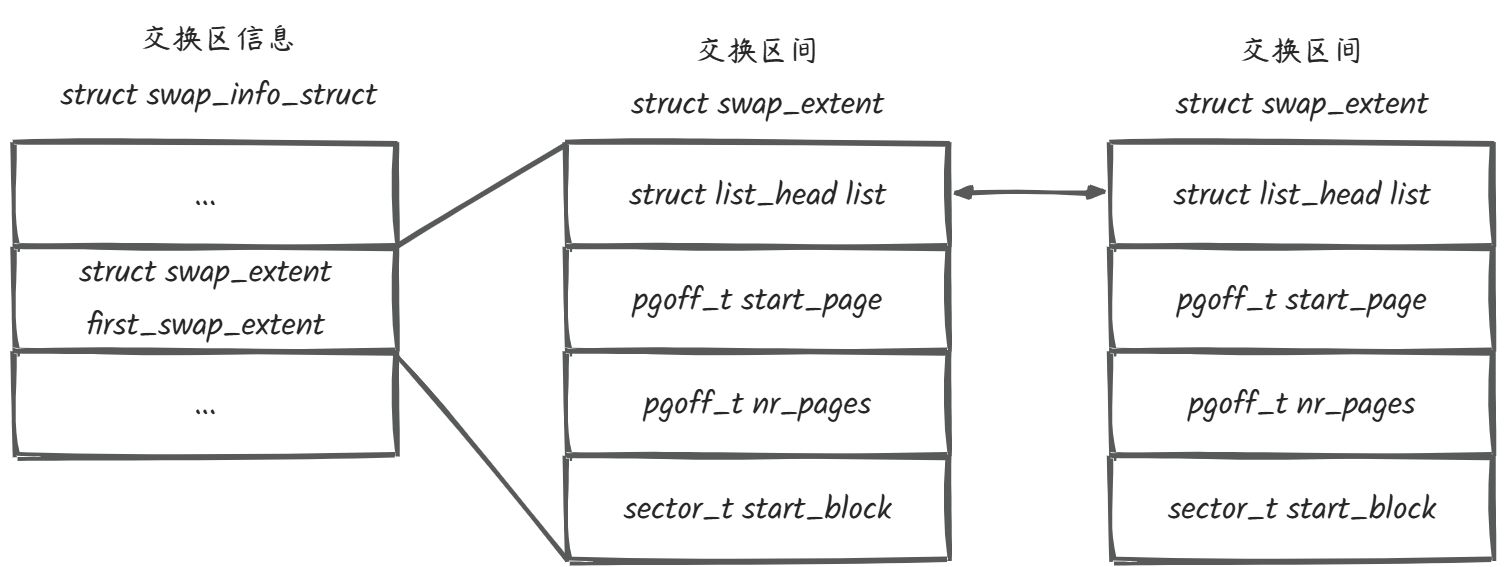
交换区间
/*
* A swap extent maps a range of a swapfile's PAGE_SIZE pages onto a range of
* disk blocks. A list of swap extents maps the entire swapfile. (Where the
* term `swapfile' refers to either a blockdevice or an IS_REG file. Apart
* from setup, they're handled identically.
*
* We always assume that blocks are of size PAGE_SIZE.
*/
struct swap_extent {
struct list_head list; /* swap extent list */
pgoff_t start_page; /* 连续的页数 */
pgoff_t nr_pages; /* swap entry 开始页号 */
sector_t start_block; /* 磁盘起始扇区 */
};
struct swap_info_struct {
...
struct swap_extent *curr_swap_extent;
struct swap_extent first_swap_extent;
...
};
** 交换区间(swap extent)**用来把交换区的连续槽位映射到连续的磁盘块。curr_swap_extent和first_swap_extent, 用于描述 swap 空间在磁盘上的分布情况。
交换区可以是一个磁盘分区,也可以是存储设备上的一个文件;
如果交换区是磁盘分区,因为磁盘分区的块是连续的,所以只需要一个交换区间。
如果交换区是文件, 因为文件对应的磁盘块不一定是连续的,所以对于每个连续的磁盘块范围,需要使用一个交换区间来存储交换区的连续槽位和磁盘块范围的映射关系。
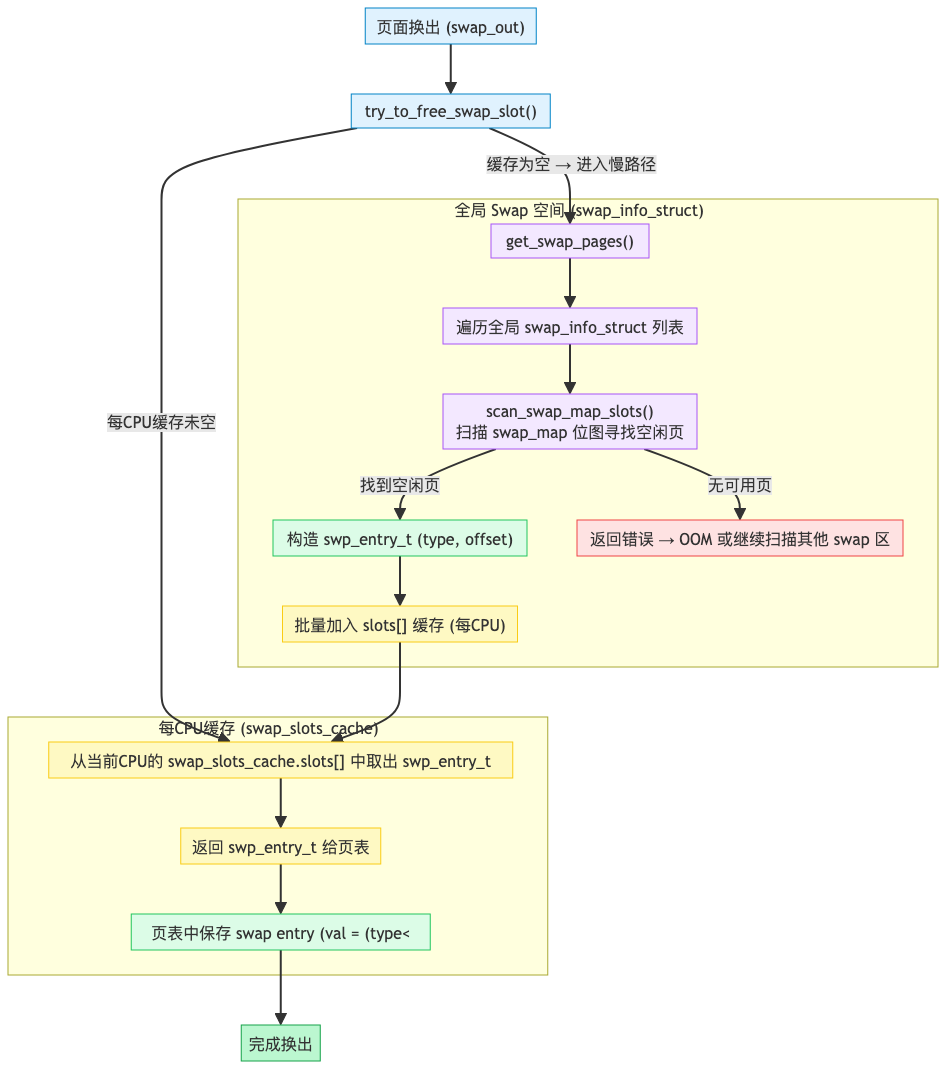
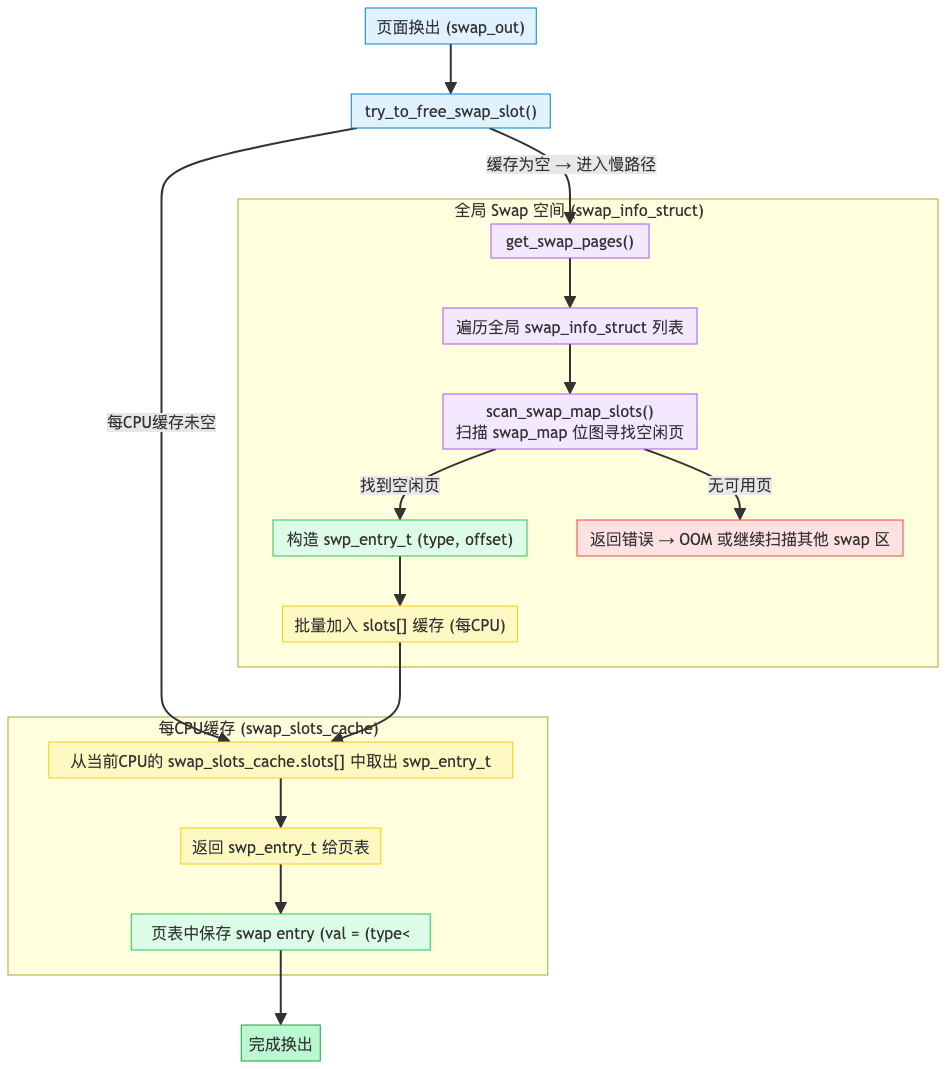
交换槽位缓存
为了加快为换出页分配交换槽位的速度,每个处理器有一个交换槽位缓存swp_slots。 避免所有 CPU 都去全局变量swap_info中分配 swap entry, 减少全局锁竞争,提高并发性能。
struct swap_slots_cache {
bool lock_initialized;
struct mutex alloc_lock; /* protects slots, nr, cur */
swp_entry_t *slots;
int nr;
int cur;
spinlock_t free_lock; /* protects slots_ret, n_ret */
swp_entry_t *slots_ret;
int n_ret;
};
// 全局每CPU变量
static DEFINE_PER_CPU(struct swap_slots_cache, swp_slots);
- 分配时优先从本地 cache 取;
- 如果本地 cache 用完,再批量从全局 swap 空间取;
- 释放时也可批量归还,避免频繁全局操作。
交换项
struct swp_entry_t 存储换出页在交换区中的位置,称为交换项。 在页表中表示一个 交换条目(swap entry),即一页数据在 swap 空间的位置。
/*
* A swap entry has to fit into a "unsigned long", as the entry is hidden
* in the "index" field of the swapper address space.
*/
typedef struct {
unsigned long val;
} swp_entry_t;
- 内核通过位操作把
type和offset编码到val:- type: 表示属于哪个 swap 设备(
swap_info_struct.type)。 - offset: 表示在该 swap 设备中的页号。
- type: 表示属于哪个 swap 设备(
页表中的 PTE 如果指向 swap,而不是物理页帧,内容就是一个 swp_entry_t
Swap Cluster 和 Slot 概念
Slot(槽位)
定义: swap设备上的最小分配单位,对应一个页面大小的存储空间。
swap设备划分:
+--------+--------+--------+--------+--------+
| slot 0 | slot 1 | slot 2 | slot 3 | slot 4 | ...
+--------+--------+--------+--------+--------+
4KB 4KB 4KB 4KB 4KB
特点:
- 每个slot可以存储一个内存页(通常4KB)
- slot编号从0开始到last_page
- swap_map[i]记录slot i的使用状态
Cluster(簇)
定义: 多个连续的slot组成一个cluster,是swap分配的优化单元。
Cluster组织:
Cluster 0: [slot 0-255] 256个slot
Cluster 1: [slot 256-511] 256个slot
Cluster 2: [slot 512-767] 256个slot
...
默认大小: 通常是256个slot(即256个页面 = 1MB)
#define SWAPFILE_CLUSTER 256 // 定义一个cluster中slot个数
数据结构
swap_map - Slot使用状态
struct swap_info_struct {
...
unsigned char *swap_map; // 每个slot一个字节
...
};
// swap_map[i]的值含义:
// 0 = slot空闲
// 1-127 = 被引用次数(共享页面)
// 128(0x80)= SWAP_HAS_CACHE,页面在swap cache中
// 255(0xFF)= SWAP_MAP_BAD,坏块
swap_cluster_info - Cluster管理
/*
* We use this to track usage of a cluster. A cluster is a block of swap disk
* space with SWAPFILE_CLUSTER pages long and naturally aligns in disk. All
* free clusters are organized into a list. We fetch an entry from the list to
* get a free cluster.
*
* The data field stores next cluster if the cluster is free or cluster usage
* counter otherwise. The flags field determines if a cluster is free. This is
* protected by swap_info_struct.lock.
*/
struct swap_cluster_info {
spinlock_t lock;
unsigned int data:24;
unsigned int flags:8;
};
// flags可能的值:
#define CLUSTER_FLAG_FREE 1 // 簇完全空闲
#define CLUSTER_FLAG_NEXT_NULL 2 // 无下一个簇
#define CLUSTER_FLAG_HUGE 4 // 透明大页使用
cluster_info数组
struct swap_info_struct {
...
struct swap_cluster_info *cluster_info; // cluster数组
struct swap_cluster_list free_clusters; // 空闲cluster链表
struct swap_cluster_info *cluster_next; // 下一个可用cluster
...
};
Cluster设计目的
1. 提高空间局部性
// 传统方式:随机分配slot
内存页A → slot 5
内存页B → slot 203
内存页C → slot 47
// 磁盘随机访问,性能差
// Cluster方式:连续分配
进程X的页面 → cluster 0 [slot 0-255]
// 连续磁盘访问,性能好
2. 减少碎片
// 按cluster分配,同一进程的页面聚集在一起
// 回收时可以整个cluster标记为空闲
3. 支持并发
// 每个CPU可以绑定不同的cluster
CPU 0 → cluster 0
CPU 1 → cluster 1
CPU 2 → cluster 2
// 减少锁竞争
4. 优化SSD性能
// SSD有擦除块(erase block)的概念
// cluster对齐到SSD的erase block可以提高寿命
实际例子
场景:4GB swap设备
总容量: 4GB = 4,194,304 KB
Slot数量: 4,194,304 / 4 = 1,048,576个slot
Cluster数量: 1,048,576 / 256 = 4,096个cluster
数据结构大小:
swap_map: 1,048,576字节 ≈ 1MB
cluster_info: 4,096 × 8字节 = 32KB
分配示例
进程A启动,需要换出100个页面:
├─ 分配cluster 5 (slot 1280-1535)
├─ 使用slot 1280-1379 (100个)
└─ cluster_info[5].data = 记录已用slot数
进程B启动,需要换出200个页面:
├─ 分配cluster 6 (slot 1536-1791)
└─ 使用slot 1536-1735 (200个)
查看状态:
swap_map[1280-1379] = 1 (进程A的页面)
swap_map[1380-1535] = 0 (cluster 5剩余空闲)
swap_map[1536-1735] = 1 (进程B的页面)
cluster_info[5].flags = 部分使用
cluster_info[6].flags = 部分使用
Per-CPU Cluster优化
struct swap_info_struct {
...
struct swap_cluster_info *cluster_info; // 全局cluster数组
struct percpu_cluster __percpu *percpu_cluster; /* per cpu's swap location */
...
};
/*
* We assign a cluster to each CPU, so each CPU can allocate swap entry from
* its own cluster and swapout sequentially. The purpose is to optimize swapout
* throughput.
*/
struct percpu_cluster {
struct swap_cluster_info index; // 指向cluster_info中的某个cluster
unsigned int next; // 该cluster内的下一个slot位置
};
// 每个CPU使用独立的cluster,减少锁竞争
CPU 0 → percpu_cluster → cluster 10
CPU 1 → percpu_cluster → cluster 11
CPU 2 → percpu_cluster → cluster 12
总结
| 概念 | 大小 | 作用 | 管理结构 |
|---|---|---|---|
| Slot | 4KB | 存储一个页面 | swap_map[] |
| Cluster | 256×4KB=1MB | 连续slot组,优化分配 | cluster_info[] |
核心思想:
- Slot是物理存储单元
- Cluster是逻辑管理单元
- 通过cluster提高局部性、减少碎片、支持并发
- 类似文件系统中的"块"和"簇"的关系
swap_cluster_info与swap_header的关系
1. 存储位置不同
swap_header
- 存储在磁盘/文件的第一页
- 静态元数据,持久化存储
- 设备离线时仍然存在
swap_info_struct
- 存储在内核内存中
- 动态运行时数据
- 只在swapon后存在,swapoff后释放
2. 生命周期
mkswap /dev/sda2
└─> 写入swap_header到磁盘 ✓
reboot (系统重启)
└─> swap_header仍在磁盘 ✓
└─> swap_info_struct不存在 ✗
swapon /dev/sda2
├─> 读取磁盘上的swap_header
├─> 创建swap_info_struct
└─> 添加到swap_info[]数组
3. 数据流转
swapon流程:
1. 打开swap设备
2. 读取第一页的swap_header
3. 验证magic字段
4. 分配swap_info_struct结构
5. 从header提取信息:
- max = header->info.last_page
- 读取header->info.badpages
- 记录UUID等
6. 初始化运行时数据:
- 分配swap_map位图
- 初始化cluster_info
7. 将swap_info_struct加入swap_info[]数组
关系示意图
磁盘/文件 内核内存
+------------------+ +--------------------+
| swap_header | | swap_info[0] ───┐ |
| - magic | ─读取─>| swap_info_struct | |
| - last_page | | - max (来自header)|
| - badpages | | - swap_map | |
| - uuid | | - flags | |
+------------------+ | - 运行时状态 | |
↓ +--------------------+
持久化存储 临时运行时数据
实际例子
# 前提:系统上次启动中,已经设置了swap分区或文件
# 系统启动时
ls /dev/sda2 # swap_header在磁盘 ✓
# swap_info_struct不存在 ✗
# 激活swap
swapon /dev/sda2
# 读取/dev/sda2第一页的swap_header
# 创建swap_info_struct
# swap_info[0] = &新创建的swap_info_struct
cat /proc/swaps
# Filename Type Size Used Priority
# /dev/sda2 partition 4194304 0 -2
# 这些信息来自swap_info_struct
# 再激活一个
swapon /swapfile
# swap_info[1] = &另一个swap_info_struct
# 停用
swapoff /dev/sda2
# 释放swap_info[0]
# 但/dev/sda2的swap_header仍在磁盘
总结
| 特性 | swap_header | swap_info_struct |
|---|---|---|
| 位置 | 磁盘/文件第一页 | 内核内存 |
| 数量 | 每个swap设备一个 | 每个活动swap一个 |
| 生命周期 | 持久化 | swapon到swapoff |
| 作用 | 设备标识和配置 | 运行时管理 |
| 关系 | 源数据 | 从header初始化 |
swap_header是静态蓝图,swap_info_struct是活动实例。
参考资料
- Professional Linux Kernel Architecture,Wolfgang Mauerer
- Linux内核深度解析,余华兵
- Linux设备驱动开发详解,宋宝华
- https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/tree/?h=v4.12

















 1245
1245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









