




操作的原子性
10个线程同时对count变量进行++,每个线程进行10万次++,理想情况的结果是100万,但最后的结果却是小于100万的。
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#define THREAD_COUNT 10
void *func(void *arg) {
volatile int *pcount = (int *)arg;
int i = 0;
for (i = 0; i < 100000; i++) {
(*pcount)++;
usleep(1);
}
}
int main() {
pthread_t tid[THREAD_COUNT] = {0};
int count = 0;
int i = 0;
for (i = 0; i < THREAD_COUNT; i++) {
pthread_create(&tid[i], NULL, func, &count);
}
for (i = 0; i < 100; i++) {
printf("count --> %d\n", count);
sleep(1);
}
for (i = 0; i < THREAD_COUNT; i++) {
pthread_join(tid[i], NULL);
}
}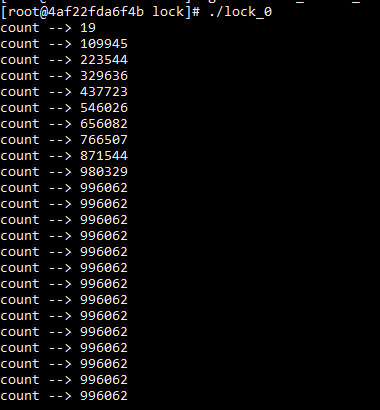
结果为什么小于100万呢?因为i++并不是原子操作。
#include <stdio.h>
int i = 0;
// gcc -S 1_test_i++.c
int main(int argc, char **argv)
{
i++;
return 0;
}i++ 不是原子操作
i++ 汇编代码
movl i(%rip), %eax //把i从内存加载到寄存器
addl $1, %eax //把寄存器的值加1
movl %eax, i(%rip) //把寄存器的值写回内存多个线程同时进行count++,大部分时间是线程1的三条指令执行完,线程2执行
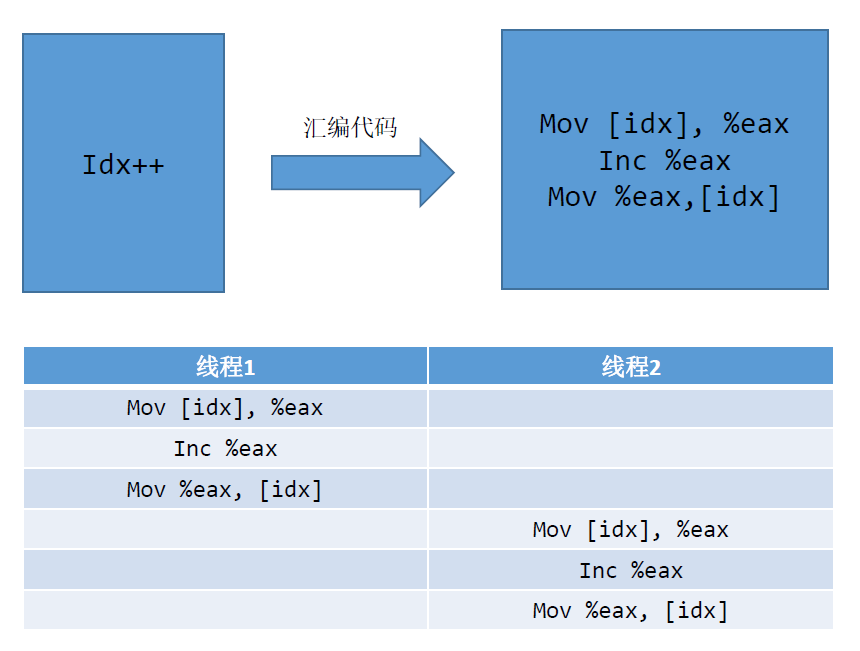
但有时候会是线程1的第一条或者前两条指令执行,再试线程2执行,最后又是线程1的第三条指令执行, 这样就会造成最后的结果小于100万。
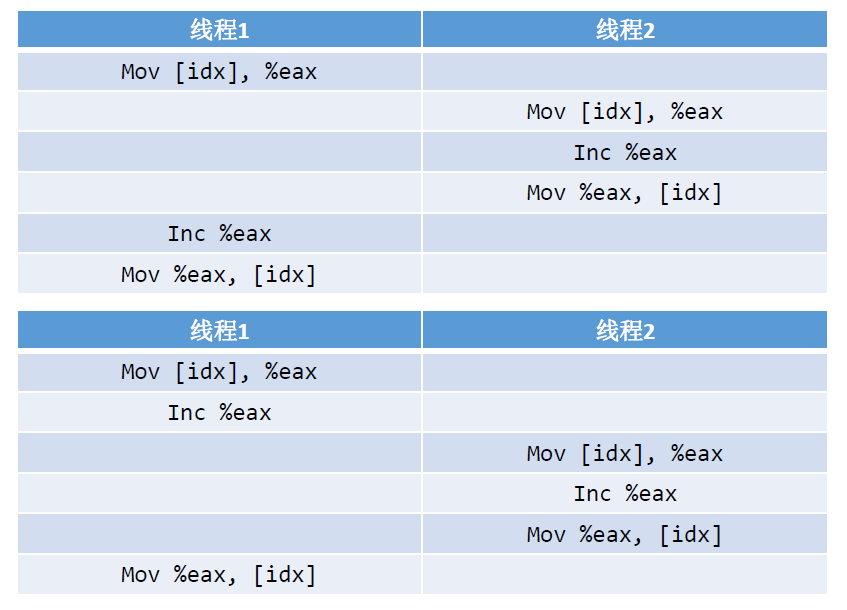
这样就会造成线程不安全,要解决这个问题,就需要加锁或者使用原子操作。
互斥锁 mutex
如果获取不到锁,让出CPU,将线程加入等待队列。
任务耗时比上下文切换要长,可以使用mutex。
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#define THREAD_COUNT 10
pthread_mutex_t mutex;
void *func(void *arg) {
int *pcount = (int *)arg;
int i = 0;
for (i = 0; i < 100000; i++) {
pthread_mutex_lock(&mutex);
(*pcount)++;
pthread_mutex_unlock(&mutex);
usleep(1);
}
}
int main() {
pthread_t tid[THREAD_COUNT] = {0};
int count = 0;
pthread_mutex_init(&mutex, NULL);
int i = 0;
for (i = 0; i < THREAD_COUNT; i++) {
pthread_create(&tid[i], NULL, func, &count);
}
for (i = 0; i < 100; i++) {
printf("count --> %d\n", count);
sleep(1);
}
for (i = 0; i < THREAD_COUNT; i++) {
pthread_join(tid[i], NULL);
}
}
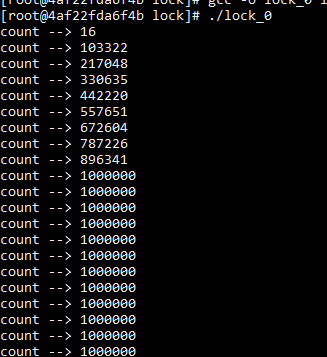
自旋锁spinlock
如果获取不到锁,则继续死循环检查锁的状态,如果是lock状态,则继续死循环,否则上锁,结束死循环。
(1)任务不能存在阻塞 (2)任务耗时短,几条指令
PTHREAD_PROCESS_SHARED, 表示fork出来的进程可以共用。
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#define THREAD_COUNT 10
pthread_spinlock_t spinlock;
void *func(void *arg) {
int *pcount = (int *)arg;
int i = 0;
for (i = 0; i < 100000; i++) {
pthread_spin_lock(&spinlock);
(*pcount)++;
pthread_spin_unlock(&spinlock);
usleep(1);
}
}
int main() {
pthread_t tid[THREAD_COUNT] = {0};
int count = 0;
pthread_spin_init(&spinlock, PTHREAD_PROCESS_PRIVATE);
int i = 0;
for (i = 0; i < THREAD_COUNT; i++) {
pthread_create(&tid[i], NULL, func, &count);
}
for (i = 0; i < 100; i++) {
printf("count --> %d\n", count);
sleep(1);
}
for (i = 0; i < THREAD_COUNT; i++) {
pthread_join(tid[i], NULL);
}
}
mutex和spinlock的使用场景比较
- 临界资源操作简单/没有系统调用,选择spinlock
- 操作复杂/有系统调用,选择mutex。
主要是看操作是比线程切换简单还是复杂。
读写锁
适用于读多写少的场景,一般不推荐使用读写锁
原子操作
使用汇编指令实现++i, 通过CPU指令将++操作在一条指令内实现。
#include <stdio.h>
#include <unistd.h>
#include <pthread.h>
#define THREAD_COUNT 10
int inc(int *value, int add) {
int old;
/*
xaddl
交换第一个操作数(目标操作数)与第二个操作数(源操作数),然后将这两个值的和加载到目标操作数。目标操作数可以是寄存器或内存位置;源操作数是寄存器。
此指令可以配合 LOCK 前缀使用。
TEMP SRC + DEST
SRC DEST
DEST TEMP
*/
__asm__ volatile (
"lock; xaddl %2, %1;" // lock表示锁住CPU操作内存的总线,%2代表add %1代表*value
: "=a" (old) // output old=eax
: "m" (*value), "a" (add) // input m是原始内存,将add值放入eax
: "cc", "memory"
);
return old;
}
void *func(void *arg) {
int *pcount = (int *)arg;
int i = 0;
for (i = 0; i < 100000; i++) {
inc(pcount, 1);
usleep(1);
}
}
int main() {
pthread_t tid[THREAD_COUNT] = {0};
int count = 0;
int i = 0;
for (i = 0; i < THREAD_COUNT; i++) {
pthread_create(&tid[i], NULL, func, &count);
}
for (i = 0; i < 100; i++) {
printf("count --> %d\n", count);
sleep(1);
}
for (i = 0; i < THREAD_COUNT; i++) {
pthread_join(tid[i], NULL);
}
}
lock锁的是CPU操作内存的总线
原子操作需要CPU指令集支持才行。
CAS(Compare and Swap)
CAS比较并交换,是原子操作的一种,先对比再赋值
Compare And Swap
if (a == b) {
a = c;
}
cmpxchg(a, b, c)
bool CAS( int * pAddr, int nExpected, int nNew )
atomically {
if ( *pAddr == nExpected ) {
*pAddr = nNew ;
return true ;
}
return false ;
}具体汇编代码实现,可以参考zmq无锁队列中cas实现。

原子操作实现的方式
- gcc、g++编译器提供了一组原子操作api;
- C++11也提供了一组原子操作api;
- 也可以用汇编来实现
总结
对于复杂的情况,包括读文件、socket操作,系统调用,可以使用mutex;
操作比较简单,原子操作不支持的,可以使用spinlock;
如果CPU指令集支持,可以使用原子操作。
线程切换,消耗资源,代价比较大,体现在哪里?
如果只是mov寄存器,其实代价是很小的;线程切换,除了寄存器操作,还需要进行文件系统,虚拟内存的切换,所以代价比较大。
mutex, mutex_trylock, spinlock 锁的粒度依次减小。
mutex适合锁执行之间比较长的一段代码,粒度最大,比如锁整颗B+数或者红黑树。获取不到锁的话,会进行线程的切换;
mutex_trylock,尝试获取锁,立刻就返回,本身不进行线程的切换,在应用程序中通常会用一个while循环来驱动,但是因为是在应用层,有可能会有线程切换。
spinlock,是在内核中不断尝试获取锁,不进行线程切换,锁的粒度最小。锁住CPU, 底层核心代码实现是一个loop指令,不断检查条件是否满足,条件满足才返回。
锁粒度的大小怎么判断?
如果要锁的内容的执行时间,要比线程切换的代价大,就算是大粒度,可以使用mutex;如果锁的内容的执行时间很短,比如就几行代码,加入个队列这种,就算是小粒度,可以使用spinlock。
如果会发生死锁,无论使用mutex还是spinlock都不可以。
原子操作,粒度更小,需要看是否支持单条汇编指令。
rwlock,读写锁,适合读多写少的场景。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









